This blog post is part two of a series on enhancing your natural language processing. The series is co-authored with my colleague Sundaresh Sankaran. A corresponding webinar series is also available on-demand. In the first article in this series, we covered the "hybrid approach” to text modeling.
Unstructured data challenges
When working with unstructured data, discovery techniques are another important aspect of your approach to consider. Unstructured data can seem difficult to work with and can take many forms – emails, social media, call logs, voice memos, transcriptions, documents, texts, and just about anything you’d say, write with a pen or type on a keyboard. Unstructured text can present a few challenges in preparing your text data:
- First, as you can imagine, unstructured text doesn’t fit neatly into rows or columns of a data table. Particularly with very large documents such as PDFs, it can be challenging to understand what type of text data is in your corpus or data set.
- The second challenge is that of sparse dimensions by which to analyze the data. Often, the data is hidden within the document. For example, when analyzing patterns in healthcare narratives, information on prior medications and symptoms is very important. But they tend to be buried inside the narrative and need to be extracted.
- The third aspect is that your text data may contain subjective content. This is often the case in customer experience data, where sentiment and opinions are expressed, and these must be identified and measured. Also, natural language by definition includes slang, emotion, and other nuances. In written form, there are also abbreviations, typos, and misspellings to account for.
Tips for discovery
Discovery is an important part of setting up your analysis for success – essentially it prevents you from plunging into a haystack to try to find that elusive needle, and rather, helps you organize the haystack into neater, compact organized bales that you can navigate with ease. Proper discovery can help you more efficiently find patterns in your data set. Here are some best practices:
- Have a clear understanding of the question or problem you are trying to solve at the outset. This will help you identify the right approach for your data.
- A visual, easy-to-use text analytics interface can help reduce time and effort. You should be able to import and ingest data sources of multiple formats and structures (such as PDFs and documents) easily. This avoids manual and labored data preparation, which otherwise can take up a large part of the analyst's time and efforts.
- Don’t discount the value of human intelligence within the discovery phase, particularly when it comes to interpretation and curation of the patterns found in your data. Keeping a human in the loop can help to annotate, filter, or modify the way text insights are represented throughout the process.
Key text analytics discovery techniques
Your text data may include a wide range of themes that you are trying to understand and analyze. NLP tasks break down language into shorter, elemental pieces to understand relationships and explore how those pieces work together to create meaning.
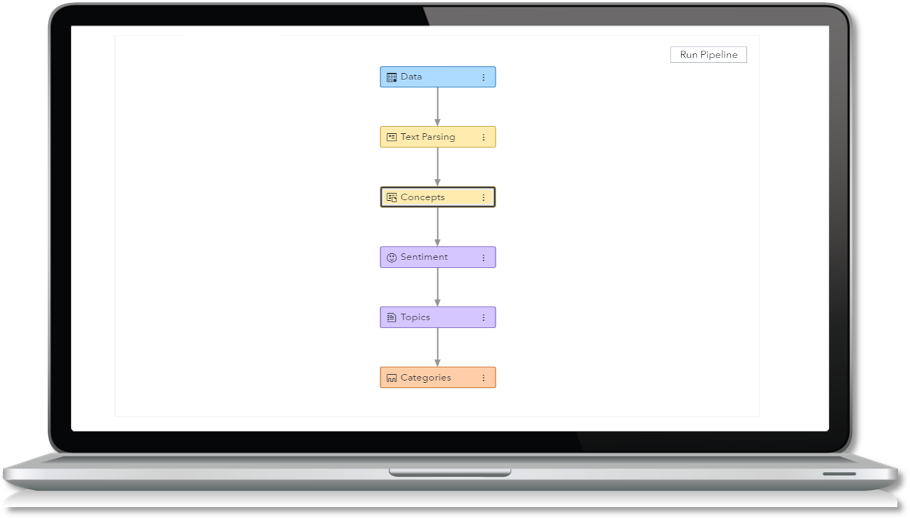
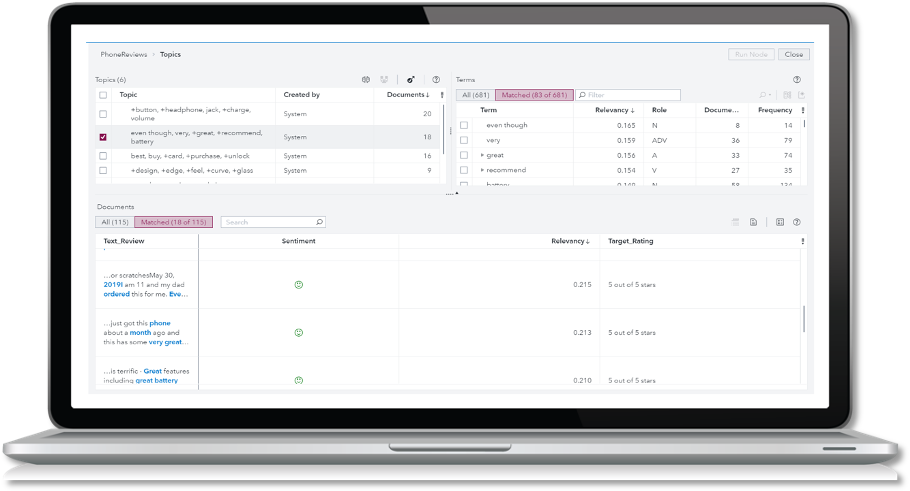
One way to get started in the discovery process is to extract text topics. A Topic Model can help uncover “topics” or themes buried within a set of documents or text data.
Your text analytics solution should help you quickly visualize (such as in a word cloud) themes that are most closely aligned to your target topic versus the highest frequency.
Look for relevancy scores to understand the contents, individual documents, and sets of documents with the highest relevancy for your analysis. The more relevant the documents, the more confidently you can say that these documents follow a theme or pattern. Each document can also be tagged with individual weights relating to the topics and sentiment analysis can be performed for additional insights.

Taking this a step further, consider applying text parsing to your analysis, which helps you extract specific areas of interest, also known as concepts. Text parsing can help you understand the relationship between the most important or most frequent terms in your data set. This helps you discover insights regarding which terms come up most frequently together.
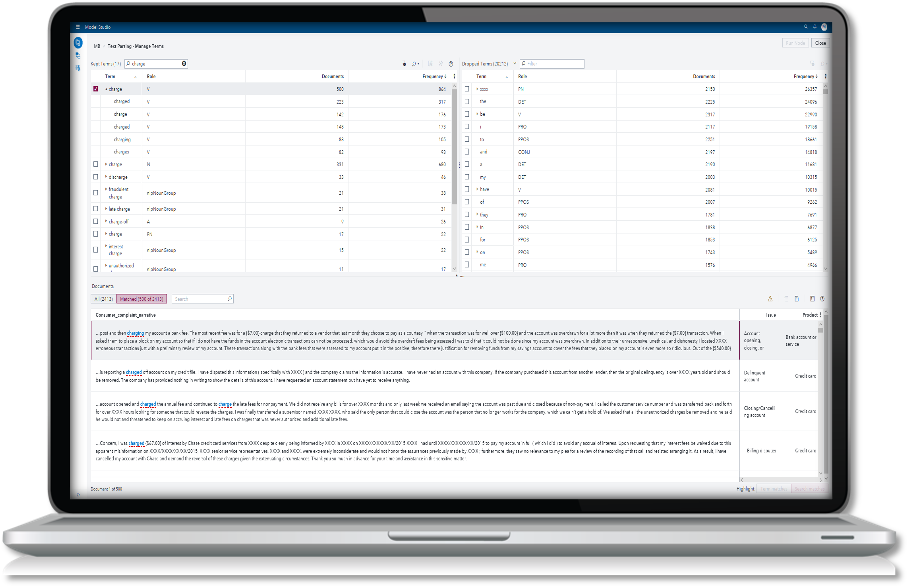
Segmentation and dimensionality reduction techniques such as topics discovery (through Singular Vector Decomposition (SVD) or Latent Dirichlet Allocation (LDA), and clustering can further help group these terms.
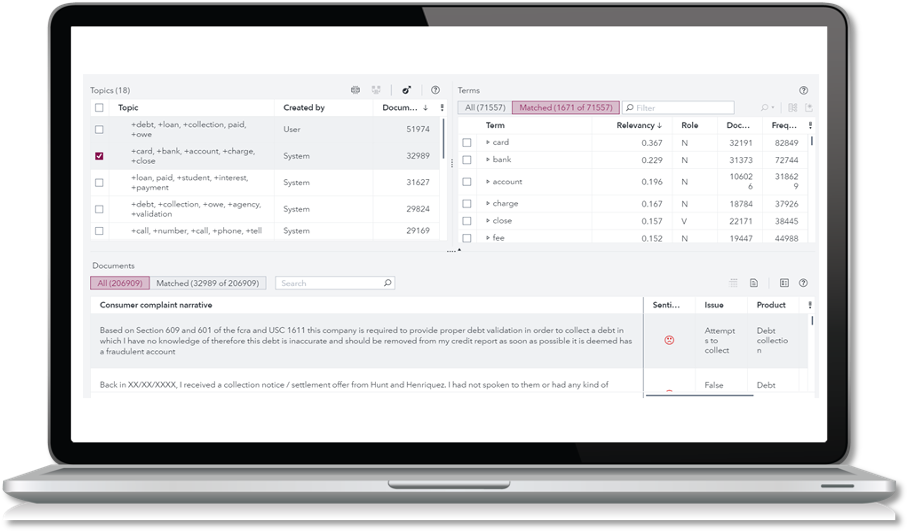
Document-level sentiment analysis provides another layer of insight – helping you understand the subjective and emotional nuances in the text data, such as positive, negative, or neutral sentiment.
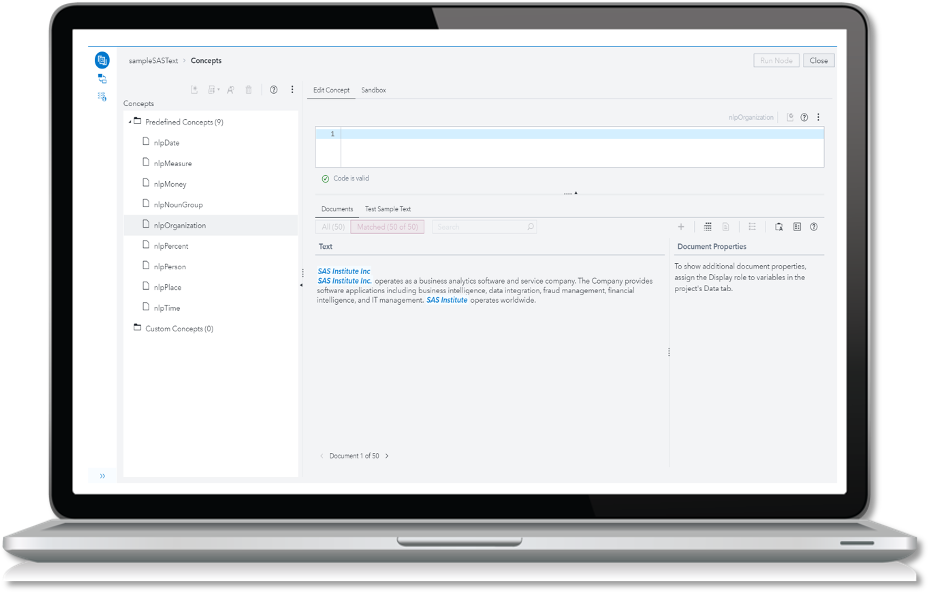
Concept extraction is another important aspect of discovery. A good way of thinking about concepts would be to consider them as people, organizations, locations, etc. With SAS Visual Text Analytics, pre-defined concepts are available to help you quickly get started.
These are just a few techniques and tips to approach discovery for your text analytics project. Again, it’s always important to stay focused on your business objective and keep the big picture in mind when approaching any text analytics project. With NLP, you can generate meaningful insights to inform your business decision or impact your customer experience.
What's next?
Learn more in the second webinar in our Enhancing your Natural Language Process series: Discovery Techniques. During the webinar, you’ll learn more about ways to explore text data plus demos of each technique using SAS Visual Text Analytics. Check out the full webinar series here and keep an eye out for the next post in this blog series where we will take a closer look at conversational AI. Thank you for reading!