All Posts

Regulatory compliance is a principal driver for data quality and data governance initiatives in many organisations right now, particularly in the banking sector. It is interesting to observe how many financial institutions immediately demand longer timeframes to help get their 'house in order' in preparation for each directive. To the
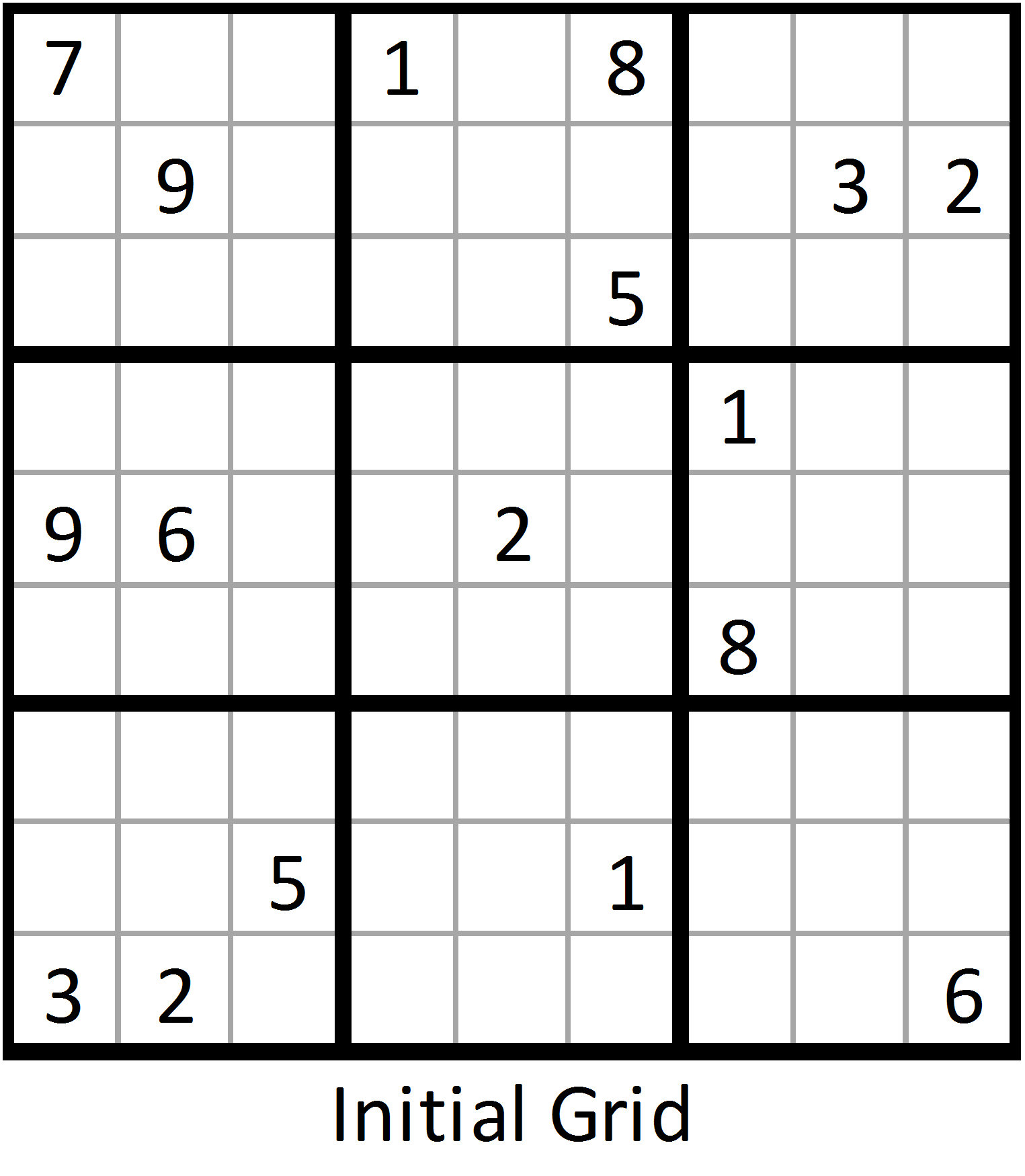

Part 1 of this topic presented a simple Sudoku solver. By treating Sudoku as an exact cover problem, the algorithm efficiently found solutions to simple Sudoku problems using basic logic. Unfortunately, the simple solver fails when presented with more difficult Sudoku problems. The puzzle on the right was obtained from


In many ways it’s open season for open data; open data is one of those phrases we hear a lot but it’s not always appreciated as having value. The fact that it’s openly available is seen by some as proof that there’s no value in the data – unlike, for


¿Ha oído el viejo dicho, "sus ojos son más grandes que su estómago"? Esta es otra forma de decir que su apetito puede causar que usted llene su plato con más comida de la que en realidad puede comer. Actualmente, eso es lo que ha pasado con la combinación de


It’s February, so love is in the air (or at least hearts, chocolate, and roses are lining the isles at the grocery store) in the weeks before Valentine’s Day. For the singles in the house, don’t stop here! The stats are in, and according to the http://www.pursuit-of-happiness.org/ , people who have

In this blog series, I am exploring if it’s wise to crowdsource data improvement, and if the power of the crowd can enable organizations to incorporate better enterprise data quality practices. In Part 1, I provided a high-level definition of crowdsourcing and explained that while it can be applied to a wide range of projects


In SAS, the order of variables in a data set is usually unimportant. However, occasionally SAS programmers need to reorder the variables in order to make a special graph or to simplify a computation. Reordering variables in the DATA step is slightly tricky. There are Knowledge Base articles about how


Staying competitive in a big data world means working fast and making decisions even faster. You need to assess conditions, approve access, stop transactions and reroute activities quickly so you can seize opportunities or prevent problems. With increasing data volumes from the Internet of Things (Cisco predicts that fifty billion


North Carolina is one of those lucky states that has a huge variety of scenic destinations, such as mountains, piedmont, coastal plains, beaches, and 'outer banks' islands. We have state parks in all of these areas, but can you guess which state park has been trending the most during the past


I stated in my previous blog about the value and benefits of volunteering that SAS Global Forum is designed to bring users with questions together with users with know-how. This goal is accomplished primarily in breakout and ePoster presentations. During his keynote address at SAS Global Forum 2014, Futurist Thornton

There are companies that have no data quality initiative, and truly do believe that if they see no data problem. In effect, they say that if it does not interfere with day-to-day business, then there is no data quality problem. From what I have seen in my consulting experience, it usually


We asked our partners at the Cornell Center for Hospitality Research to poll the research faculty at the Hotel School to understand their guidance about what to expect in 2015. We were also able to get a preview of what the faculty will be working on in terms of research

Over my last two posts, I suggested that our expectations for data quality morph over the duration of business processes, and it is only at a point that the process has completed that we can demand that all statically-applied data quality rules be observed. However, over the duration of the

I love to teach, but it took several years of teaching before I felt comfortable being in front of a class. And having taught for over 20 years, the fear of presenting in the classroom has passed, but what about presenting at professional meetings or in front of my peers?
A SAS/IML programmer asked a question on a discussion forum, which I paraphrase below: I've written a SAS/IML function that takes several arguments. Some of the arguments have default values. When the module is called, I want to compute some quantity, but I only want to compute it for the