At the KDD conference this week I heard a great invited presentation called How to Create a $1 billion Model in 20 days: Predictive Modeling in the Real World – A Sprint Case Study. It was presented by Tracey de Poalo from Sprint and former Kaggle President and well known machine learning expert Jeremy Howard (@jeremyphoward). Jeremy convinced Sprint’s CEO that machine learning could help their business, so he was brought on as a consultant to work with Tracey and her team. The result was the $1 billion model, which he called the highest value machine learning case he’s ever seen.
Jeremy had the executive blessing they needed to get access to key teams, so they conducted 40-50 interviews to identify which business problems to prioritize for their work. Based on these interviews they decided to prototype models for churn, application credit, behavioral credit, and cross-sell. When ready to tackle the data, Jeremy was impressed that they were ahead of the curve. Tracey’s team had already built a data mart of 10,000 features on each customer. Jeremy said their thorough and well-organized data dictionary was the best he’d seen in his career.
For a planned benchmarking exercise, Jeremy chose his favorite Kaggle-winning scripts from R packages caret and randomForest. Based on his past Kaggle success he was felt confident he’d beat her existing models. When the results were in he confessed he was shocked that his were almost the same as hers, which were based on logistic regression. Kudos to Jeremy for his refreshing honesty, as someone commented during the Q&A.
Tracey’s team’s process was very rigorous and completely automated process used: 1) missing value imputation; 2) outlier treatment; 3) variable reduction (getting them down by ~65%); 4) transformations; 5) VIF (limit to 10); 6) stepwise regression (down to ~ 1,000 variables); 7) model refitting (50-75 left). Jeremy was most amazed at Tracey's strategic use of variable clustering, commenting that it is an interesting approach that he hadn’t seen elsewhere. She ranked her variables by R2 and then picked one variable/cluster.
As a result of their work together their new model identified nine variables that explained the majority of bad debt. Combining these factors with customer credit data they were able to estimate customer lifetime value, which allowed them to quantify the cost for making a bad call on credit. Adding these costs up you reach $1 billion in value.
A history of machine learning in SAS
What I love about the machine learning model Tracey's team had in place is that it has its roots in a very early SAS procedure, VARCLUS, which goes back to at least the early 1980’s. As I wrote before, machine learning is not new territory for SAS. SAS implemented a k-means clustering algorithm in 1982 (as described in this paper with PROC FASTCLUS in SAS/STAT®), but after reading my post Warren Sarle pointed out that PROC DISCRIM did k-nearest-neighbor discriminant analysis at least as far back as SAS 79. This early procedure was written by a certain J. H. Goodnight, who some may recognize as SAS founder and CEO.
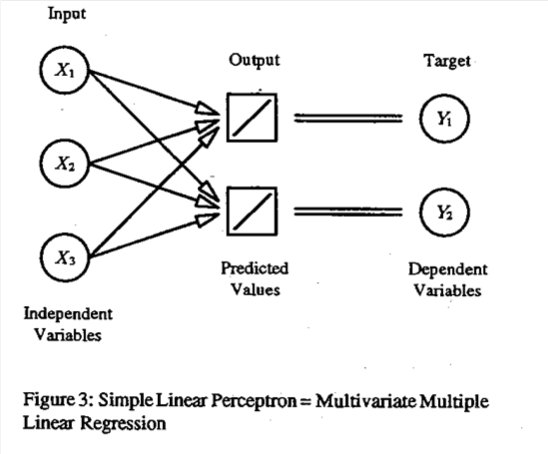
A neural learning technique called the perceptron algorithm was developed as far back as 1958. But neural network research made slow progress until the early 1990’s, when the intersection of computer science and statistics reignited the popularity of these ideas. In Warren Sarle’s 1994 paper Neural Networks and Statistical Models (where I found the illustration to the left), he even says that “the most commonly used artificial neural networks, called multilayer perceptrons, are nothing more than non-linear regression and discriminant models that can be implemented with standard statistical software.” He then explains that he will translate “neural network jargon into statistical jargon.”
Flash forward to today, where this article from Forbes reports that the most popular course at Stanford is one on machine learning. It is popular once again, and the discussions and papers at KDD this week certainly reflected this trend. While machine learning is nothing new for SAS, there is a lot of new machine learning in SAS. You can read more on machine learning in SAS® Enterprise Miner in this paper and in SAS® Text Miner in this paper, to name just a few of our products with machine learning features. Now grab some and go build your own $1 billion model!






