지난 텍스트 분석 시리즈 1편에서는 텍스트 토픽을 분류하여 빠르게 인사이트를 확보하는 방법을 소개해드렸습니다. 이번에는 텍스트 데이터를 기반으로 고객의 행동을 예측하고, 예측 모델링의 성능을 개선하는 방법을 알아보겠습니다. 이 작업에는 SAS의 머신러닝 솔루션인 SAS Visual Data Mining & Machine Learning(VDMML)이 유용합니다.

지금 이 시간에도 수많은 데이터 분석가들은 모델이 높은 성능을 발휘하도록 다양한 노력을 하고 있습니다. 회귀분석, 의사결정트리와 같은 전통적인 예측 모델링 알고리즘을 비롯하여 그래디언부스팅, 랜덤포레스트, 딥러닝과 같은 새로운 머신러닝 예측 모형 알고리즘은 이러한 분석가들의 니즈가 낳은 학문적 노력의 결과입니다.
다양한 텍스트 데이터에서 텍스트를 생성한 주체의 성향과 행동에 대한 인사이트를 얻을 수 있다는 사실은 이제 모두가 알고 있습니다. 그런데 그 같은 인사이트는 어떻게 추출해야 할까요? 텍스트 마이닝이 중요한 이유입니다. 아울러 일반적인 데이터 마이닝(예측 모형 개발)에서도 텍스트 변수를 사용하여 모델의 예측력을 의미 있는 수준으로 향상시킬 수 있습니다.
보험 데이터를 이용한 예측모델 개발
지금부터 소개하는 예시는 가설 데이터입니다. 하지만, 어느 정도는 고객사의 실제 데이터를 기반으로 하고 있습니다. 보험회사는 사건에 대한 청구를 받으면, 보험 가입자의 편의를 위해 우선 지급을 합니다. 이후 해당 손실이 제3자의 책임으로 발생한 것을 확인하면 해당 지급금을 구상 청구하여 돌려받습니다.
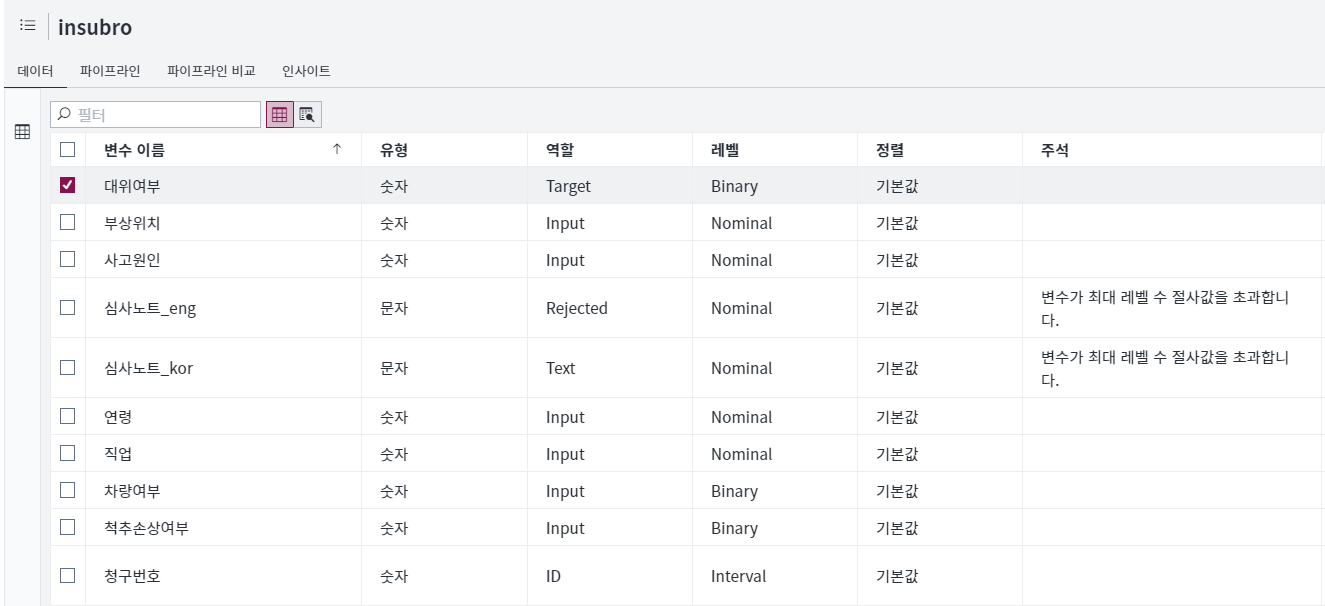
현재 청구된 보험 사고 건에 대한 대위변제 가능 여부를 예측하는 모델은 실무적으로나 재무적으로 보험회사에 중요한 정보를 제공할 수 있습니다. <그림1>을 보시면 분석을 위한 데이터를 import 후, 타깃 변수인 대위 여부를 역할 타깃으로 지정하고, 해당 사건에 대한 심사자의 심사평가노트는 텍스트 변수로 지정했습니다.
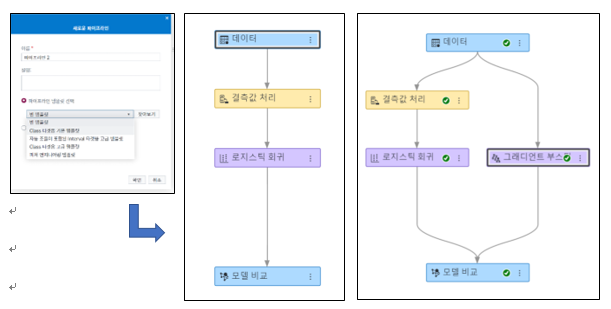
그런 다음 <그림2>처럼 파이프라인을 Class 타깃용 기본 템플릿을 생성하고, 그래디언부스팅 알고리즘을 추가했습니다.
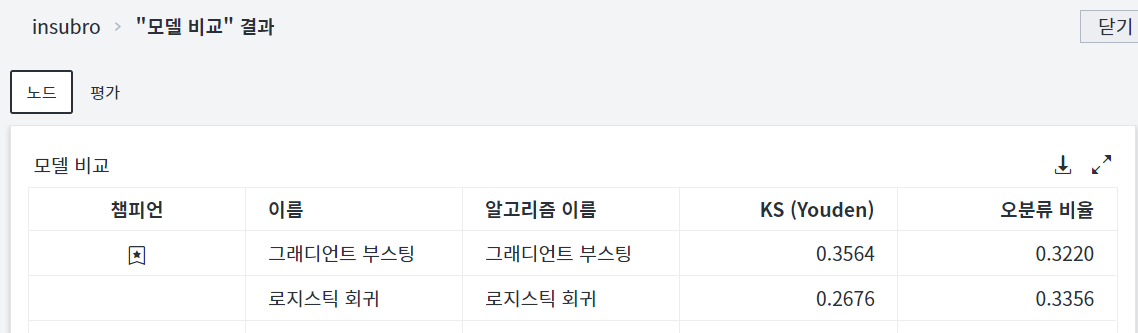
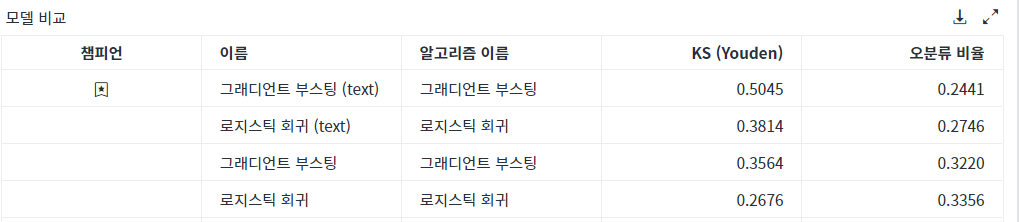
로지스틱 회귀와 그래디언트 부스팅 모델 결과는 <그림3>과 같습니다. 그래디언트 부스팅 모델이 회귀분석 대비 성능 지표가 우수하게 산출되었음을 확인할 수 있습니다.
텍스트 데이터를 추가한 예측모델 개발
기존의 모델에 텍스트 변수를 사용한 모델을 추가해보겠습니다. SAS의 머신러닝 솔루션인 Visual Data Mining & Machine Learning(이하, VDMML)의 텍스트 마이닝 노드는 보험청구 분석가의 메모 내용(텍스트 변수)을 예측모형의 변수로 사용할 수 있는 기능을 제공하는 노드입니다.
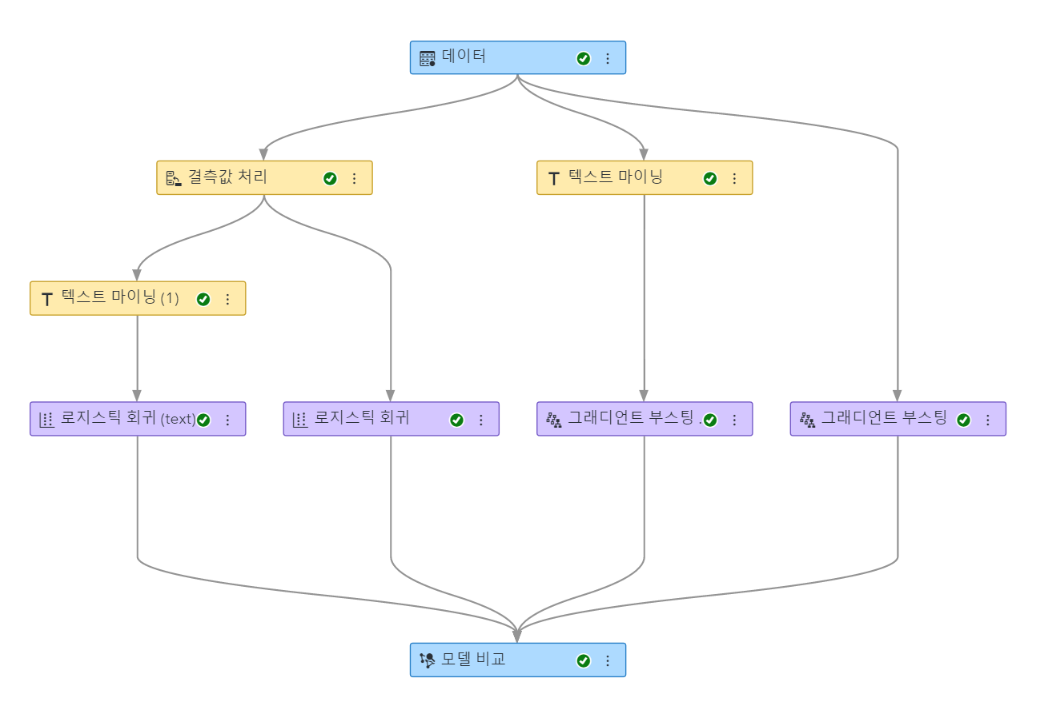
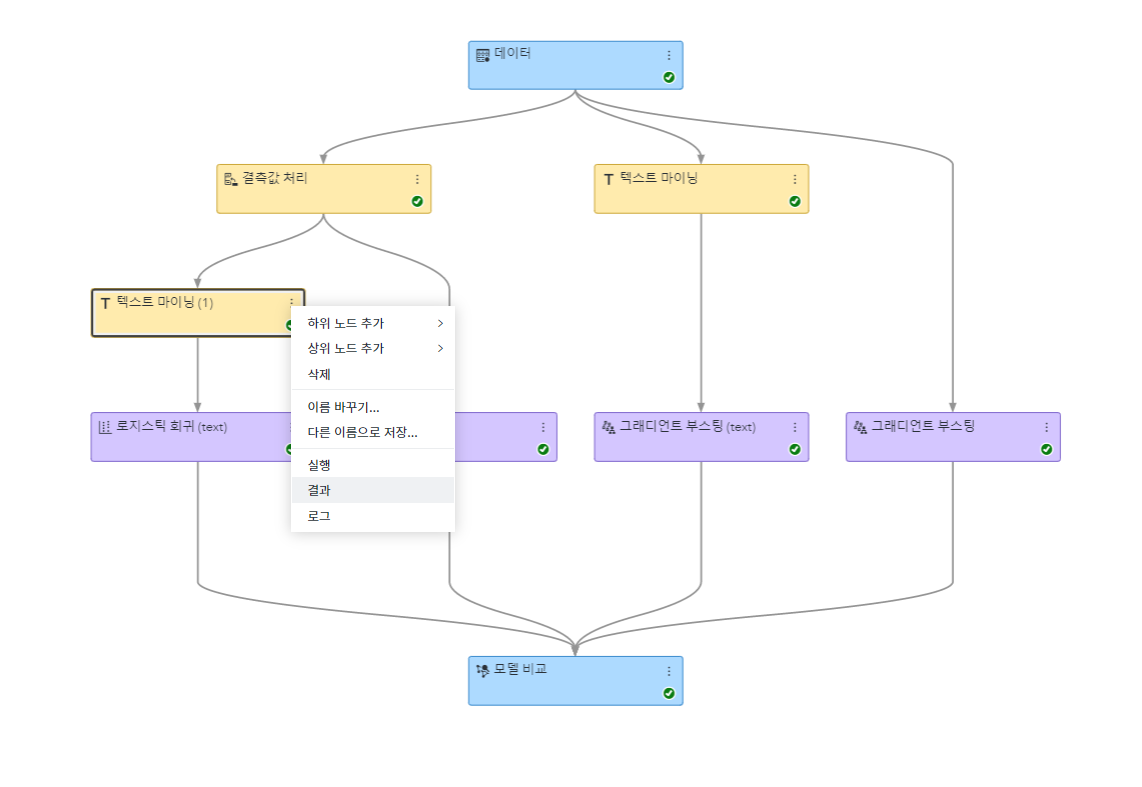
<그림4>는 로지스틱회귀 노드와 그래디언트 부스팅 위에 각각 텍스트마이닝 노드를 추가하여 모델을 생성한 것입니다.
해당 모델을 포함하여 전체 4개의 모델 결과 비교표를 산출해 보면 <그림5>에서 보시는 것처럼 텍스트 변수를 사용할 경우, 기존 모델보다 모델성능지표가 좋아지는 것을 확인할 수 있습니다.
텍스트 마이닝 노드의 작업내용을 보기 위해 <그림6>처럼 노드를 우 클릭하고, 결과 탭을 클릭합니다.
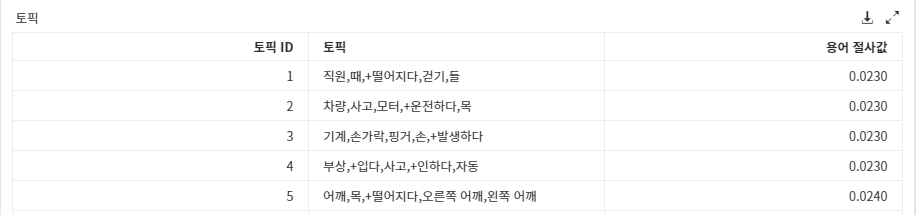
텍스트 마이닝 노드의 결과를 보면, <그림7>에서 보시는 것처럼 전체 2,946건의 사건 리뷰 메모가 5개의 토픽으로 분류된 것을 확인할 수 있습니다.
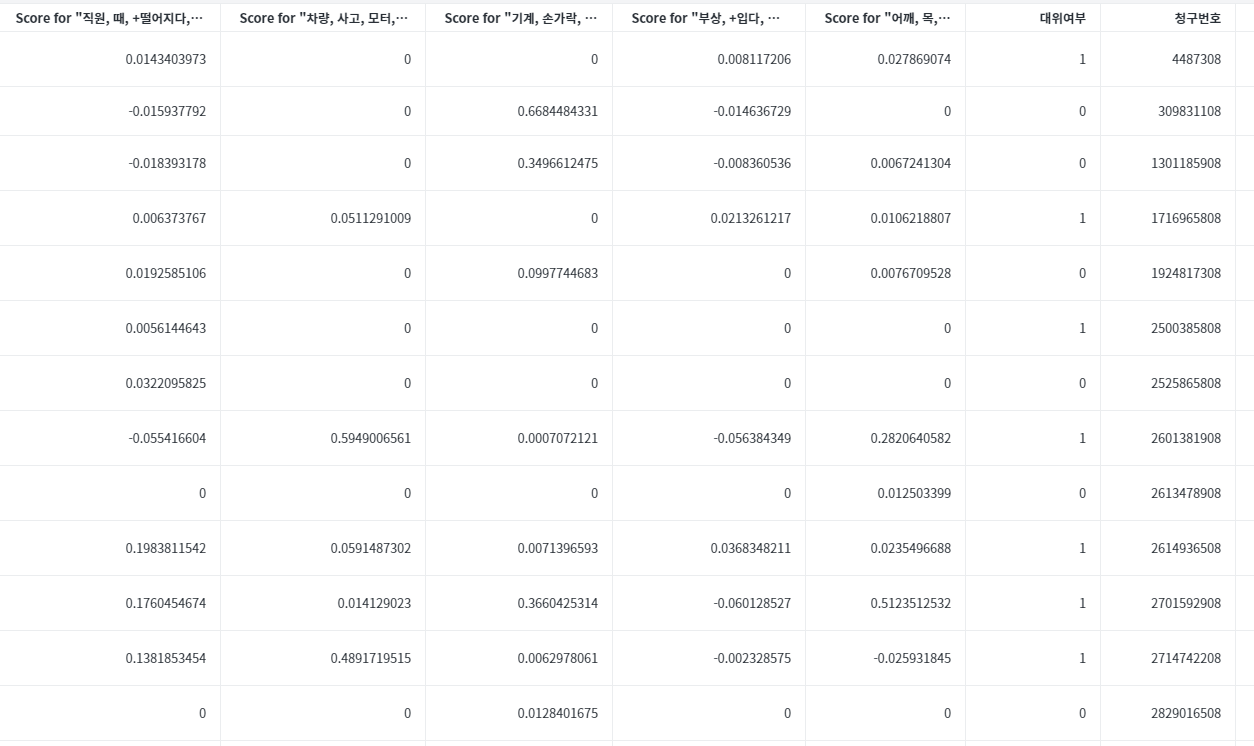
문서별 각 토픽의 가중치를 <그림8>처럼 구하고, 이를 예측 모형에 유의 변수로 사용함으로서 예측 모형의 성능이 증가하는 것을 확인할 수 있습니다. <그림8>의 토픽 가중치는 SVD(singular vector decomposition) 방법론을 이용하여 최종 목표 차원의 가중값으로 산출되었습니다. 문서별로 위의 5개의 토픽에 대한 가중치(관련성)가 산출되고, 이 값들이 변수로 사용되면서 텍스트 내용이 모델의 성능이 개선됩니다.
SAS VDMML과 텍스트 분석으로 고객 행동 예측
기업은 고객의 행동을 예측하고 거래의 성격을 미리 파악하기 위해 부단히 노력하고 있습니다. 기존에 사용하지 못하던 빅데이터로까지 데이터 분석의 범위를 확장하고 있으며, 고성능의 신규 예측 모형 알고리즘을 적용하여 고객의 행동을 예측하고 있습니다.
SAS VDMML 솔루션을 이용해보십시오. SAS VDMML은 별도의 프로그래밍을 할 필요 없이 마우스를 드래그 앤 클릭하는 방식으로, 어려운 알고리즘을 쉽게 사용할 수 있습니다. 아울러 지금까지 소개한 예측 목적과 관련이 높은 텍스트를 이용하면 예측 모형의 성능을 향상시킬 수 있습니다. 다음 마지막 시리즈에서는 영화 리뷰 데이터를 사용하여 분류 규칙을 개발하는 과정을 소개해 드리겠습니다.
SAS VDMML 관련 내용은 홈페이지를 통해서 더 자세히 알아보십시오.






