前回の「ディープラーニングの判断根拠」ブログでは、PythonからSAS Viyaの機能を活用するためのパッケージであるSWATを使用した例を説明しましたが、今回は、以下2点に関してご紹介します。
- SAS ViyaのよりハイレベルなPython APIであるDLPyを使用した画像認識モデルの判断根拠情報
- 機械学習の判断根拠情報
1.SAS ViyaのよりハイレベルなPython APIであるDLPyを使用した画像認識モデルの判断根拠情報
この例では、複数のイルカとキリンの画像をSAS Viyaのディープラーニング(CNN)で学習させ、そのモデルに以下の画像を当てはめて、これがイルカなのか否かを判別するものです。
実際、この画像はイルカであると判定されたんですが。

SAS Viyaでは、その判断根拠となり得る情報の一つとして、入力画像のどこに着目したのかを以下の通り出力し、確認できるようになっています。
DLPyでは、get_feature_maps()メソッドでfeature mapを取得し、feature_map.display()で指定したレイヤーの内容を表示することができます。
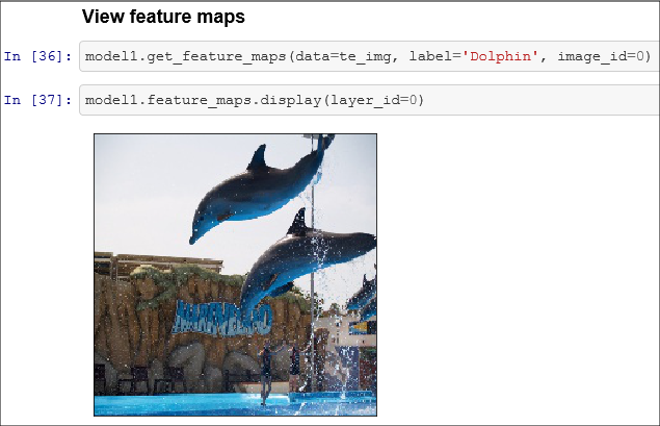
以下は、レイヤー1のfeature mapです。

以下は、レイヤー18のfeature mapです。

白色の濃淡で、判別に影響を与えている箇所を確認することができます。
さらに、SAS Viyaでは、画像認識モデルの判断根拠情報を可視化する手法の一つである、Grad-CAMと同様に、画像の何処に着目したのかを、カラフルなヒートマップとして出力し、確認することもできるようになっています。
しかも、heat_map_analysis()メソッドを使用して、以下の通り、たった1行書くだけでです。
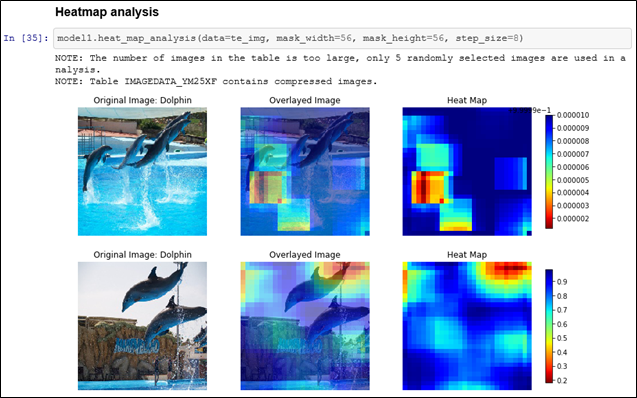
青、緑、赤の濃淡で、判別に影響を与えている箇所を確認することができます。
DLPyの詳細に関しては、以下をご覧ください。
https://github.com/sassoftware/python-dlpy
2.機械学習の判断根拠情報
もちろんディープラーニングだけではなく、従来からの機械学習のモデルによって導き出された予測や判断に関しても、それがなぜ正しいと言えるのか、具体的に言えば、なぜAさんはこの商品を買ってくれそうだと判断されたのか、なぜこの取引データは疑わしいと判断されたのか、を説明する必要性があるわけです。特に説明責任が求められるような業務要件においては、
ということでSAS Viyaの次期版には機械学習の判断根拠情報、モデル内容を説明するための機能が実装される予定です。
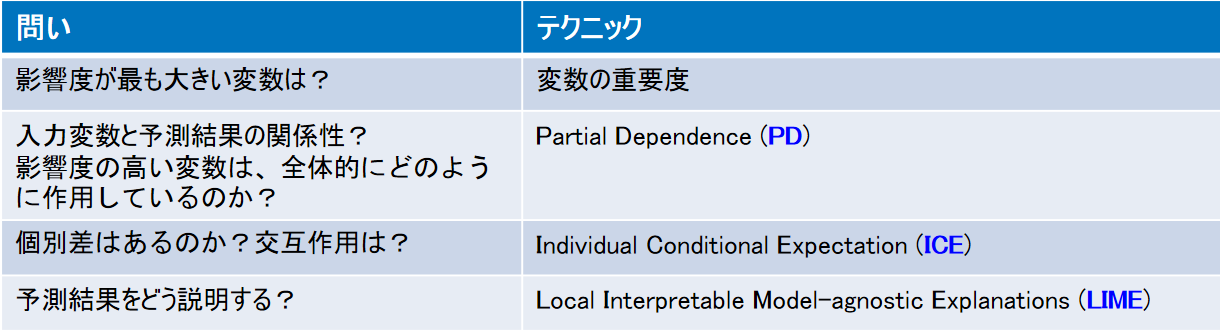
まず、影響度が最も高い変数は、という問いに対しては、従来からの変数の重要度で確認することができます。これをさらに一段掘り下げたものが、Partial Dependence (PD)です。
日本語では「部分従属」と言いますが。重要度の高い変数は、予測に対して、具体的にはどのように作用しているのかを知ることができます。
そしてこのPDを元にさらに一段掘り下げたものが、Individual Conditional Expectation (ICE)になります。
また、これらとは別に、なぜその予測結果に至ったのかを説明するテクニックとしてLocal Interpretable Model-agnostic Explanations (LIME)を活用することができます。
SAS Viyaベースの製品であるSAS Visual Data Mining and Machine Learning(VDMML)に含まれている、GUIベースの簡単マウス操作だけで精度の高い予測モデルを自動生成することが可能なModel Studioの画面内で、モデルごとのオプションとしてPD、ICE、LIMEのどれを出力させたいかをチェックオン/オフするだけで利用可能です。
この例で使用している学習用のデータは、説明変数としてプロバスケットボールリーグプレイヤーの身長や体重、バスケットまでの距離、ショットスタイル、ショット位置など、ターゲット変数としてショットが成功なら1、失敗なら0という0,1のフラグを含む項目で、このデータに基づきニューラルネットワークで作成されたモデル内容を解釈してみるものです。
まず、以下はPDの出力結果例です。
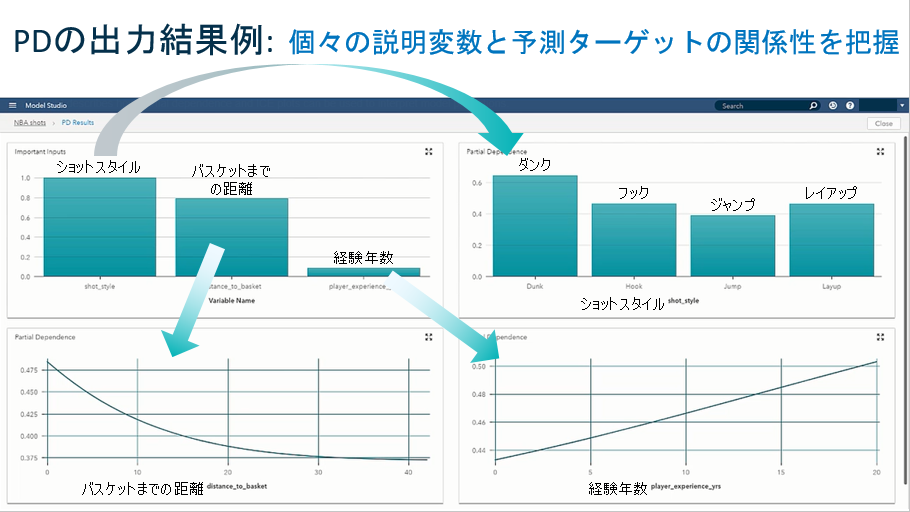
左上の棒グラフが、おなじみの変数の重要度です。ショットスタイルが最も影響度が高く、次が、バスケットまでの距離であることがわかります。残り3つのチャートがPDの結果です。
PDでは、個々の説明変数に対して平均的にはどのようにターゲットに依存しているのかの関係性が描かれていきます。
右上には、影響度が最も高いショットスタイルの内訳が表示されています。ダンクシュートが最も影響度が高く、逆に、ジャンプシュートが一番低いことがわります。
左下を見ると、バスケットまでの距離が遠くなればショット成功率が下がっていく、右下を見るとプレイ経験年数が長くなればショット成功率が高まるということがわかります。
次に、ICEの出力結果例です。ICEではPDを元に要因を把握することができます。
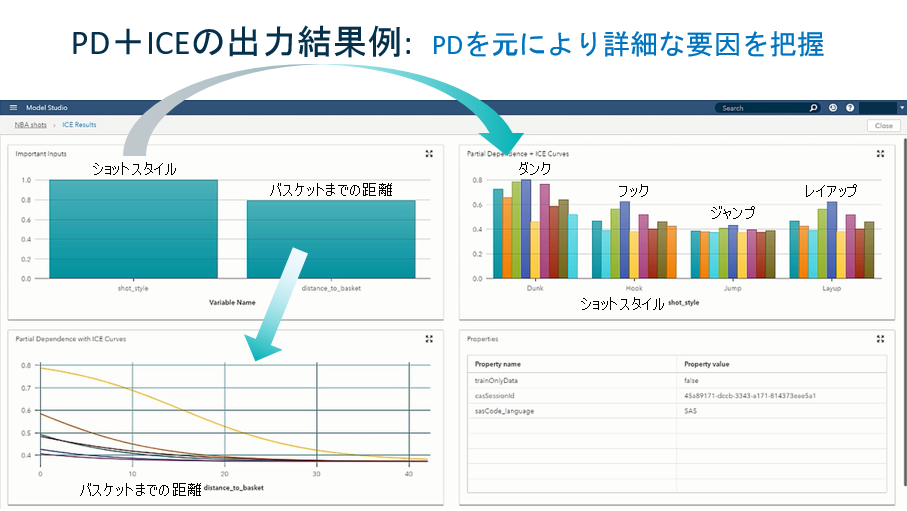
右上には、影響度が最も高いショットスタイルの内訳である、ダンク、フック、ジャンプ、レイアップ、ごとにさらにその内訳としてクラスタ別に影響度が表示されています。この例では9個のクラスタ別に違いを見ることができます。
左下では、バスケットまでの距離とターゲットの関係性をより詳細にクラスタ別に確認することができています。
最後にLIMEの出力結果例です。LIMEでは、なぜその予測結果に至ったのかを説明してくれます。
学習用データは同じバスケットボールリーグのデータを使用し、今度は勾配ブースティングでモデルを生成、そのモデルにテストデータを当てはめて予測を行った、結果の説明になります。
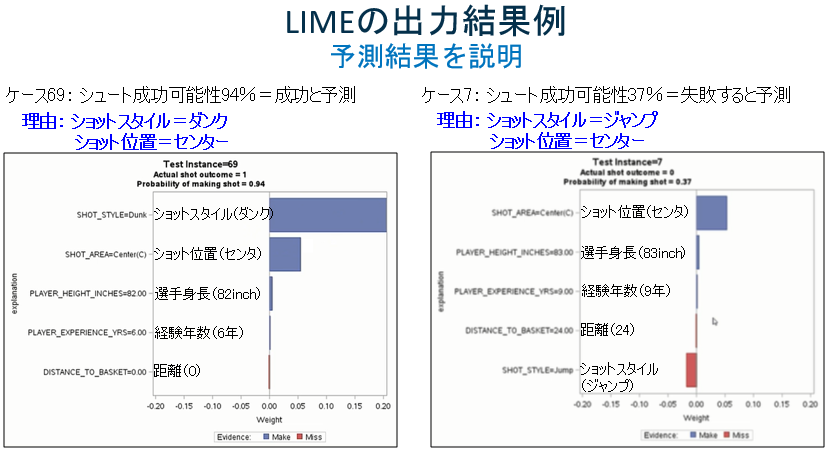
左側のケースでは、0.94の確率でショットは成功すると予測されています。理由としては、ショットスタイルがダンクであるということの影響度が非常に高く、かつ、ショット位置がセンターであるからだということです。
右側のケースは、ショットは失敗すると予測されています。なぜなら、ショット位置はセンターで良いのですが、ショットスタイルがジャンプショットなので不安定であるからだということが見て取れます。
PD、ICE、そしてLIMEによって齎されるこれら情報は、モデル内容の説明や結果の解釈だけにとどまらず、モデル精度を維持し、高めるために、モデルをどのように改良するべきなのかの示唆も与えてくれます。
