This blog post is part one of a series on enhancing your natural language processing. The series is co-authored with my colleague Sundaresh Sankaran. A corresponding webinar series is also available on-demand.
Unstructured data
Did you know that unstructured text is the largest human-generated data source? Each day worldwide, we send on average more than 500 million Tweets, about 5.5 billion SMS texts, and over 281 billion emails. Tons of unstructured data is collected within organizations every day, too – from customer call logs, emails, surveys, product feedback, documents and reports, and so on. Often buried within that unstructured data are rich insights that can help drive better business decisions, inform product strategy, and improve customer experiences.
Unlocking the potential of your unstructured text data can lead to great business outcomes but the prospect of starting a new or enhancing your existing Natural Language Processing (NLP) project can feel overwhelming because of the inherently unique (and sometimes messy) nature of human language. Text data doesn’t fit neatly into rows or columns the way that structured data does, which can make it seem more complex to work with. Conversations and written language range from objective statements to subjective perspectives and opinions. The same sentence, depending on its intent and the nuances in how it's said, can have a positive, negative, or neutral sentiment. To get us started, we'll share different types of NLP models used to analyze unstructured data with a focus on the hybrid approach.
First, what is NLP?
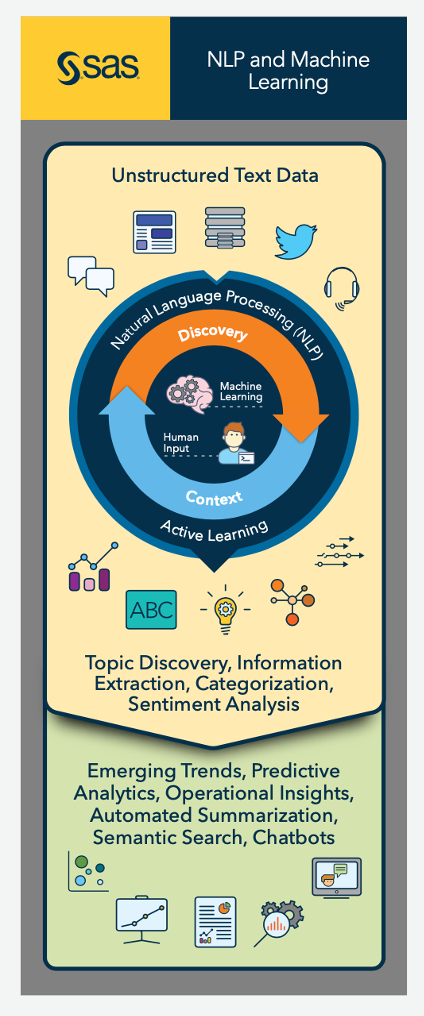
NLP is a branch of artificial intelligence that helps computers understand, interpret, and emulate human language. NLP provides structure to unstructured data (such as emails, chat, social media, documents, etc.), allowing organizations to scale the human act of reading, organizing, and quantifying text data so it can be more easily analyzed – enabling faster speed to insights and ultimately, faster evidence-based decisions.
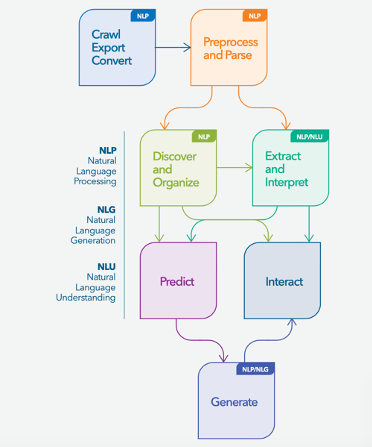
NLP draws on machine learning and human-generated linguistic rules, to fill the gap between human communication and machine understanding. Using NLP, we can automatically extract key features, categories, summaries, and relational concepts from text data.
Human input from linguistic rules helps the machine recognize and understand the construct of language – enabling contextual comprehension, or Natural Language Understanding (NLU) of content, such as slang, sarcasm, and sentiment. When a command is passed to a Natural Language Generation (NLG) component, it can even generate well-formed human language on its own within a specific domain or task. You can learn more about AI and NLP through our AI Pathfinder.
NLP models & the hybrid approach
NLP models can include different types of approaches:
1. Rule-based approach
A rule-based approach is a human-driven system, that relies on linguistic rules to extract, categorize, and analyze text. It looks at linguistic relationships to interpret language and its parts (i.e., grammar, sentence structure, etc.). Having a subject matter expert (SME) and/or linguist involved is critical to the process. There is often a high level of control and ability to adjust rules as needed with this approach. This approach is typically well-suited for task-oriented experiences or search queries.
2. Unsupervised machine learning model approach
An unsupervised machine learning model uses unlabeled data that the algorithm tries to make sense of by extracting features and patterns on its own. This approach can require a significant amount of training data. This approach can seem like a black box -- typically with less control over the model and more unknowns, making it more difficult to intervene if something goes wrong or needs to be adjusted.
3. Supervised machine learning model approach
Supervised ML models leverage predefined labels (such as sentiment or categories) as a starting point. Human training and subject matter experts improve the model accuracy over time. This approach can also require a significant amount of training data. Because of the human training combined with ML, it can be a good fit for conversational experiences (i.e., chatbots).
4. Hybrid approach
The hybrid approach combines the best of rule-based and ML approaches with natural language processing, machine learning, and human input. Human expertise provides guidance for accurate analysis and machine learning helps that analysis scale with ease. Machine learning can further help reduce the human model building effort by leveraging semi-supervised learning to automate the tagging data based on human input to your training data. This approach can be built without a large set of training data. It provides increased transparency into the system to ensure a good customer experience (CX) and the ability to track against business goals (KPIs). The hybrid approach also offers increased flexibility, the ability to iterate, and speed, resulting in decreased strain on resources. This approach is a good fit for conversational experiences as well as task-oriented projects.
Depending on your objective, it’s generally a best practice to analyze unstructured text data using a hybrid approach. The hybrid approach provides you with options that you can use to determine the best path to model your text and get to faster business decisions. A flexible, easy-to-use visual interface such as SAS Visual Text Analytics can help create and deploy models that fit your business needs with little to no coding required.
What's next?
Learn more in this on-demand webinar, Enhancing your NLP: The Hybrid Approach, where we cover these approaches in more detail and share an illustrative healthcare scenario to demonstrate how to apply each approach. We’ll walk you through how to identify text variables, develop categories and a taxonomy or classification system, and how to build and test your text analytics pipeline to discover insights from text data and to get to the desired business outcome.
Also, keep an eye out for the next post in this blog series where we will take a closer look at NLP discovery techniques. Thank you for reading!