비정형 텍스트 데이터는 인류가 생성하는 가장 큰 데이터입니다. 더 나은 비즈니스 결정을 내리고, 제품 전략을 알리고, 고객 경험 개선에 도움이 되는 유용한 정보가 바로 이 데이터에 포함되어 있습니다. 비정형 텍스트 데이터의 잠재력을 최대한 활용해야 하는 이유입니다. 본 시리즈에서는 텍스트 데이터에서 인사이트를 얻는 주요 방법과 이를 위한 SAS 솔루션을 살펴봅니다.
전 세계적으로 매일 하루 평균 5 억 개 이상의 트윗과 약 55 억 개의 SMS 문자, 2 억 8100 만 개 이상의 이메일이 생성되고 있습니다. 비정형 데이터죠. 한편 기업들은 고객 통화 기록, 이메일, 설문 조사, 제품 피드백, 문서 및 보고서 등 조직 내에서 수많은 비정형 데이터를 매일 수집합니다.
이들 비정형 텍스트 데이터의 잠재력을 활용하기 위해서는 인간의 언어를 처리(Natural Language Process, 이하 NLP)할 수 있는 기술이 필요합니다.
비정형 텍스트 데이터와 자연어 처리
자연어 처리(NLP)는 비정형 텍스트로부터 분석자에게 유용한 정보를 찾아내는 개념으로, 넓은 의미로는 텍스트 마이닝(Text Mining)과 유사한 용어로 사용하기도 합니다. 하지만, 텍스트 분석 영역에서는 ‘텍스트 전처리(Text Pre-Process)’의 의미로 사용됩니다. 즉, 텍스트 원문(Text source / Text Corpus)를 어절 또는 단어별로 쪼개고, 형태소 분석을 하여 어간을 찾고, 이에 대한 품사를 추정하는 순서로 정형화 과정을 거치는 작업으로 이해하시면 됩니다.
SAS는 이러한 NLP 기능을 통합 탐색 솔루션인 SAS Visual Analytics(이하, VA)와 머신러닝 솔루션인 SAS Visual Data Mining & Machine Learning(이하, VDMML)에 탑재했습니다. 따라서 복잡한 텍스트 전처리 작업을 수행하지 않고서도 비정형 텍스트 문서를 탐색하고, 탐색 결과에 따라 문서의 토픽을 찾아낼 수 있습니다. 대용량의 문서를 직접 읽지 않고서도 어떤 토픽으로 문서들이 분포되어 있는지를 파악할 수 있는 것입니다. 또한 추가적으로 향후 발생하는 새로운 텍스트 문서가 어느 토픽에 포함되어 있는지를 분류할 수 있는 기능을 제공합니다.
SAS VA를 활용한 텍스트 데이터의 토픽 탐색
SAS VDMML에는 SAS의 빅데이터 탐색 솔루션인 VA가 통합 연계되어 있습니다. SAS VA는 대용량의 정형/비정형 데이터를 빠른 시간에 탐색할 수 있는 솔루션입니다. <그림2>와 같이 기사의 제목/기사 내용/분류 기준이 저장되어 있는 950개의 기사 데이터에 대한 텍스트 탐색을 통해, SAS VA의 텍스트 탐색 기능이 어떤 결과를 제공하는지 함께 살펴보겠습니다.
SAS VA를 통해 <그림3>와 같이 텍스트 데이터의 초기 분석을 수행하면, Word Cloud와 토픽 목록을 볼 수 있습니다. 옵션 메뉴에서 생성할 최대 토픽 항목 수는 ‘5’로 선택했습니다.
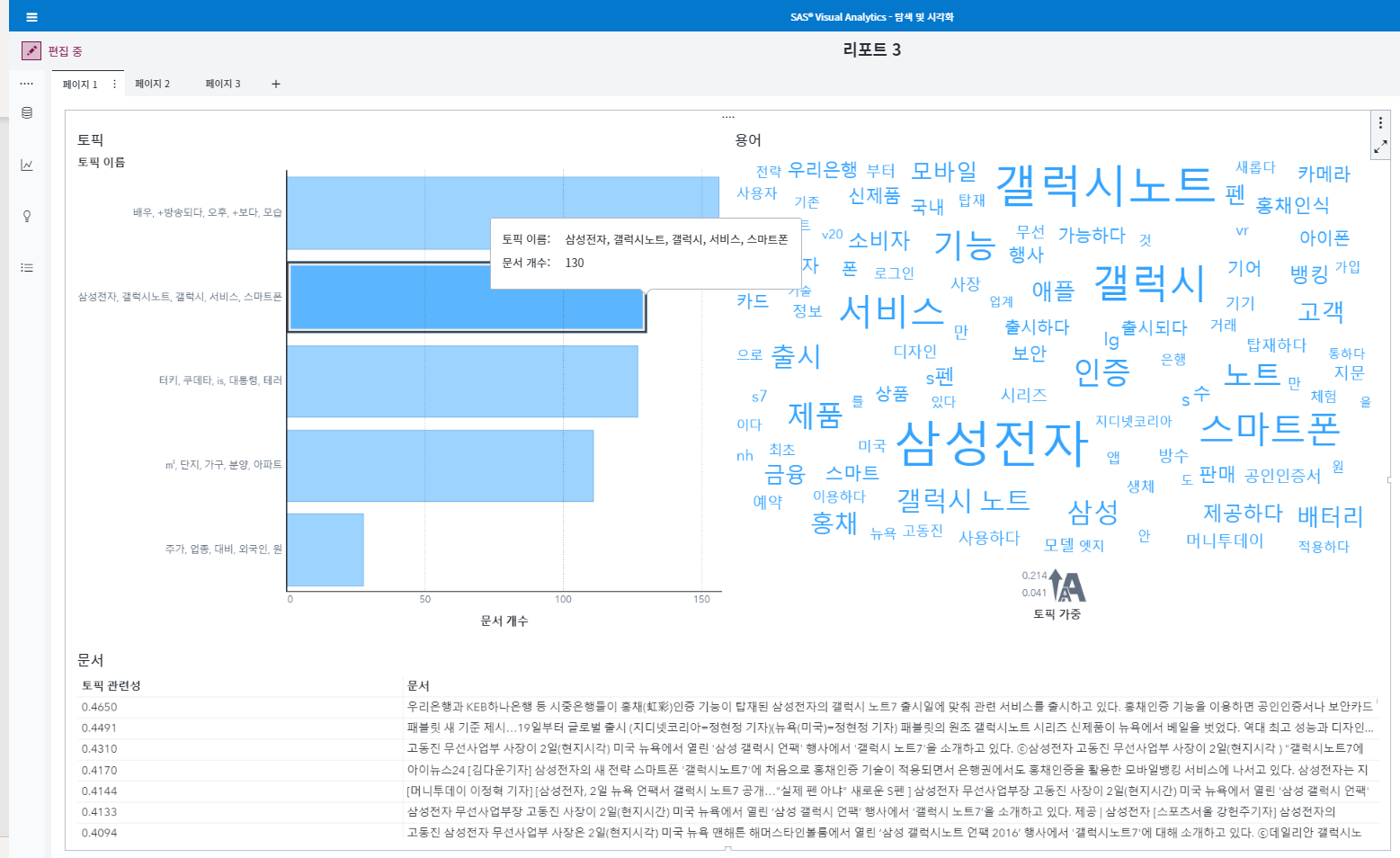
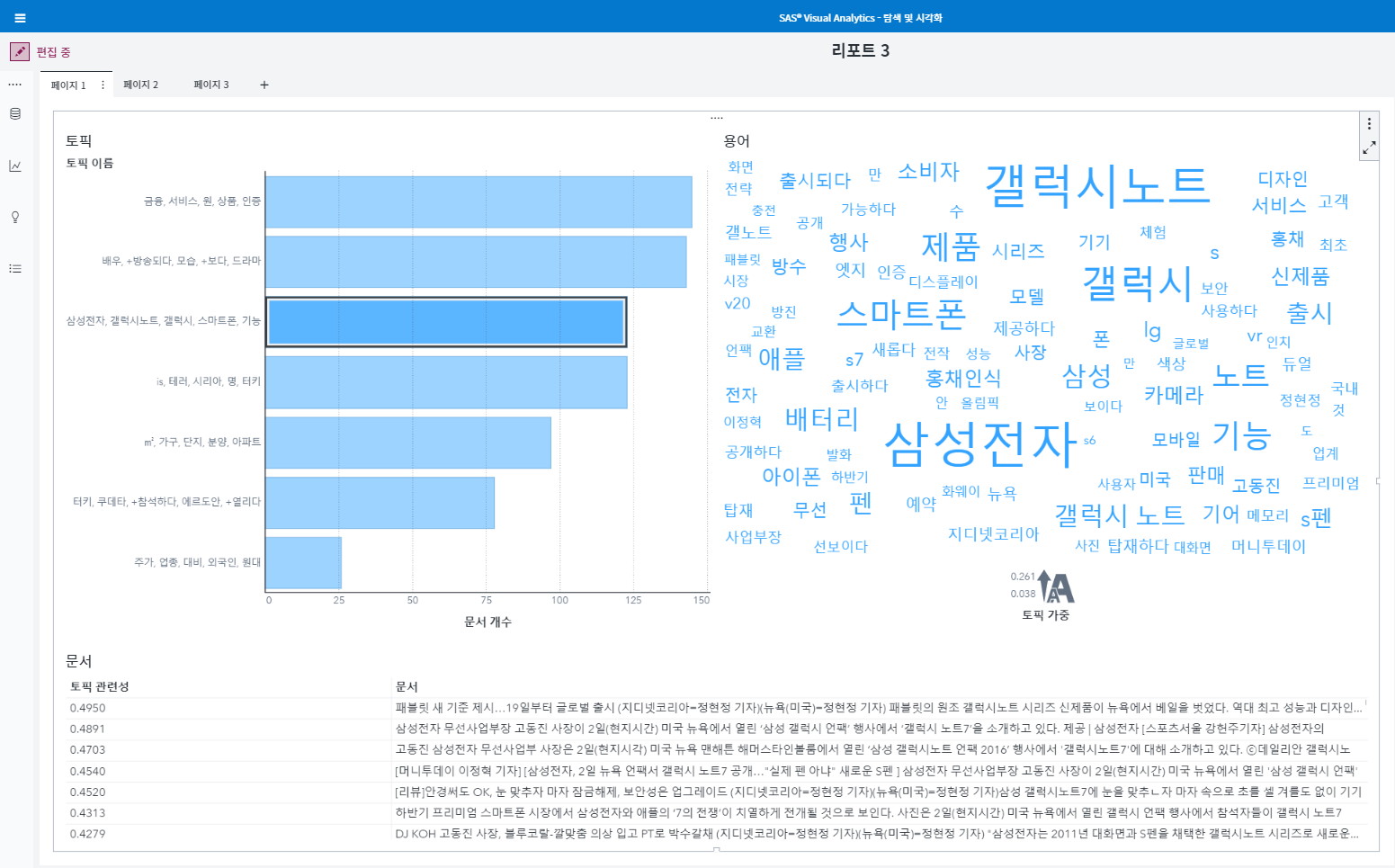
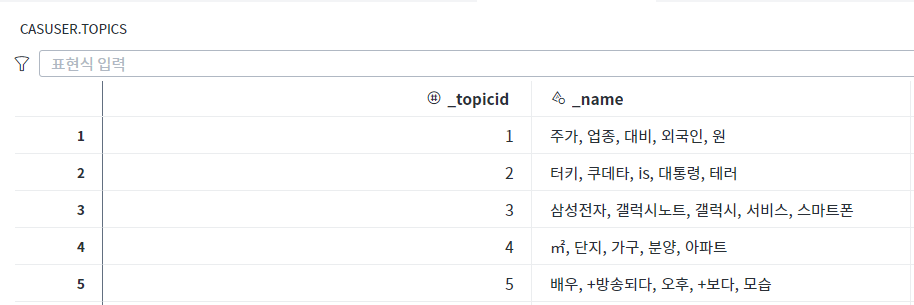
‘삼성전자, 갤럭시, 갤럭시 노트, 서비스, 스마트폰’이라는 ‘삼성전자’ ‘갤럭시’라는 용어가 포함된 토픽에 130개의 기사가 있음을 볼 수 있습니다. 맨 아래 토픽에 해당하는 약 30개의 기사는 주가와 관련된 기사(해당 토픽 – ‘주가, 업종, 대비, 외국인, 원’)임을 알 수 있습니다. 최대 토픽 항목 수를 7로 변경하면 <그림4>과 같이 토픽 목록과 Word Cloud가 바뀝니다.
다음으로는 텍스트 데이터에 대한 초기 탐색을 통해 전체 문서의 토픽을 파악한 후, 신규 기사가 사전에 확인된 토픽 중 어느 토픽에 해당하는 기사인지 파악해보겠습니다.
SAS VDMML의 텍스트 분석 머신러닝 Procedure
SAS의 VDMML의 TEXTMINE procedure와 TMSCORE procedure를 이용하면 학습 데이터를 이용하여 텍스트의 토픽들을 생성하고, 이후에 신규 발생 문서가 어느 토픽에 속하는지 스코어링할 수 있습니다.
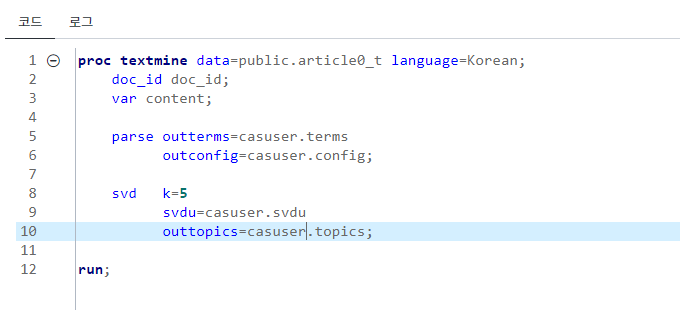
<그림5>처럼 Proc TEXTMINE 문장을 통해 텍스트 전처리 및 토픽 분류를 간편하게 진행할 수 있으며, k=5 옵션을 통해 5개의 토픽을 분류한 결과, <그림6>과 같이 나타났습니다. 문서 상단의 VA를 통한 토픽 분류와 유사하게 나왔음을 확인할 수 있습니다.
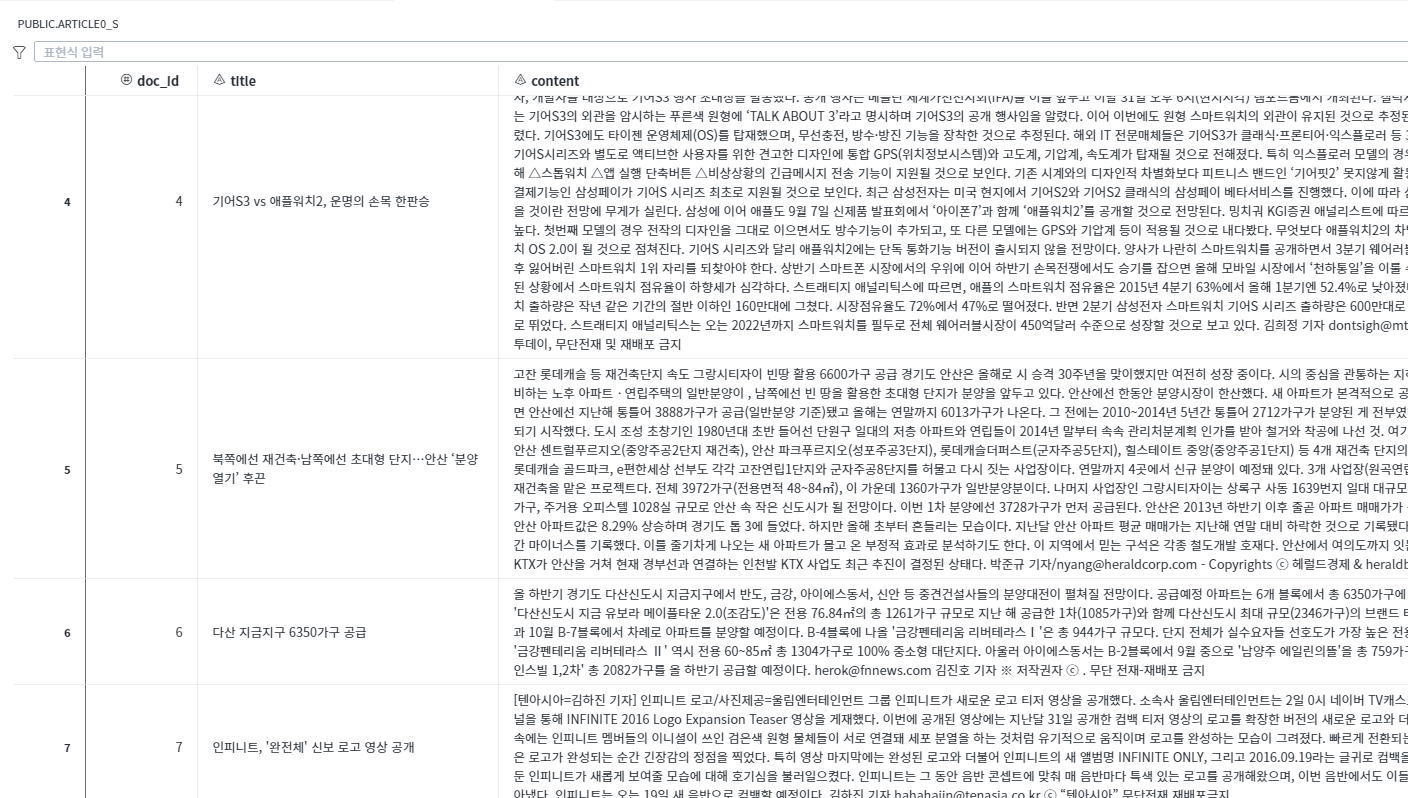
학습데이터의 토픽 분류 결과를 이용하여 <그림7>의 새로운 기사 10개(data = public.article0_s)가 어느 토픽에 해당되는지를 스코어링하여 확인해 보겠습니다.
Proc TMSCORE를 이용하여, 신규 기사 데이터 public.article0_s를 <그림8>과 같이 스코어링하여 토픽 분류를 확인할 수 있습니다.
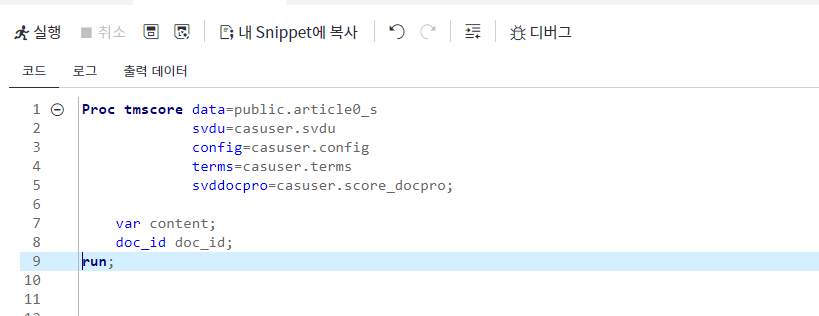
Proc TEXTMINE 실행을 통해 산출된 casuser.svdu casuser.config casuser.terms의 세 개 테이블이 input으로 사용되며, 토픽 분류 결과는 casuser.score_docpro 테이블에서 확인할 수 있습니다.
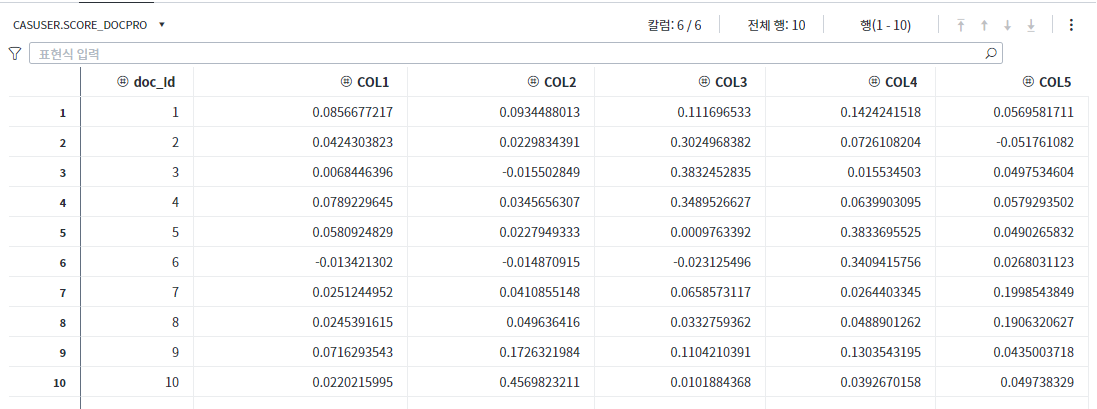
결과 테이블은 <그림9>와 같습니다. 10개의 신규 문서 각각의 토픽 가중치 값이 테이블로 제시됩니다.
4번 기사 ‘기어S3 vs 애플워치2, 운명의 손목 한판승’ 이라는 제목의 기사는 3번 토픽 ‘삼성전자, 갤럭시, 갤럭시노트’ 토픽으로 분류되었습니다. 5번 기사인 ‘북쪽에선 재건축·남쪽에선 초대형 단지…안산 ‘분양 열기’ 후끈’이라는 제목의 기사는 4번 토픽 ‘단지, 가구, 분양, 아파트’라는 토픽으로 분류되었습니다. 7번 기사인 ‘인피니트, '완전체' 신보 로고 영상 공개’라는 제목의 기사는 5번 토픽 ‘배우, 방송, +보다’의 토픽으로 분류되었음을 확인할 수 있습니다.
수천 수만 개의 대용량 텍스트 문서를 담당자가 읽지 않고, 어떤 내용(토픽)으로 구성되어 있는지를 쉽게 파악하는 것은 텍스트 분석의 기본이자 핵심 기능입니다. 아울러 새로운 문서가 기존의 관심 토픽 중 어느 토픽에 속해 있는지 분류해주는 기능 역시 텍스트 분석의 중요 기능입니다. SAS는 이 모든 니즈를 만족시키는 텍스트 분석 솔루션을 제공합니다. 다음 시리즈에서는 텍스트 데이터를 기반으로 고객의 행동을 예측하고, 예측 모델링의 성능을 개선하는 방법을 알아보겠습니다.
SAS VDMML 관련 내용은 홈페이지를 통해서 더 자세히 알아보십시오.






