강화 학습(RL)은 다양한 분야에서 사용됩니다. 예를 들면, 로봇 공학, 산업, 자동화, 대화 생성, 헬스케어 치료 추천 사항, 주식 거래 및 컴퓨터 게임이 포함됩니다.
SAS Visual Data Mining and Machine Learning은 FQN(Fitted Q-Networks)과 함께 배치 강화 학습 기능을 한동안 제공했습니다. 흥미로운 소식은 SAS가 DQN(Deep Q-Networks)을 통해 온라인 "실시간" 강화 학습을 제공한다는 것입니다.

강화 학습이란 무엇인가?
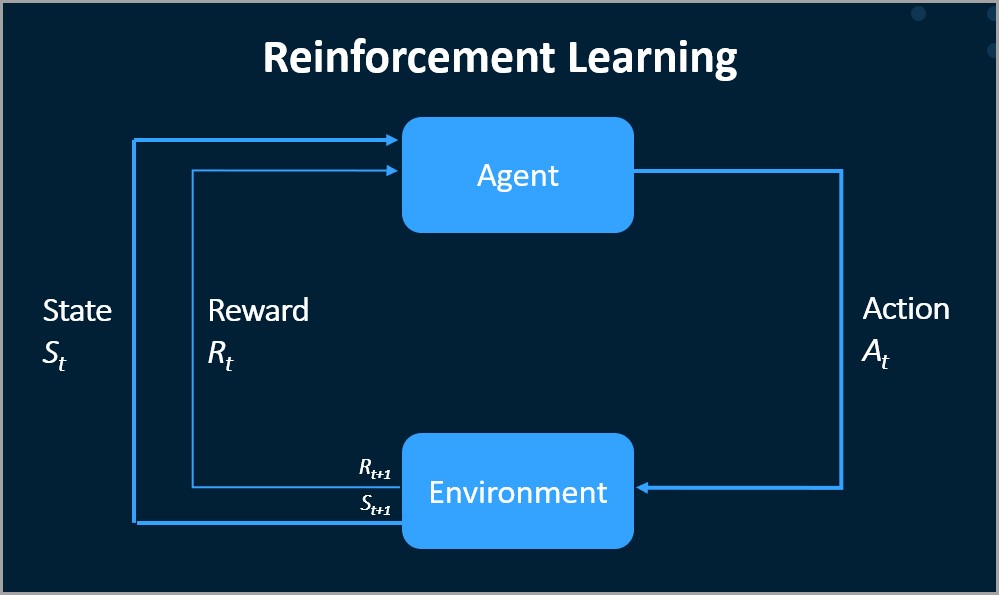
강화 학습은 머신러닝 모델 중의 하나입니다. 머신러닝의 종류에는 지도 학습, 비지도 학습, 강화 학습 등이 있을 수 있습니다. 지도 학습과 달리 강화 학습에는 감독자(Supervisor)가 없습니다. 대신 피드백 메커니즘 역할을 하는 보상(Reward) 신호(Signal)가 있습니다.
강화 학습의 목표(Objective)는 일련의 행동에 걸쳐 축적된 장기적 보상을 최대화하는 것입니다. 이것은 시행착오를 통해 반복적인 프로세스로 발생합니다. 시간/순서는 RL에서 중요합니다. 데이터는 순차적이며 동일하고 독립적으로 배포되지 않습니다.
아래 그림과 같이 환경(Environment)에서 작용하는 에이전트(Agent)가 있습니다. 에이전트의 각 행동(Action)에는 긍정적(Positive)이거나 부정적인(Negative) 보상/벌이 있으며 각 행동 후에 상태(State)가 변경됩니다. 따라서 에이전트는 이제 새로운 상태로 표시되고 새 작업을 선택할 수 있습니다.
대표적인 것이 자율주행차입니다. 자동차는 도로 등이 포함된 환경에 존재합니다. 자동차가 취할 수 있는 조치에는 전진, 정지, 우회전, 좌회전 등이 포함될 수 있습니다.

궁극적인 목표는 자율주행차가 모든 도로 규칙과 모든 안전 예방 조치에 따라 가능한 한 가장 빠른 방법으로 나를 집으로부터 내가 가장 좋아하는 레스토랑으로 데려다주는 것일 수 있습니다.
강화 학습 알고리즘의 예로는 Markov Decision Processes, Q 학습 알고리즘 및 SARSA(state-action-reward-state-action)가 있습니다. 강화 학습을 처리하는 기법에는 정책에 있을 수도 있고 없을 수도 있습니다.
- 오프 정책(Off-Policy) 알고리즘은 에이전트의 작업과 독립적입니다.
- 정책(On-Policy)기반 알고리즘은 탐색 단계를 포함하여 에이전트가 수행하는 정책의 Value를 학습합니다. on-policy 방법에서 업데이트에 사용되는 정책(대상 정책)과 수행할 작업을 선택하는 데 사용되는 정책(행동 정책) 은 하나이며 동일합니다.
Q-learning은 off-policy 강화 학습 방법의 한 예입니다.
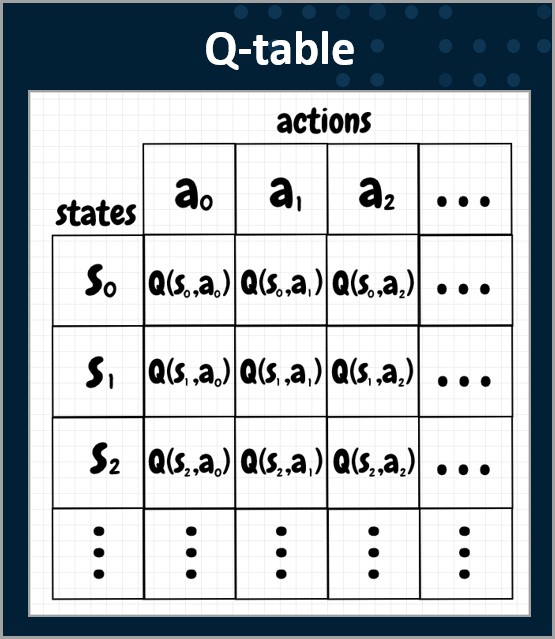
 SAS VDMML을 사용하면 두 가지 다른 Q-LEARNING 알고리즘을 사용하여 강화 학습을 수행할 수 있습니다. Q-LEARNING은 총 보상(Reward)을 최대화하는 정책(Policy)을 학습하려고 하며 Q 테이블에서 시작합니다. AQ 테이블은 가능한 모든 상태에 대한 모든 가능한 작업에 대한 Q 값의 행렬입니다. 테이블의 각 셀(각 Q 값)은 0으로 초기화됩니다. 각 에피소드 후에 Q 값이 업데이트되고 저장됩니다. Q는 품질을 나타냅니다. 높은 Q 값은 특정 상태(state)에서 특정 조치(Action)를 취하는 것이 좋습니다. 낮은 Q 값은 특정 상태(State)에서 특정 조치(Action)를 취하는 것이 좋지 않음을 나타냅니다. Q 테이블은 에이전트가 Q 값을 기반으로 최상의 조치(Action)를 선택할 수 있는 참조(Reference) 테이블이 됩니다.
SAS VDMML을 사용하면 두 가지 다른 Q-LEARNING 알고리즘을 사용하여 강화 학습을 수행할 수 있습니다. Q-LEARNING은 총 보상(Reward)을 최대화하는 정책(Policy)을 학습하려고 하며 Q 테이블에서 시작합니다. AQ 테이블은 가능한 모든 상태에 대한 모든 가능한 작업에 대한 Q 값의 행렬입니다. 테이블의 각 셀(각 Q 값)은 0으로 초기화됩니다. 각 에피소드 후에 Q 값이 업데이트되고 저장됩니다. Q는 품질을 나타냅니다. 높은 Q 값은 특정 상태(state)에서 특정 조치(Action)를 취하는 것이 좋습니다. 낮은 Q 값은 특정 상태(State)에서 특정 조치(Action)를 취하는 것이 좋지 않음을 나타냅니다. Q 테이블은 에이전트가 Q 값을 기반으로 최상의 조치(Action)를 선택할 수 있는 참조(Reference) 테이블이 됩니다.
Q-LEARNING은 일련의 단계에서 발생하는 반복적인 프로세스입니다. 다음은 Q-LEARNING 프로세스 단계의 예입니다.

Q-값은 다음과 같은 식을 사용하여 상태 s t 에서 행동(Action)를 취할 때 업데이트됩니다.
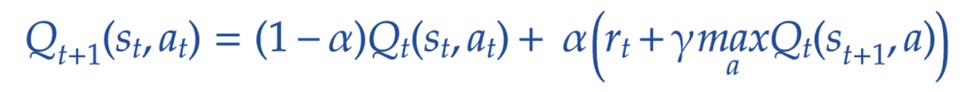
- α는 학습률입니다. 이전 값 대비한 새로운 값에 가중치를 둡니다.
- γ는 할인 계수(Discount Factor)로즉각적인 보상과 미래 보상을 조절합니다.
- ε은 Epsilon-greedy factor이며 Explore 또는 Exploit 여부를 결정하는 데 사용할 수 있습니다.
SAS VDMML 프로그래밍을 통한 강화 학습
SAS VDMML에서는 두 가지 Q-LEARNING 방법을 사용할 수 있습니다.
- Fitted Q network (FQN): 배치 방식
- Deep Q network (DQN): 온라인 실시간 방식
Deep Q network (DQN) 방법은 SAS VDMML 안정 릴리스 2020.1.3의 새로운 기능이며 rlTrainDqn CAS 작업을 통해 수행됩니다 .

둘 다 Model-free, Off-Policy 강화 학습(RL) 방법입니다.새로운 Deep Q network(DQN) 알고리즘은 몇 가지 면에서 Fitted Q Network(FQN) 알고리즘과 유사합니다.
- 둘 다 시스템의 State-Action 값 함수(Q-함수)를 근사화하기 위해 데이터에서 학습하도록 신경망을 훈련시킵니다.
- Q-함수는 데이터 세트의 각 상태-동작 쌍에 대한 Q-값을 반환합니다.
- 주어진 상태에 대해 Q를 최대화하는 작업을 선택하면 에이전트의 최적 정책이 생성됩니다.
DQN과 FQN은 아래와 같은 차이점도 있습니다.
Fitted-Q-Network:
- 배치RL 방법
- 훈련을 위해 고정된 경험 세트에 의존
- 환경은 현재 상태(Current state), 행동(Action), 보상(Reward) 및 다음 상태(Next State)를 포함하는 과거 데이터 세트로 표현됩니다.
Deep Q-Network:
- 온라인RL 방법
- URL을 통해 사용자 정의 환경을 지정할 수 있습니다.
- 에이전트는 실시간으로 환경과 직접 상호 작용하여 학습합니다.
- 상태를 렌더링(rendering) 할 수 있습니다
- 훈련된 정책을 사용하여 새로운 데이터를 스코어링 할 수 있습니다.
온라인 실시간 강화 학습을 사용하는 기능은 새로운 deep Q 네트워크의 큰 이점입니다! 예제를 따라 자신만의 Deep Q network를 만들려면 Susan Kahler의 블로그 를 참조하십시오.





