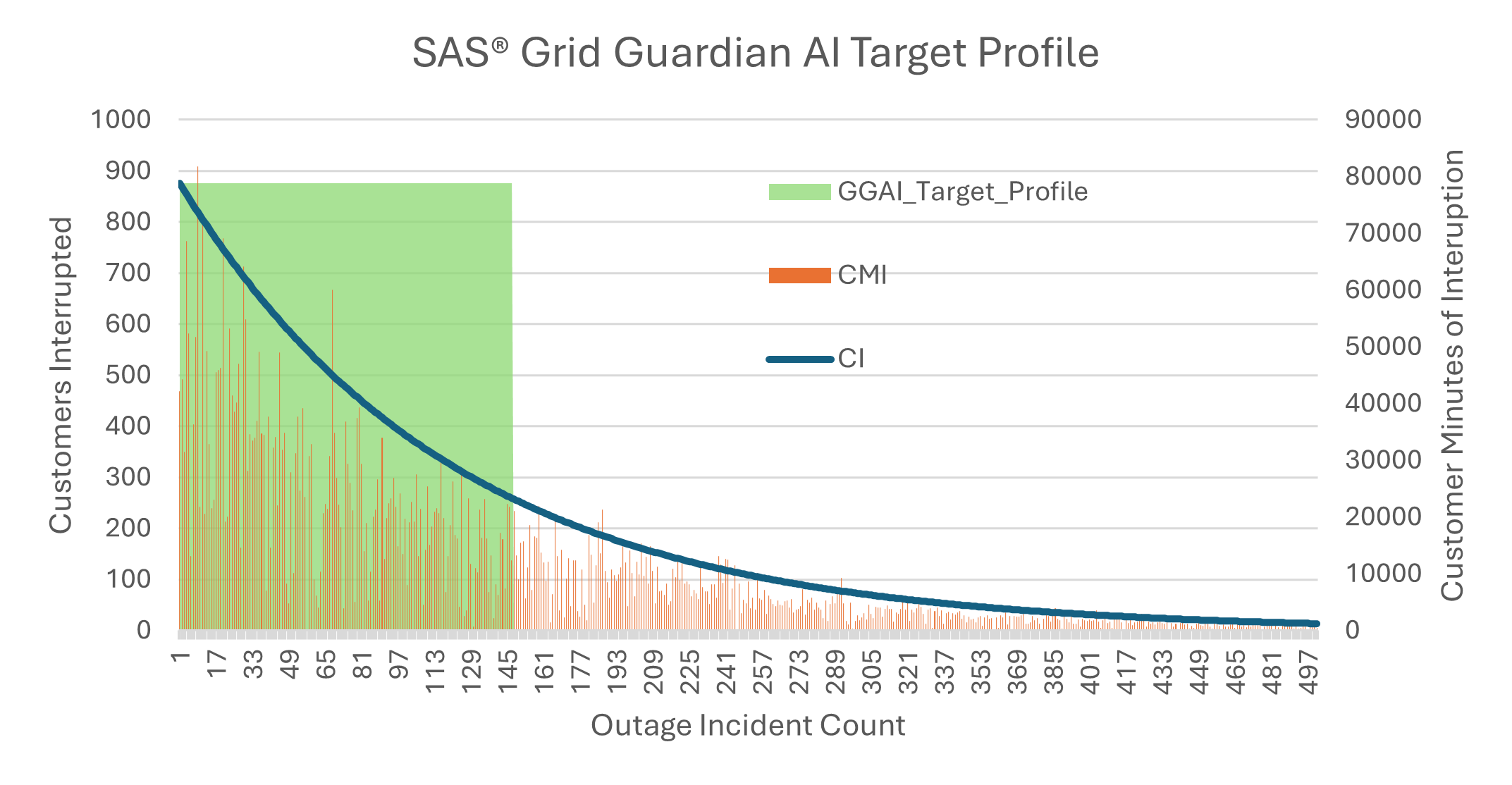
Leveraging the long-tailed nature of power outage impacts as a targeted approach for condition-based maintenance of the overhead distribution grid

As populations around the world the U.S. continue to grow, both condensing in urban areas and sprawling in more rural areas, the importance of a functioning distribution network for utilities grows proportionally. The complexity and interconnected nature of say, the electric distribution network, is already staggering; one can hardly imagine