Looking forward, ten of my SAS colleagues and I are heading to New York City this weekend for KDD 2014: Data Science for the Social Good, which runs August 24-27. This event’s full name is the 20th Association for Computing Machinery Special Interest Group on Knowledge Discovery and Data Mining, but it is more commonly known as ACM SIGKDD, or just KDD for short.
Looking backwards, the first KDD workshop was held in 1989, and these workshops eventually grew into the series of conferences. Whether you still call it data mining, or prefer machine learning or data science, the fact that this year the conference is sold out, with the 2,200 registered exceeding all expectations, is a sign of the trending of this topic. KDD’s tagline today is “bringing together the data mining, data science, and analytics community,” so this nexus is right where SAS has played for years. In fact, the picture below is taken from a data mining primer course SAS offered in 1998.
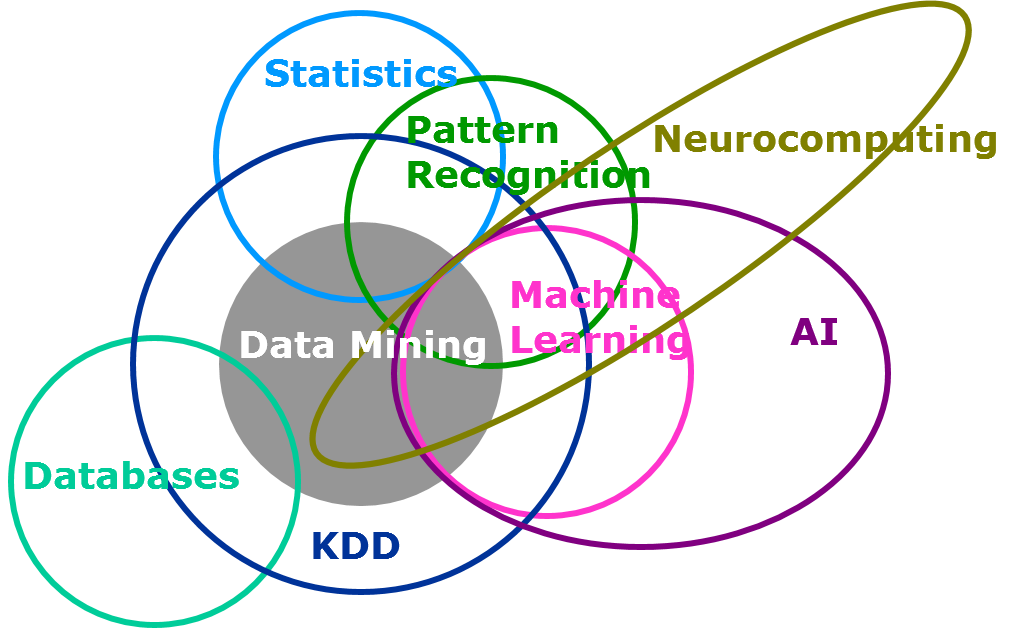
The SAS story starts with the statistics circle above, when the language was first developed in 1966, multiple regression and ANOVA were added in 1968, the first licenses sold in 1972, and the company incorporated in 1976. SAS moved into the data mining and machine learning circle early, when in 1982 the FASTCLUS procedure implemented k-means clustering. But while there’s more to this history, I’ll save it for another post and return to a forward-looking view.
I’m looking forward to hearing a keynote on Sunday night by Pedro Domingos (Department of Computer Science and Engineering at the University of Washington), who is the 2014 winner of the ACM SIGKDD Innovation Award and will be giving the talk associated with that award at the conference. I found his paper A Few Useful Things to Know about Machine Learning to be an excellent resource. On Monday morning Oren Etzioni (Executive Director of the Allen Institute for Artificial Intelligence, from the same department at the University of Washington) will give a talk on “The Battle for the Future of Data Mining,” which certainly will inform my forward-looking view. It will be interesting to hear where he thinks the field is heading, and where the battles will lie.
On Monday morning, right after we’ve heard Dr. Etzioni look to the future, my own colleague Zheng Zhao will give a paper he co-authored with our fellow SAS peers James Cox and Jun Liu on “Safe and Efficient Screening For Sparse Support Vector Machine” in the Feature Selection Research Track. In this paper, a novel screening technique is proposed to accelerate model selection for SVM and effectively improve its scalability. The emergence of big-data analysis poses new challenges for model selection with large-scale data that consist of tens of millions samples and features. This technique can precisely identify inactive features in the optimal solution of an SVM model and remove them before training. Experimental results on five high-dimensional benchmark data sets demonstrate the power of the proposed technique.
SAS will be in the exhibit hall with a booth (#14). In addition to talking about the products SAS offers for machine learning, we will be talking about our new SAS Analytics U initiative, which includes SAS® University Edition, a free, downloadable version of select SAS statistical software that runs on PCs, Macs, and Linux and is designed for teaching and learning SAS. We'll also be giving away some copies of our colleague Jared Dean's new book, Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners. In the booth on Monday and Tuesday we will also offer what we call superdemos, which are 15-minute long demos on focused topics. Here is the list:
Monday, August 25, 10:00-10:15 a.m. Deep learning for dimensionality reduction/visualization Jorge Silva We will showcase deep learning with PROC NEURAL, using a deep auto-encoder architecture to visualize clustering results on medical provider data. Monday, August 25, 1:00-1:15 p.m. Contextual Recommendation using Text Analysis Yue Qi The collaborative filtering-based recommender is prone to the cold start problem and long tail problem, so this demo will show how to derive contextual recommendations using text analysis to address both problems. Monday, August 25, 3:00-3:15 p.m. Time series dimension reduction for data mining using SAS Catherine Lopes This demo introduces SAS procedures for time series dimension reduction in data mining. Monday, August 25, 5:00-5:15 p.m. New techniques for doing association classification and a demonstration of their usefulness for mining text Jim Cox We will describe two new algorithms for pattern discovery with a single consequent or external category: Bool-yer and AssoCat. Tuesday, August 26, 10:00-10:15 a.m. R integration node Jorge Silva This demo will illustrate the diagram and workflow user interface and also focus on how people can try their favorite R algorithms while taking advantage of data handling and pre-processing capabilities built into SAS® Enterprise Miner. Tuesday, August 26, 1:00-1:15 p.m. Classification Using Bayesian Networks in SAS® Enterprise Miner Weihua Shi Using a newly developed high-performance Bayesian network procedure (PROC HPBNET), this demo will illustrate the graphic-modeling approach using a real-world data. Tuesday, August 26, 3:00-3:15 p.m. Interactive Stratified Modeling using SAS® Visual Statistics Wayne Thompson This demo will show how to develop stratified models based on group-by variables, decision trees to derive segments and enforce business rules, and clustering demographic data followed by supervised models using transactional data.If you are already planning on attending KDD, come by booth #14 and see us. If you didn’t register in advance you’re probably out of luck, since the conference is sold out. But I plan to blog again after the conference and will offer some impressions from the event, as well sharing some more history about SAS, data mining, and machine learning, continuing with my backward and forward looks.







3 Comments
NoSQL since 1976!
I think I saw that diagram in an early Enterprise Miner course too. Thanks for the snippets of history and what a wonderful week at KDD you have planned. All the best and I look forward to reading your future blog post.
Pingback: Building a $1 billion machine learning model in SAS - Subconscious Musings