クラウドにおける AI と分析の環境への影響の調査
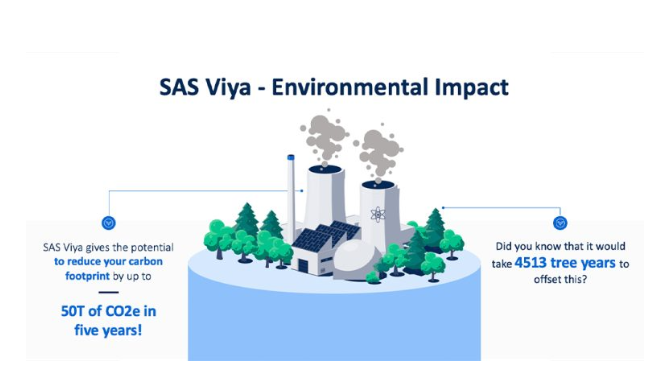
SASクラウドエコノミクスおよびビジネスバリューチームのSpiros PotamitisとFrancesco Raininiがこの記事の執筆に協力しました。2023年11月16日に公開された英語の記事を翻訳しております。 クラウド コンピューティングは数え切れないほど多くの業界のバックボーンとなり、組織が分析、機械学習、AI の力を活用して洞察とイノベーションを実現できるよう支援しています。 クラウドコンピューティングの急速な拡大により、クラウドは大きな二酸化炭素排出量を生み出すようになりました。背景として、クラウドは世界の二酸化炭素排出量の最大 4%を占めると計算されており、これは航空業界が排出する量よりも多いと考えられています。 これに対して何ができるでしょうか? オンプレミスの展開についてはどうでしょうか? クラウドとオンプレミスの議論に関しては、大手市場調査会社である IDC は、コンピューティングリソースの集約効率が高いため、オンプレミスと比較してクラウドの方が環境に優しい選択肢であると主張しています。したがって、AI と分析のワークロードをクラウドに移行するのが環境にとって最善の方法であると言われています。 クラウドでの効率を向上できる組織が増えれば、累積的な影響を考慮すると、小さな改善でも大きな違いを生む可能性があります。 SAS® Viya®と環境 SAS Viya は、 5 年間で最大 50 トンの CO2eの炭素排出量を削減する可能性があります。成長した木がこの量のCO2eを吸収するには 4,513 年かかると言われています。 カーボンフットプリントを楽しく探る 様々な要点を総合的に考慮し、Viya の潜在的な環境的利点を計算するために、私たちはGreen Algorithm Calculator を使用しました。これは、計算ワークロードの二酸化炭素排出量を推定して報告するツールです。計算を完了するために、さまざまな Azure Cloud アーキテクチャにわたる 1,500 を超えるテストを含むFuturum ベンチマーク調査の数値を使用しました。この調査では、Viya がオープンソースや主要な代替手段と比較して平均で 30 倍高速であることが示されています。 私たちは、大規模な組織に典型的なインフラストラクチャと分析のワークロードを想定しました。同時に、Futurum の調査で使用された技術的設定を反映しているため、計算に自信を持ってメリットの数値を適用できます。 グリーンアルゴリズム 計算機を使用して計算するには、次の手順に従います。 実行時間から始めます。50 人のデータ