When I first started building predictive algorithms, I was solely focused on increasing the model's accuracy. I have steadily learned more sophisticated algorithms and how to manipulate training data to better fit the model and better represent real test cases. As problems become more sophisticated and the amount of data increases, the learning frameworks that handle distributed training become more important. Having a model to solve a task is great, but for it to be truly useful, we must deploy it where it is needed. However, this is not simple, because model deployment requires proper syncing between the model's output and the decisions displayed to the consumers as well as between the automated system "health" checks for the model and the overall system's workflows. In this article, we will combine three separate SAS Viya capabilities to create an application that can manage multiple models, interpret model outputs, and replace the production model if necessary.
These three SAS Viya capabilities are:
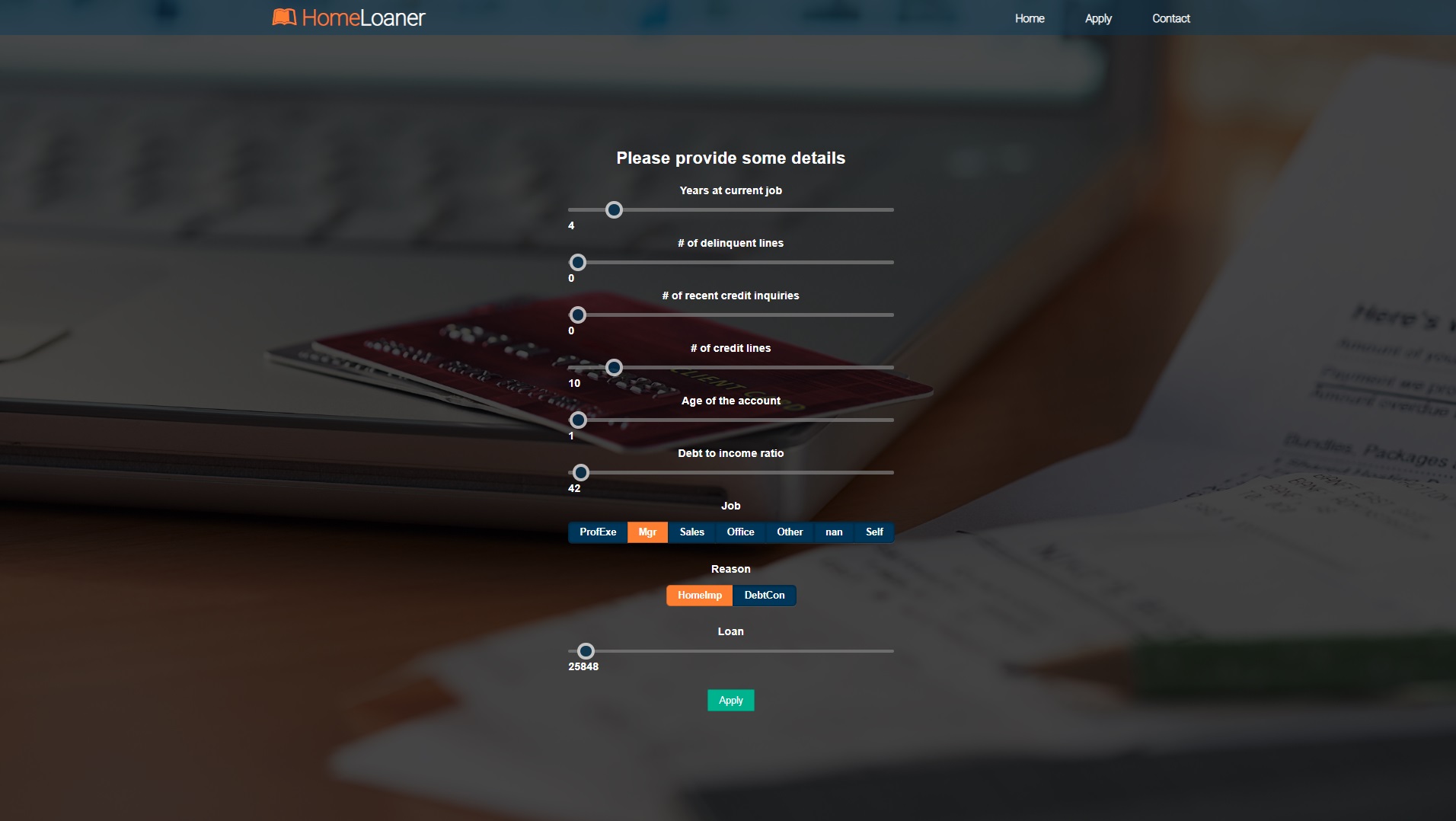
Our problem involves an application that approves or rejects online home loans. Although the application looks simple to customers, the processes that output the results are much more complex.
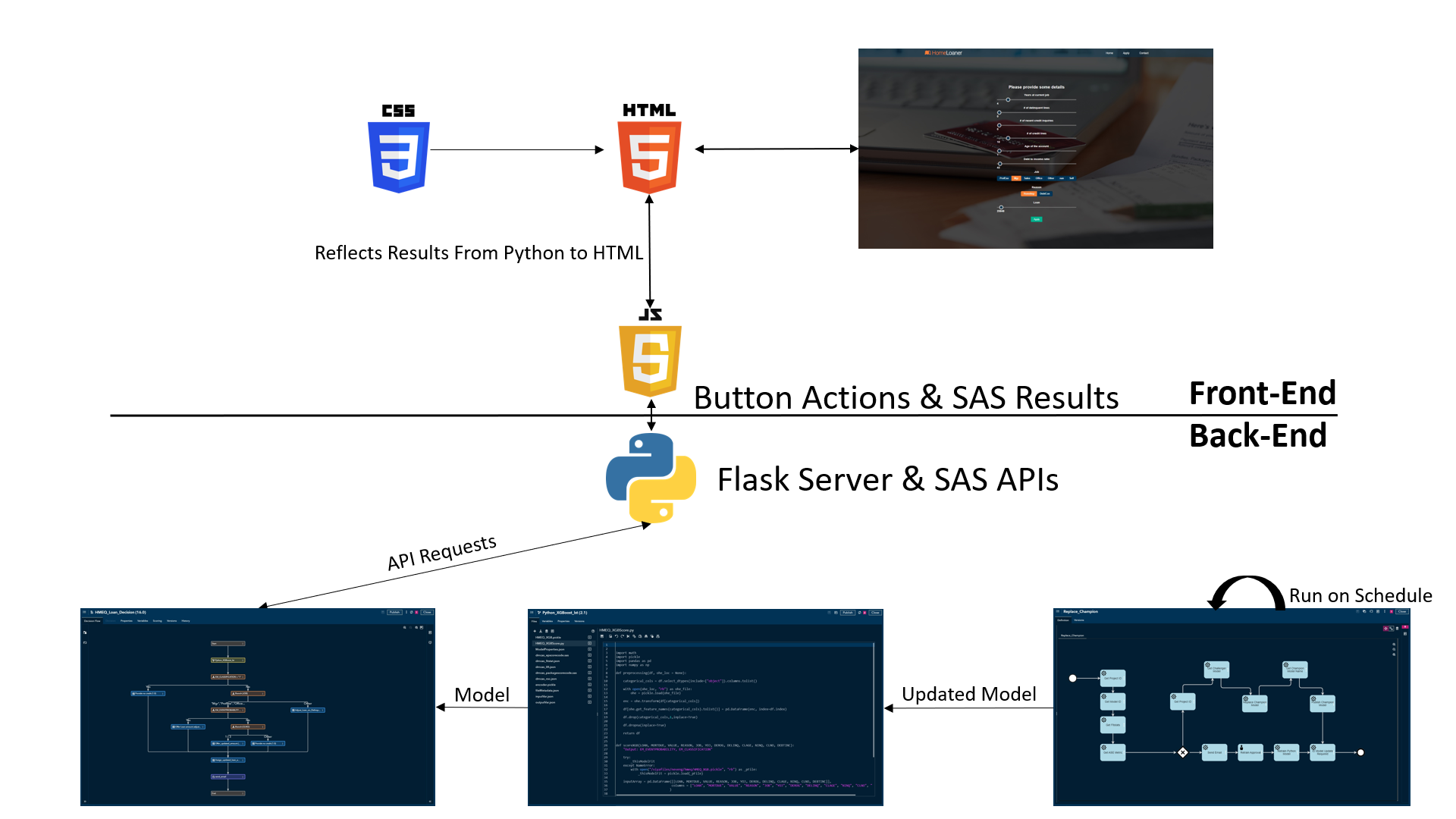
The graph below shows how SAS Viya processes interact with each other and pass data to the application.
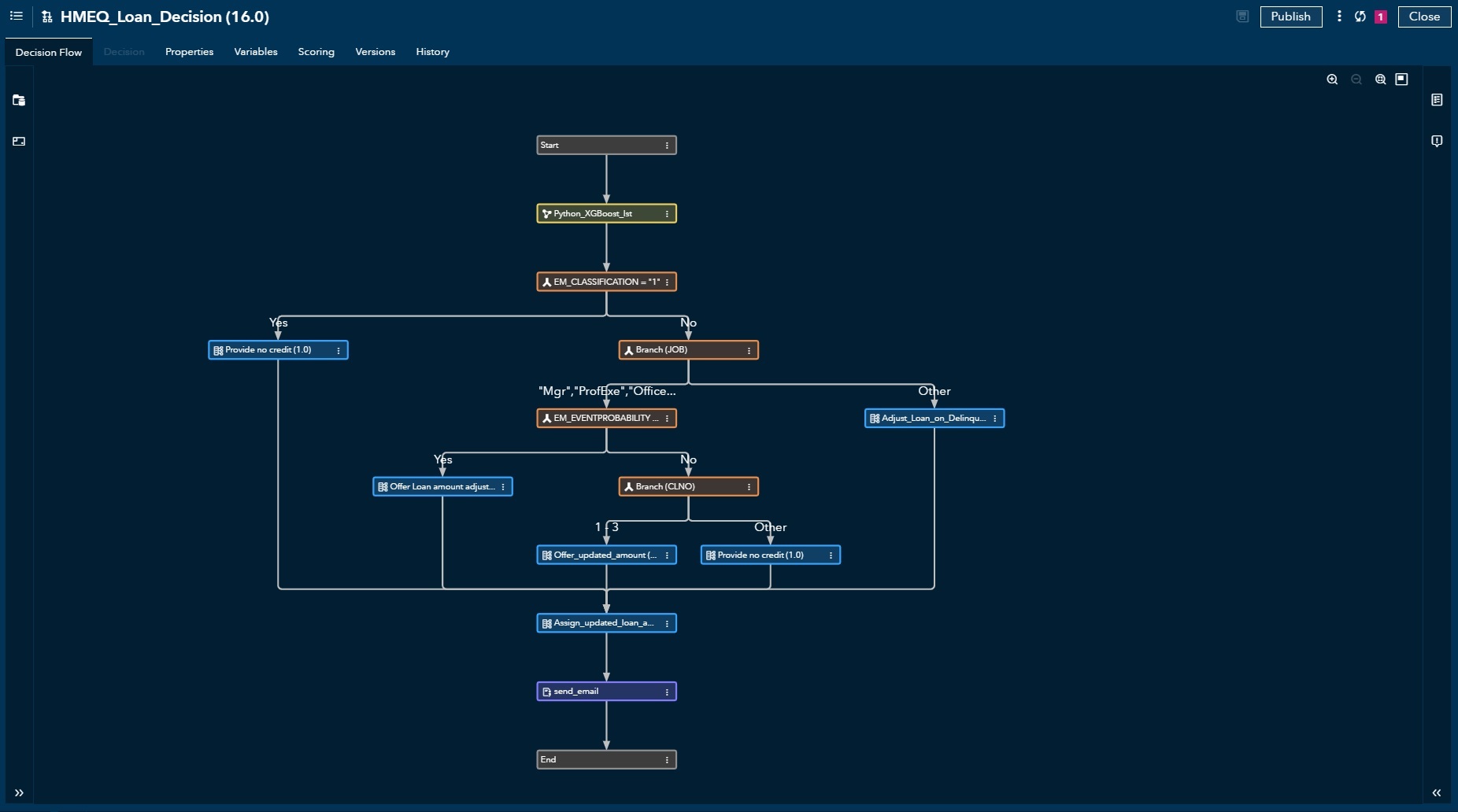
Intelligent Decisioning
Our model only predicts the probability of a customer not being able to pay off the loan, which is not what the applicants see. Using Intelligent Decisioning, we can build custom rules that incorporate SAS/non-SAS models, condition rules, table lookups, custom SAS/non-SAS code, and much more. As shown in our example, we have a Python model loaded from SAS Viya Model Manager. Its output decides whether to reject an application or approve some amount of loan. In the end, there is a custom Python code that sends out emails to applicants. The flow can be tested in a dev environment and published/deployed in another environment. Deployed flow returns an API endpoint that allows its execution via REST API calls.
Model Manager
 The Python model is stored in a model manager that allows us to:
The Python model is stored in a model manager that allows us to:
- store files & metadata that allow model scoring
- modify existing files
- track performance
- test the model locally (similar to Intelligent Decisioning)
- publish/deploy the model into another environment (similar to Intelligent Decisioning)
- test the deployed model (similar to Intelligent Decisioning)
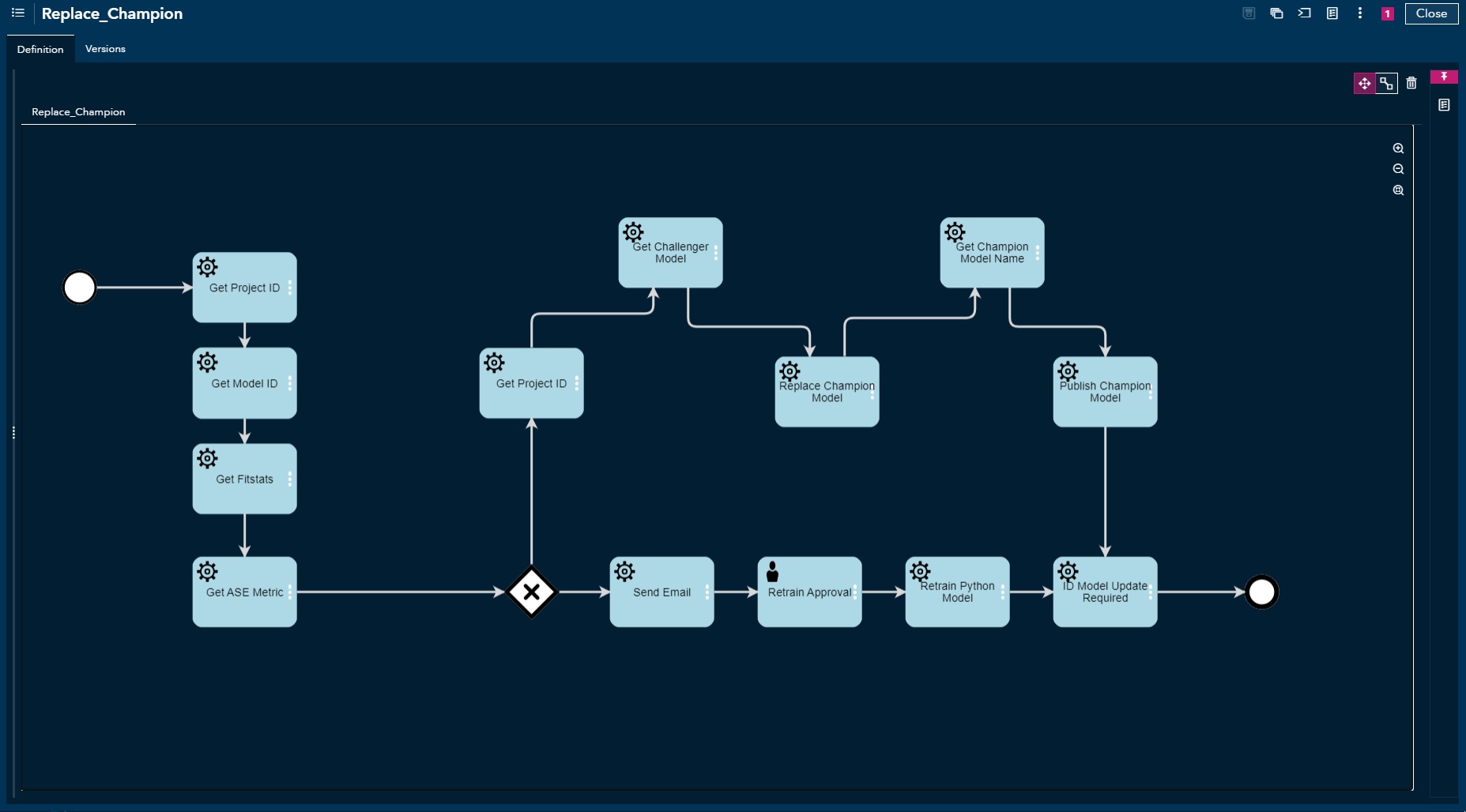
Workflow Manager
This section can get complex, but we only focus on maintaining a high-quality model. The workflow consists of multiple "tasks" that are either automated through API calls or manually executed. The flow automatically grabs a champion model from the Model Manager and checks its current performance report.
Path 1: if the performance is relatively stable, then simply feed in more data to the current Python model to keep it up-to-date. We send out an email to an administrator to manually approve a "task" for the flow to continue. Once approved, there is an API call to a Python script that loads a current model from Model Manager, adds more training to it, and pushes back to Model Manager.
Path 2: if the performance for the champion has dropped significantly, grab a stable challenger model, make it a new champion model, and deploy it into production. The flow only focuses on the model's lifecycle, however, any process that is reachable from API calls, including non-SAS based processes, can be embedded in the workflow manager.
Conclusion
The processes discussed here show the bare minimum of what should be done to make a very simple, production-level application. Building effective applications are difficult and building an analytical environment to support them can be even harder. SAS Viya has already built a centralized, self-maintained, scalable, and an open-source friendly analytical environment to minimize overheads during the development of your analytical processes.
To learn more, check out some of my other articles: