What does an analytics platform look like? We might imagine a large server with data and software used for a wide range of operational reporting, BI and data analysis. There may be development and test environments. But typically most users will be working in the same production environment, sharing the same software and computing resources.
The cost of infrastructure and the time required to deploy software and hardware changes dictated this arrangement. Today, cloud technology and scripted deployment of virtual infrastructure and software have removed these constraints by reducing costs and enabling rapid deployment of new environments. At the same time, DevOps and the digital transformation have driven the need to apply analytics in new and more agile ways.

Established view of the analytics platform or reconsider the platform
SAS defines an analytics platform as a software foundation engineered to generate insights from your data in any computing environment. It is built on a strategy of using analytical insights to drive business actions. And this platform supports every phase of the analytics life cycle – from data, to discovery, to deployment.
It’s a generic description that an organisation could use as a starting point when it considers the analytics platform from the perspective of enterprise architecture. Yet the definition also moves away from the monolithic type of platform we may be used to. We can then reimagine the platform as something more modular, open and distributed. What is essential is that it supports the analytics life cycle and drives business actions.
The platform reimagined
We can reimagine the analytics platform as something like this. This figure shows a number of environments that work together to support the analytics life cycle and the deployment of analytics into production.
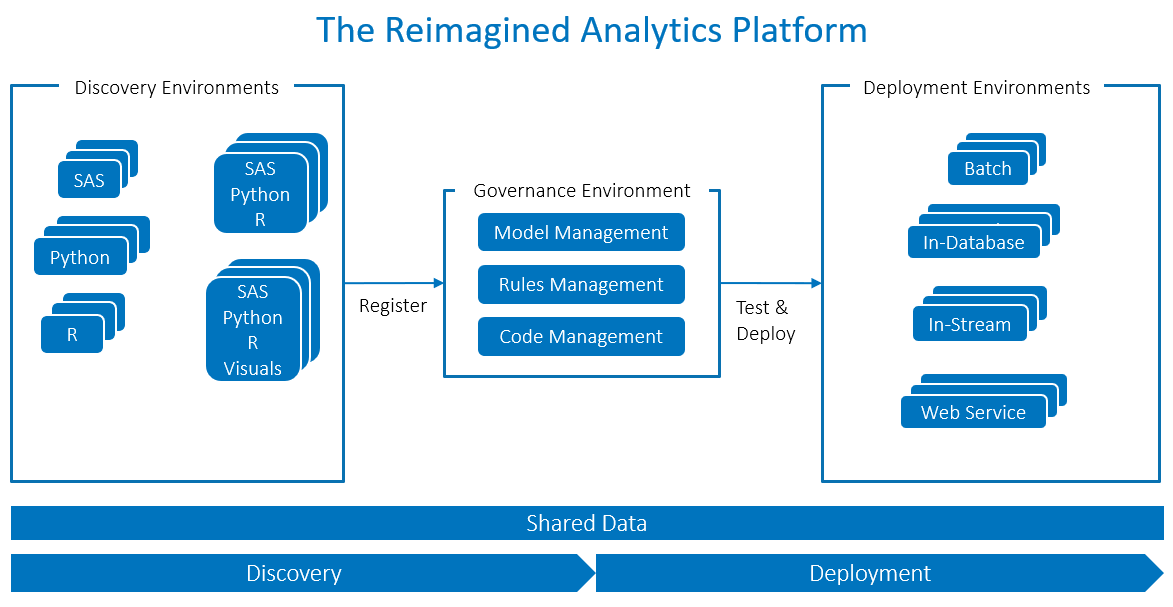
Data for all
Organizations usually apply data analytics to production data or at least a subset of it. I have sometimes had to explain to IT architects why this is the case and how data analytics is not like application development. You can’t create a reliable predictive model on old data in a test environment. Discovery and deployment environments need to have access to common data.
It is now common to consider data management separately from data preparation for analysis. Data management is an IT discipline to provide consistent and integrated and clean data that is refreshed on a regular basis. This happens outside the environments shown in the figure above. Despite best efforts, this is unlikely to be exactly the structure that each data analyst needs. So they will have to do more data preparation work themselves within each discovery environment to get it into the right form for a particular type of analysis.
Discovery – any way you choose
Data scientists use a range of coding languages, such as Python, R and SAS. Some analysts with more of a business orientation may prefer a purely visual point-and-click interface for data exploration and model building. Others may want to use code but manage it within a visual interface showing the analytic pipeline. The new, reimagined platform can accommodate all these user needs.
Using a particular coding or visual interface does not necessarily determine which analytical engine is used to run the code and algorithms. There are choices. For example, you can code in Python or R on a Jupyter Notebook and then have that code automatically converted to run in a high-performance in-memory analytical engine such as SAS Cloud Analytic Services (CAS). The same machine learning algorithms would be executed in the analytical engine no matter which user interface or coding language is used. The results would be exactly the same. Alternatively, you could use a code node in a SAS Model Studio pipeline to write Python code that gets executed in a Python runtime environment. Users can work in the interface or coding language that suits them. Then they can run the code where it is most appropriate.
Each user can choose
Rather than having to share an environment, each user can have his or her own. In the days of physical machine deployments, this would have been impractical. But it can now be done in seconds, thanks to containers. The IT administrator builds a standard container image with the required analytical software. Users can then spin up instances of this image whenever they need to. The container orchestration platform Kubernetes makes additional compute resources available as more containers are spun up. It then shuts them down again as the demand subsides.
Data scientists use a range of coding languages such as Python, R and SAS. Some analysts with more of a business orientation may prefer a purely visual point-and-click interface for data exploration and model building. Share on XPerhaps you want to try out something a bit different. Maybe a new version of the software or a different tool. That’s fine so long as you get your IT administrator to package the software in a new container image. With scripted deployment of software, this is a lot easier and faster than manual installation. And there is no risk of affecting an existing configuration as it’s a fresh new implementation in an isolated container environment. You and your colleagues can get access to new versions and tools soon after they are released.
Let’s consider the SAS definition of the analytics platform: An analytics platform is a software foundation that's engineered to generate insights from your data in any computing environment. Share on XGovernance – keeping control
The data scientist will typically produce an analytical model together with some score code. If it is an effective model, it will need to be put into production, and you need to properly govern and control this process. Some organisations may have hundreds or thousands of models so keeping track of them is critical for business performance, customer experience and possibly regulatory requirements.
Organizations need to register models and score code in a model management system that records the author of the model, the model attributes and the model test results. The system also needs to control the process of registration and deployment of the model through a workflow.
Analysts sometimes incorporate models into a decision flow with business rules. For example, a loan decisioning process may use a combination of eligibility rules with some further rules for determining what kind of model should be run. Changes to the rules will have a material impact on the results. So the system must also manage and govern these rules.
The analytical life cycle, DevOps and ModelOps
So far, we have looked at the experience of a data scientist developing a model in the discovery phase of the analytical life cycle. But in parallel with this, an application developer may be creating a web or mobile app that will utilise the model. These two processes are different but at some point, they converge. The application developer will write some code that calls the model and uses the results. Developers need to store and manage this code in a repository such as GitHub. The combined application and model will go through a process of testing before deployment to a production environment.
A common approach is to package the model and app in a container, test it and then move the entire container into production. Note that this container is not the same as the type used in the discovery environments. The container for DevOps contains only the software, code and model needed to do one specific thing. It is lightweight and easily deployable. After the initial deployment, you may require regular updates of the model so that it continues to perform well on the latest data. You can automate this process with an orchestration tool such as Jenkins or Bamboo. Jared Dean gives a good account of this with his recommendation engine for SAS Communities, which automatically rebuilds and redeploys the model and code every day.
DevOps has streamlined the application development and deployment process through collaboration, orchestration and automation. ModelOps is the application of similar techniques to the life cycle of analytical models, from model inception in the lab through to deployment in production, scaling to meet demand and continual monitoring.
Deploy to many locations
We used to have to bring all the data into one central analytics platform in order to run analytic production processes, typically in batch jobs. This may still be appropriate in some cases. But moving data does have costs in terms of storage, processing and latency. With big data, the problems get amplified. Dave McCrory coined the term data gravity to describe data’s resistance to being moved and its attractive force, evident in the tendency for services and applications to move close to location of the data. We see this in the current trend to push analytics to where the data is. This could be:
- Data platform, e.g., Hadoop.
- Data stream, e.g., video.
- Web service, e.g., a recommendation engine.
In each of these cases, the analytical application is lightweight, such as the SAS Embedded Process, or a small application that can be deployed in a container.
Organisations are now deploying analytical models in trucks, on trains and on production line machinery. The sky’s the limit when you consider the potential for deploying on drones to monitor crops, inspect solar farms for maintenance, or help rescue people from fires and earthquakes. The reimagined analytics platform extends far beyond the analytics team and the data centre to deliver analytics wherever it is needed.
Thanks to my colleague Hans-Joachim Edert for contributions to this article.
