All Posts


Moving Average (MA) is a common indicator in stocks, securities and futures trading in financial markets to gauge momentum and confirm trends. MA is often used to smooth out short-term fluctuations and show long-term trends. But most MA indicators have big lags in signaling a changing trend. To be faster


Analytics-led innovation has become essential to respond to the rapidly evolving digital economy and associated consumer expectations. A preliminary reading of our Innovation at Scale study suggests that it is essential to access data across internal silos and organisational boundaries. Part of the solution is innovation spaces that encourage collaboration
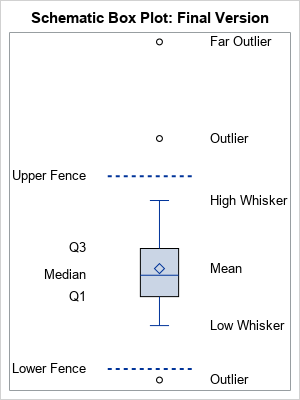

A SAS programmer asked an intriguing question on the SAS Support Communities: Can you use SAS to create a graph that shows how the elements in a box-and-whiskers plot relate to the data? The SAS documentation has several examples that explain how to read a box plot. One of the


There are many articles and blog posts about the benefits of quiet time and daydreaming. The concept sounds great, but also easier said than done. Creating the time and space for this "day dream" state can be difficult. I get it. I literally have to trap myself on a bus
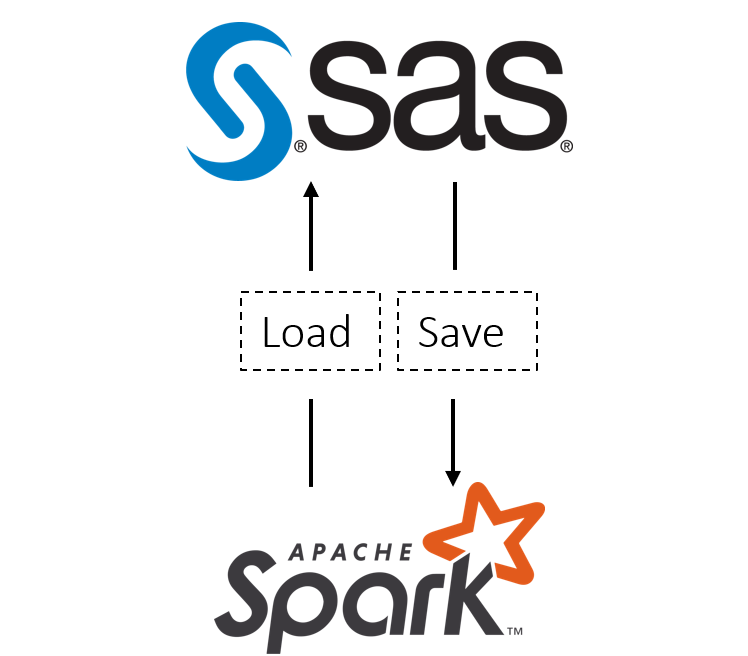

This article is not a tutorial on Hadoop, Spark, or big data. At the same time, no prerequisite knowledge of these technologies is required for understanding. We’ll give you enough background prior to diving into the details. In simplest terms, the Hadoop framework maintains the data and Spark controls and
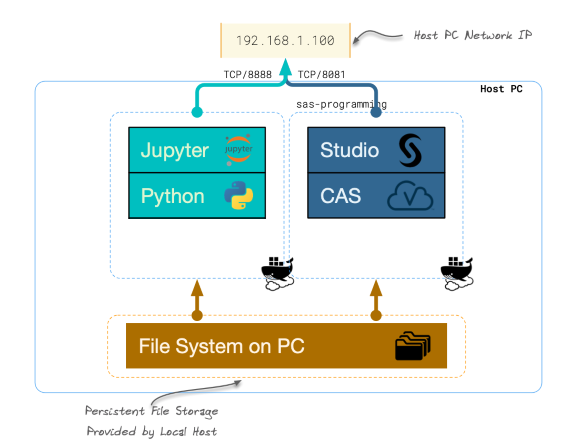

A simple example of how you can combine SAS and open-source technologies to solve real business issues.

I was born in a country (Brazil) where voting is mandatory. Most of my family still lives there, and now that I live in the US, they ask me about American politics all the time. One thing that often catches them by surprise is that not only is voting not


Summer is winding down, and cooler fall weather is just around the corner. You might soon be able to take a pleasant drive with the windows down, while enjoying the scenery. But where should you go? What are the most scenic roads for that drive? Read along to see a
Most SAS programmers know how to use PROC APPEND or the SET statement in DATA step to unconditionally append new observations to an existing data set. However, sometimes you need to scan the data to determine whether or not to append observations. In this situation, many SAS programmers choose one


Entre las prisas de los aeropuertos y visitar los clientes, mis colegas de EE. UU. y yo nos encontramos en Brasil con poco tiempo para prepararnos para las reuniones. Aunque la industria hotelera se está poniendo al día con las necesidades de los viajeros de negocios, que han existido durante


This summer the Accessibility and Applied Assistive Technology team at SAS launched a new course that teaches students with visual impairments how to independently analyze data, which is a critical skill that all students need for success in college and their careers. However, many students with visual impairments don’t have


Each week in August, the Work/Life Team has invited educational experts to address concerns parents have in the process of choosing a school. For our fourth and final blogpost in this series, we have invited our experts to respond to the following questions: What factors/issues might prompt a family to


IT managers see the potential for cost-cutting from transitioning application development to open source software (OSS). Today, companies can hire recent college graduates with skills in open source development and avail themselves of the free software. But is all that glitters really gold? Users groups and more formal workgroups are


David Loshin gives CIOs 4 suggestions for shaping successful digital transformation initiatives.


Editor’s note: This is the first article in a series by Conor Hogan, a Solutions Architect at SAS, on SAS and database and storage options on cloud technologies. This article covers the SAS offerings available to connect to and interact with the various database options available in Amazon Web Services.