When designing a SAS Grid Manager architecture, there is a requirement that has always been a critical component: a clustered file system. Over the years, vendors have released versions of these systems that are more robust and SAS has increased the minimum IO requirements, but the basic design has never changed—until now.
Any guess who the driver of this change could be? I heard a yellow elephant somewhere? Yes, Hadoop, but not only! File systems are now available that support SAS Grid computing in other shared-nothing storage architectures.
Let’s take a step back to understand how new file system options can facilitate your SAS Grid deployment. In this post, I’ll start with a quick review of storage architectures for SAS Grid Manager and what other vendors are doing. In a subsequent blog post, I’ll dive more specifically into the interaction of Hadoop and SAS Grid Manager.
Why a clustered file system
Why do we need a clustered file system? And why a traditional file share is not enough? What does clustered mean?
In short, the clustered file system is one of the most critical components of a SAS Grid deployment because it is where all the SAS data, configuration and sometimes the binaries are centrally located and shared across the machines. It feeds all the servers with the data that has to be processed, so the system you choose should meet these requirements:
- Be reliable
- Be fast
- Handle the concurrency
- Look the same from all machines
A good description of the requirements and possible candidates are found in this paper: A Survey of Shared File Systems: Determining the Best Choice for your Distributed Applications.
One of the conclusions from that paper is that clustered file systems provide the best performance. However, today, many customers are looking for options to move away from expensive SAN-based storage or at least to reduce the need and continued growth of their SAN infrastructure.
Benefits of new logical shared storage systems
The latest release of the paper includes one new IBM offering: File Placement Optimizer (GPFS FPO). As the paper says, “FPO is not a product distinct from Elastic Storage/GPFS, rather as of version 3.5 is an included feature that supports the ability to aggregate storage across multiple servers into one or more logical file systems across a distributed shared-nothing architecture.”
Aggregate storage—distributed—shared nothing. Sound familiar? Maybe HDFS?
GPFS/FPO can benefit SAS Grid deployments even without Hadoop. Here are some of the benefits you’ll see with GPFS/FPO and shared-nothing storage architectures:
- Cost savings thanks to a favorable licensing model.
- The ability to deploy SAS Grid Manager in a shared-nothing architecture reducing the need for expensive enterprise-class SAN infrastructure.
- It provides block level replication at the file system level allowing continuity of operations in light of a failed disk drive or a failed node.
- It supports full Posix file system semantics.
If we want to visualize the storage architecture a very high level, we could say that we are moving from environments built as in Figure 1 towards environments built as in Figure 2.
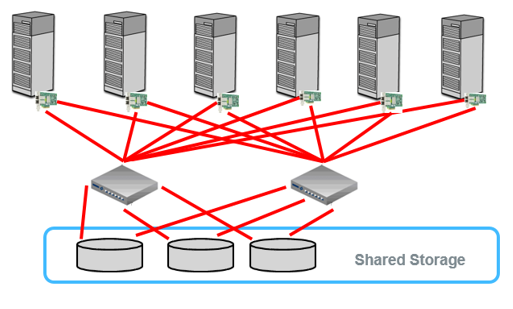
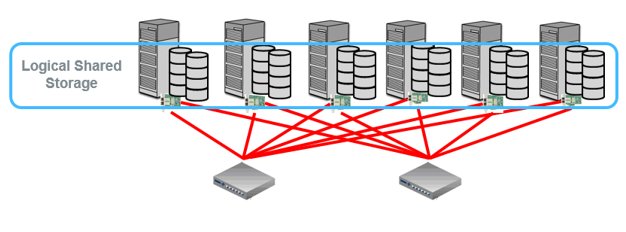
SAS Grid Manager and logical shared file storage
IBM supports this new kind of storage, but does it work as we require for SAS Grid Manager? SAS R&D tested it and the results are in the following white paper: SAS Grid Manager – A “Building Block” approach.
It is important to consider all the caveats that the paper describes. The most important points, in my opinion, are the following two, which I tried to depict in the above image:
- Ensure each node has a sufficient quantity of disks to meet SAS’ recommended IO throughput requirements based upon the number of cores plus the overhead needed to write replica blocks from other nodes in the environment.
- Ensure that sufficient network connectivity exists that replica blocks can be written to other nodes without throttling IO throughput.
In conclusion, with the correct configuration, this new kind of storage can provide cost savings and simplify your SAS Grid Manager architecture, but still requires proprietary software.
Is it possible to achieve the same benefits with Hadoop? If yes, are there any differences or further considerations? I will try to provide the answers in my next blog, so stay tuned!
Edoardo

1 Comment
SAS Federal - RRP,
at IRS there is a CFS built using Veritas.
Regards,
Chad