인공지능의 기반 기술 중 하나인 딥러닝은 눈부신 혁신을 거듭하고 있습니다. 텍스트 번역이나 이미지 분류 애플리케이션에 적합한 새로운 수준의 신경망이 개발되면서 사물인터넷(IoT)과 자율주행 관련 기술에도 활용되고 있는데요. 딥러닝 기술의 발전과 함께 객체 탐지 기법도 많은 주목을 받고 있습니다.
그렇다면 객체 탐지(Object Detection)는 무엇일까요? 객체 탐지는 이미지에서 관심 객체를 배경과 구분해 식별하는 자동화 기법으로, 컴퓨터 비전(Computer Vision) 기술의 하위 집합이기도 합니다. 아래와 같이 그림 1에는 전면에 있는 객체를 보여주는 두 개의 이미지가 있는데요. 왼쪽에는 새가, 오른쪽에는 개와 사람이 있습니다. 올바른 객체 탐지를 위해서는 경계박스(Bounding Box)를 설정해 객체를 나타내는 사물의 카테고리를 연관시켜야 합니다. 이 때 첨단 기법인 딥러닝(Deep Learning)이 활용됩니다.

객체 탐지에서 가장 빈번하게 직면하는 문제 중 하나는 바로 이미지에 따라 달라지는 전면 객체 수 일텐데요. 객체 탐지의 작동 원리를 이해하기 쉽게 설명할 수 있도록 이미지 당 하나의 객체만 있다고 가정해보겠습니다.
우선 한 이미지당 오직 한 개의 객체가 있는 경우에는 경계박스를 설정해 객체의 카테고리를 분류하는 일은 매우 쉽게 해결될 수 있을 텐데요. 경계박스는 4개의 숫자로 구성되어 있어 이를 통한 위치 학습은 자연스럽게 회귀(Regression) 문제로 모델링 될 것입니다.
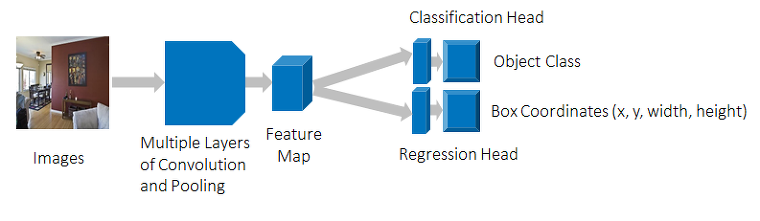
그림 2에서 설명해주는 콘볼루션 신경망(CNN; Convolutional Neural Network)은 컴퓨터 비전의 핵심 기술이기도 한데요. 콘볼루션 신경망 기술을 활용하면 제한된 객체 탐지에 대한 회귀와 분류가 가능합니다. 제한된 객체 탐지는 이미지 인식(Image Recognition), 핵심 포인트 탐지(Key Points Detection), 시맨틱 분할(Semantic Segmentation) 등 기존 컴퓨터 비전 업무와 마찬가지로 정해진 수의 대상을 처리하는데요. 대상의 수가 정해져 있을 경우 분류 또는 회귀 문제로 모델링하면 됩니다.
하지만 진정한 객체 탐지 기술은 2개 이상, 즉 N개의 객체를 탐지해 분류할 수 있어야 하겠죠. 위에서 설명한 콘볼루션 신경망은 더욱 많은 객체를 탐지하는 데 한계가 있습니다. 다수의 사각형 상자 위치와 크기를 가정해 콘볼루션 신경망을 변형한 후 이를 객체 분류(Object Classification)에 활용할 수는 있습니다. 이러한 사각형 상자들을 ‘윈도우(Window)’라고 부르는데요. 윈도우 가설은 이미지 상의 가능한 모든 위치와 크기를 포함해야 합니다. 각 창의 크기와 위치는 객체의 존재 여부에 따라 결정될 수 있고 객체가 있는 경우에는 그 범주도 결정할 수 있습니다.
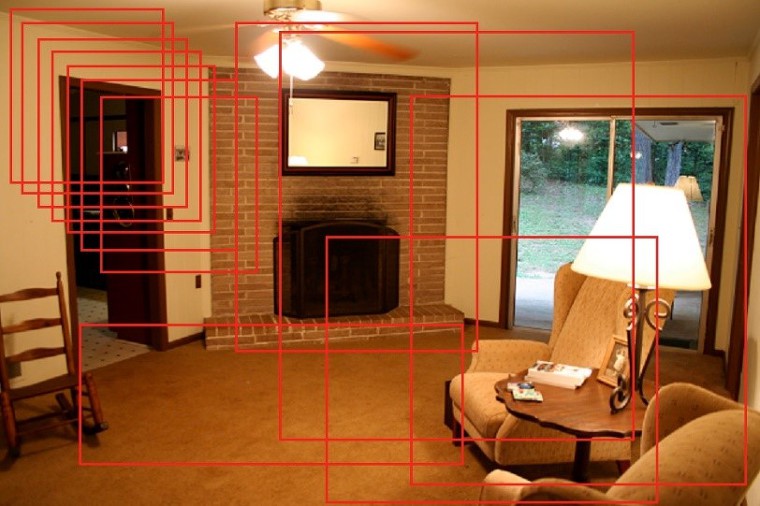
그림 3은 이와 같은 접근법으로 객체 탐지를 할 때 나타나는 윈도우의 일부를 보여줍니다. 각 이미지에는 서로 다른 개수의 픽셀이 있어 총 윈도우의 수도 커지는데요. 물론 셀 수 있는 정도의 수이기는 하지만 계산 상 비효율적입니다.
윈도우를 활용해 객체를 찾는 효율적인 방법은?
그렇다면 윈도우의 일부만을 활용해 객체 탐지를 효율적으로 할 수 있는 방법은 무엇일까요? 윈도우의 하위집합을 찾는 두 가지 있는데요. 이 방법들은 각기 다른 두 개의 객체 탐지 알고리즘 카테고리로 이어집니다.
첫 번째 알고리즘 카테고리는 먼저 영역 제안(Region Proposal)을 하는 것입니다. 객체를 포함할 가능성이 높은 영역을 선택적 탐색(Selective Search)같은 컴퓨터 비전 기술을 활용하거나 딥러닝 기반의 영역 제안 네트워크(RPN; Region Proposal Network)를 통해 선택하는 것인데요. 후보군의 윈도우 세트를 취합하면 회귀 모델과 분류 모델의 수를 공식화해 객체 탐지를 할 수 있습니다. 이 카테고리에는 Faster R-CNN[1], R_FCN[2] and FPN-FRCN[3] 같은 알고리즘이 포함됩니다. 이단계 방식(Two-Stage Methods)이라고 불리는 이 알고리즘들은 높은 정확도를 제공하지만 단일 단계 방식(Single-Stage Methods)보다는 처리 속도가 느립니다.
두 번째 알고리즘 카테고리는 정해진 위치와 정해진 크기의 객체만 찾는데요. 이 위치와 크기들은 대부분의 시나리오에 적용할 수 있도록 전략적으로 선택됩니다. 이 카테고리의 알고리즘은 보통 원본 이미지를 고정된 사이즈 그리드 영역으로 나누는데요. 알고리즘은 각 영역에 대해 형태와 크기가 미리 결정된 객체의 고정 개수를 예측합니다. 이 카테고리에 속하는 알고리즘은 단일 단계 방식(Single-Stage Methods)이라고 불리며 YOLO[4], SSD[5], RetinaNet[6]와 같은 알고리즘이 포함됩니다. 앞서 설명한 이단계 방식 보다는 정확도가 떨어지지만 빠른 처리가 가능합니다. 이 알고리즘 유형은 보통 실시간 탐지를 요구하는 애플리케이션에 활용됩니다.
이제 두 카테고리의 대표적인 객체 탐지 알고리즘에 대해 살펴보겠습니다.
단일 단계 방식의 객체 탐지 알고리즘, YOLO

YOLO(You Only Look Once)는 대표적인 단일 단계 방식의 객체 탐지 알고리즘입니다. YOLO 알고리즘은 원본 이미지를 동일한 크기의 그리드로 나눕니다. 각 그리드에 대해 그리드 중앙을 중심으로 미리 정의된 형태(predefined shape)으로 지정된 경계박스의 개수를 예측하고 이를 기반으로 신뢰도를 계산합니다. 이미지에 객체가 포함되어 있는지, 또는 배경만 단독으로 있는지에 대한 여부가 포함되겠죠. 높은 객체 신뢰도를 가진 위치를 선택해 객체 카테고리를 파악합니다.

미리 정의된 형태를 가진 경계박스 수를 ‘앵커 박스(Anchor Boxes)’라고 하는데요. 앵커 박스는 K-평균 알고리즘에 의한 데이터로부터 생성되며, 데이터 세트의 객체 크기와 형태에 대한 사전 정보를 확보합니다. 각각의 앵커는 각기 다른 크기와 형태의 객체를 탐지하도록 설계되어 있습니다. 그림 5를 보면 한 장소에 3개의 앵커가 있는데요. 이 중 붉은색 앵커 박스는 가운데에 있는 사람을 탐지합니다. 이 알고리즘은 앵커 박스와 유사한 크기의 개체를 탐지한다는 뜻인데요. 최종 예측은 앵커의 위치나 크기와는 차이가 있습니다. 이미지의 피쳐(Feature) 맵에서 확보한 최적화된 오프셋이 앵커 위치나 크기에 추가됩니다.
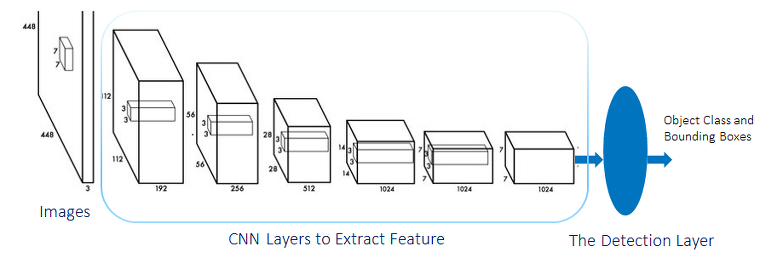
그림 6을 통해 YOLO 알고리즘의 아키텍처를 설명할 수 있는데요. 탐지 레이어는 많은 회귀 및 분류 최적화 도구를 포함하고 있으며 레이어의 개수는 앵커의 개수에 따라 결정됩니다.
이단계 방식의 객체 탐지 알고리즘, Faster RCNN
Faster RCNN은 이단계 방식의 객체 탐지 알고리즘인데요. 그림 7에서 Faster RCNN의 단계를 살펴보겠습니다. 이 알고리즘 이름에 ‘빠른(Faster)’이라는 단어가 포함되어 있지만 단일 단계 방식보다 빠른 처리가 된다는 뜻이 아니고 이전 버전이라 할 수 있는 RCNN 알고리즘과 Fast RCNN 알고리즘 보다 빠르다는 것을 뜻하는데요. 각 관심 영역(RoI; Region of Interest)에 대한 피쳐 추출의 계산을 공유하고 딥러닝 기반의 RPN을 도입해 구현할 수 있습니다.
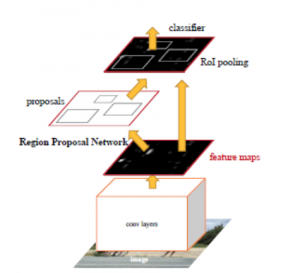
많은 CNN 레이어를 사용해 피쳐 맵을 추출하고 나면 RPN을 통해 개체를 포함하고 있을 가능성이 높은 윈도우가 다량으로 생성됩니다. 그런 다음 알고리즘은 각 윈도우에 있는 피쳐 맵을 검색하고, 고정 크기로 조정한 뒤(RoI 풀링) 클래스 확률과 해당 객체에 대한 더욱 정확한 경계박스를 예측합니다.
여기서 고려해야 할 점은 RPN이 윈도우를 생성하는 방법인데요. RPN은 YOLO와 마찬가지로 앵커 박스를 사용합니다. 하지만 YOLO 알고리즘과 다른 점은 앵커 박스가 데이터로부터 생성되는 것이 아니라 고정된 크기와 형태로 생성된다는 것인데요. 이 앵커 박스는 이미지를 보다 조밀하게 커버할 수 있습니다. RPN은 여러 객체 카테고리에 대한 분류 대신 윈도우의 객체 포함 유무에 대한 이진 분류(Binary Classification)만 수행합니다.
SAS 딥러닝(SAS Deep Learning)으로 객체 탐지 활용하기
이제 SAS 딥러닝(SAS Deep Learning)에서도 객체 탐지가 지원됩니다. 이에 대한 자세한 내용과 예시는 SAS 비주얼 데이터 마이닝 앤드 머신러닝(SAS Visual Data Mining and Machine Learning)에서 살펴보실 수 있습니다.
SAS 딥러닝은 프레임워크에서 생성된 모델이 실시간 프로세싱을 위한 SAS 이벤트 스트림 프로세싱(Event Stream Processing, ESP) 엔진에 추가적인 프로그래밍 없이 적용될 수 있다는 점에서 차별화됩니다. 현재 지원하고 있는 객체 탐지 알고리즘은 YOLOv1 및 YOLOv2으로, Faster RCNN과 레티나 네트워크(Retina Network) 지원 역시 가까운 시일 내에 이루어질 예정입니다.
SAS 딥러닝 프로그램에서 개발된 모델은 실시간 프로세싱의 세부사항에 대해 걱정할 필요 없이 SAS ESP에 간편하게 적용할 수 있습니다. 또한, SAS 딥러닝은 케라스(Keras) 타입의 파이썬(Phyton) 인터페이스인 DLPy를 제공하는데요. 이 오픈소스 프로젝트의 소스 코드 및 예시는 깃허브(GitHub)에서 확인하실 수 있습니다.
참고문헌:
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- R-FCN: Object Detection via Region-based Fully Convolutional Networks
- FPN-FRCN: Feature Pyramid Networks for Object Detection
- YOLO9000: Better, Faster, Stronger
- SSD: Single Shot Mutibox Detector
- Focal Loss for Dense Object Detection
- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast RCNN







3 Comments
책 한권 낼정도로 너무 잘쓰신거같아요 감사해요!
생소한 분석방법이라 분석하기 어려웠는데 잘 정리해주셔서 도움이 많이되었습니다. 감사합니다.
정말 이해하기 쉽게 써주셨네요. 감사합니다~