I’ve often heard people say about weather forecasters “they have the best job…they just report what the models are telling them, and when they’re wrong they can always blame it on Mother Nature throwing us a curve.” While that’s true, this glass-half-empty crowd is failing to appreciate how amazing the science and technology are to accurately predict the temperature, amount of precipitation, and path of a storm over an extended period of time, given all the atmospheric variation, complexity, and potential instability that exists. When I can know on Tuesday that there’s a good chance my trip to the beach will be a rain out on Saturday, I can start to make alternate plans. Thank you Mr. Weatherman and your super smart modeling algorithm. And thank you ensemble modeling.
Because it turns out we actually have the concept of ensemble modeling to thank for those generally accurate forecasts (as my local Raleigh weatherman Greg Fishel will profess as often as you will let him). It’s not a single model providing those predictions but a combination of the results of many models that serve to essentially average out the variance. The National Hurricane Center Storm Track Forecast Cone shown below is a perfect example; this uncertainty cone is composed by creating an ensemble of many different models forecasting the storm’s path, each one considering different atmospheric conditions in that time period.
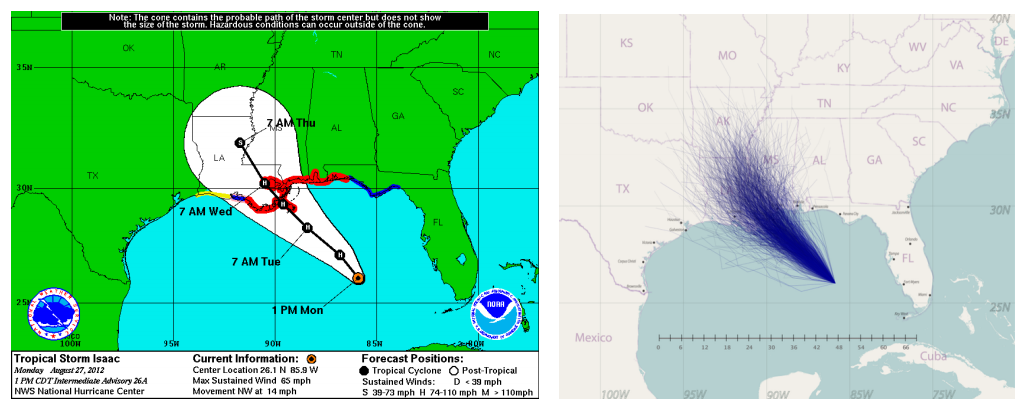
While weather forecasting is one of the more prominent applications of ensemble modeling, this technique is used extensively in many domains. In general, ensemble modeling is all about using many models in collaboration to combine their strengths and compensate for their weaknesses, as well as to make the resulting model generalize better for future data. And that last point is key. The goal of building these models is not to fit the existing data perfectly (running the risk of overfitting) but to identify and represent the overall trend of the data such that future events can be predicted accurately.
To that end, combining predictions from diverse models just makes sense - just like diversifying your investment portfolio and investing in mutual funds for a stronger overall yield. Given that market conditions are in constant flux (just as new data to be scored on a model deviates from training data), you know it’s smart to diversify with a combination of stocks from a variety of industries, company sizes, and types. Just as timing the market to buy and sell the right stocks at the right time is an overwhelming and time-consuming task, determining the single most effective machine learning algorithm (and its tuning parameters) to use for a given problem domain and data set is daunting and often futile — even for experts. Ensemble modeling can take some of that weight off your shoulders and gives you peace of mind that the predictions are the result of a collaborative effort among models trained either from (a) different algorithms that approach the problem from different perspectives or (b) the same algorithm applied to different samples and/or with different tuning parameter settings.
A lot of smart people have formulated algorithms specifically around this concept over many decades – from general bagging and boosting approaches (and the many variants derived from them) to more specific algorithms such as the popular and effective random forest algorithm developed by Leo Breiman and Adele Cutler. These ensemble modeling algorithms give machine learning practitioners powerful tools for generating more robust and accurate models. My colleagues at SAS wrote a great paper describing ensemble modeling in SAS Enterprise Miner. For more on the topic of ensemble modeling, tune in to the webcast, Ensemble Modeling for Machine Learning, where I cover some common applications of ensemble modeling and go into more details on various implementations of ensemble modeling. This webinar is one installment in a series on machine learning techniques – starting with Machine Learning: Principles and Practice, and including other topics such as Principal Component Analysis for Machine Learning and an upcoming one on clustering.






