企業・組織がデータをまとめることに躍起になっている間に、本質を見失っていることが多く見受けられます。 データは手段であり、目的ではありません。
「データ統合」という言葉を、皆さんは何度耳にされているでしょうか。 経営会議で、ITロードマップで、ベンダー提案書で。まるで呪文のように繰り返されるこの言葉に、私はずっと違和感を覚え意義をとなえ続けています。
結論を先に言います。「データ統合」は、そのままでは意味をなさない概念です。 本当に企業が取り組むべきは「意思決定の統合」であり、データはその手段に過ぎません。
1.「データ統合」はそもそも何を指しているのか
実は私はそこをあまりわかっていません。なぜなら私の中にその概念がないためです。ただ世の中での「データ統合」という言葉の使われ方から推察すると、実際には二つの異なる意味で使われているように見受けられます。
💡キーポイント:
「①置く統合」はメッシュアーキテクチャで不要になりつつある。 「②加工の統合」はそれ自体が目的ではなく、意思決定改善という目的への手段に過ぎない。 どちらの解釈においても、「データ統合」は価値あるものとしては定義できない。
2.データは組織を動かさない
Data doesn't drive your organization.
Decisions do.
こちらのブログで詳しくお話していますが、データは組織を動かしません。意思決定が組織を動かします。 これは私が日頃お伝えしているメッセージですが、「データ統合」という言葉が流行するとき、この順序が逆転していることが多いです。
自律型AIエージェント時代の意思決定~ROI創出とリスク管理を「技術」ではなく「意思決定」で整理する
3.「統合データベース」という幻想
仮にデータ統合という意味が正確に定義できなくても明らかに手段であるものではなく、目的志向で、「すべての意思決定モデルを格納した統合データベース」を作ろうとすると、どうなるでしょうか。
企業の中で生まれる意思決定は無数にあります。価格設定、在庫補充、顧客対応、採用、設備投資、与信判断、リスク管理……それぞれの意思決定は、固有のコンテキスト・時間軸・責任者を持ち、互いに複雑に干渉し合っています。
それらすべてを網羅する「統合データベース」などは、私が知る限り現時点では現実的に存在しないですし、仮に存在したとしても、その構築自体がナンセンスだと思います。なぜなら意思決定間の相互作用は、設計段階では分からない部分が多く、実際に動かしてみて初めてわかる側面も大きいからです。
4.意思決定の構造① - 組織の階層構造
企業の意思決定を正しく捉えるには、まずその階層構造を理解する必要があります。
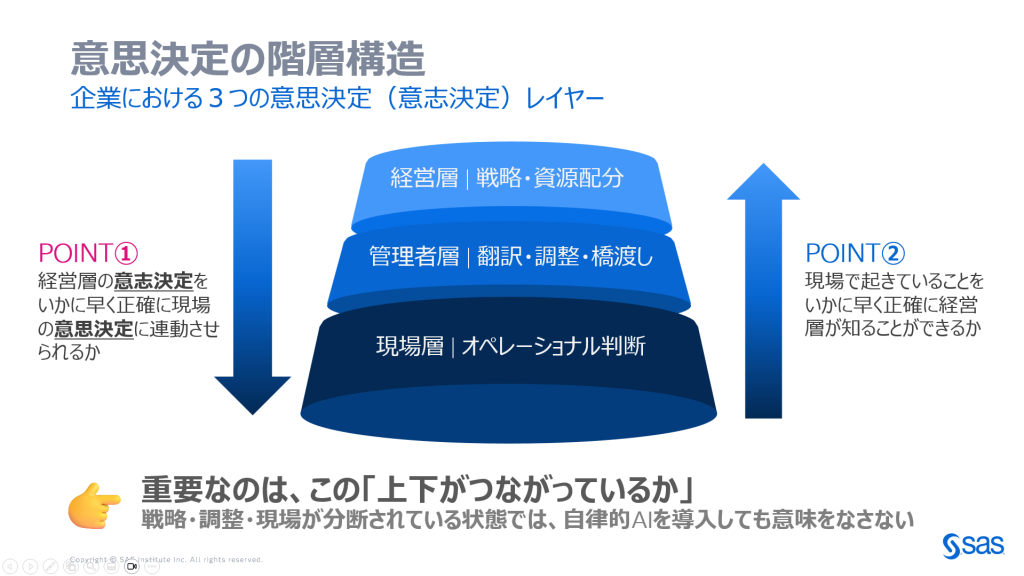
重要なのは、この三層が「つながっているか」です。 経営層の「意志決定」がいかに早く正確に現場の「意思決定」に連動するか。 現場で起きていることがいかに早く正確に経営層にフィードバックされるか。 この双方向の連動がなければ、どれだけデータを集めても、どれだけAIを導入しても、意味をなしません。
💡キーポイント:意思決定と意志決定の違い
「意思決定(Decision-making)」はデータと論理に基づく合理的な選択であり、AIが担える領域。 「意志決定(Commitment)」は責任を持って結果にコミットする判断であり、人間の領域。 データ活用の議論では、この二つが混同されることが多い。
5.「意思決定の統合」こそが本質的なチャレンジ
企業が経営指標を改善するプロセスを整理すると、以下の縦のバリューチェーンが見えてきます。
- 経営層が意志決定をする - 戦略目標・KPI・資源配分を定義し、「何を最適化するか」にコミットする。
- 管理者層が翻訳・調整する - 経営の意図を各部門の言葉と判断基準に変換し、部門間の整合を取る。
- 現場が意思決定をし、バリューチェーン全体で最適化する - 日々のオペレーションの中でデータとモデルを使った判断を実行する。部門をまたがった判断が全体最適につながる。
この縦の連動と横断的な横の連動の最適化こそが、企業にとって本質的に必要なものです。 そして、それを実現するためには「意思決定の統合モデル」が必要であり、それは本質的には関数として表現されなければならないと考えます。
6.意思決定の構造② - 「縦」だけでは足りない - バリューチェーン横断の意思決定連動
階層構造(縦の連動)だけでは、まだ不十分です。 経営層の意志決定は多くの場合、単独の部門だけで完結しません。 マーケティング・製造・物流・サプライチェーン・顧客サービスといった複数の部門にまたがるバリューチェーン全体の意思決定が連動して初めて、経営の意図が現実の成果に変わります。
ところが実際には、各部門が自部門の指標を最適化しようとするあまり、バリューチェーン全体が悪化するという現象が頻発したり、あるいはそもそもその全体視点で評価ができなかったり、説明できない企業がほとんどです。以下はよくある典型的なパターンです。
📣キャンペーン × 製造・物流の非連動
マーケティング部門がキャンペーンを打ち、需要が急増。売上目標は達成した。しかし製造・物流のキャパシティが追いつかず、顧客への到着が遅延。顧客満足度が低下し、リピート率が落ちた。マーケティングの「意思決定」は局所的には正しく、全体としては誤りだった。
🚚サプライチェーン拠点の「良かれ」在庫削減
ある拠点が在庫コスト削減のために在庫を圧縮した。その拠点の財務指標は改善した。しかしサプライチェーン全体のバッファが失われ、別拠点での欠品が連鎖し、全体のフルフィルメント率・レジリエンス指標が低下した。拠点最適が全体最悪を招いた。
これらの失敗に共通するのは、各部門の意思決定関数が独立していることです。それぞれが自部門のデータだけを見て、自部門の目的関数だけを最適化する。するとバリューチェーンの中で「部分最適の合算が全体最悪」という状況が生まれます。
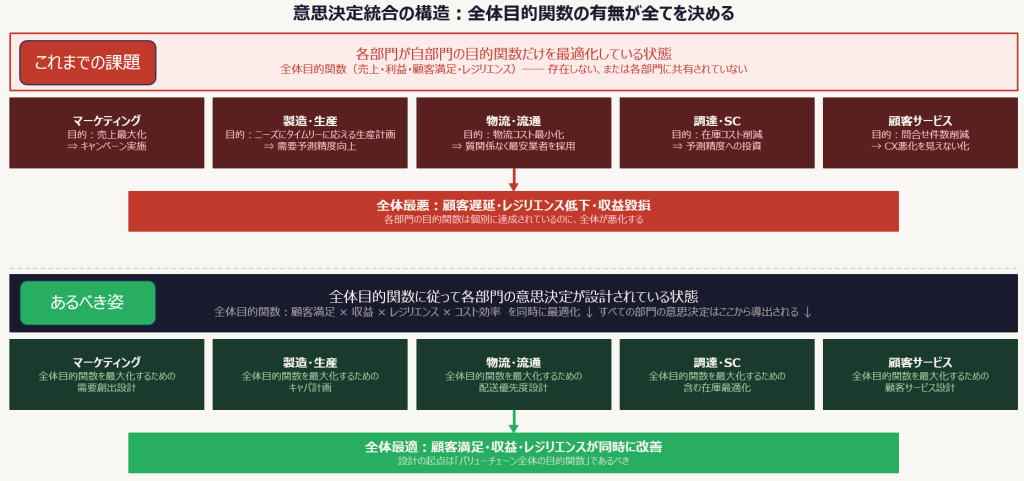
全体最適を実現するには、意思決定関数を各部門ごとに作るのではなく、バリューチェーン全体を最適化するよう設計されなければならない。 マーケティングや営業活動も、倉庫の在庫オペレーションも、需要予測も、サプライチェーン全体の健全度・レジリエンス指標を目的関数としなければならないです。 これが「バリューチェーン横断の意思決定連動」- 意思決定の水平統合です。
💡整理:意思決定統合の二軸
縦軸(階層連動):経営の意志決定 → 管理者の翻訳・調整 → 現場の実行判断、そのフィードバック
横軸(バリューチェーン連動):部門は、自身に閉じた目的関数ではなく、全体目的関数を最適化する行動をとる
この縦と横が交差してはじめて、「意思決定の統合」は完成する。
6.深掘り事例:「需要予測の精度向上」という甘い罠
バリューチェーン横断の意思決定連動が欠如したとき、何が起きるでしょうか。 サプライチェーンの現場で頻繁に見られる、ある典型的な構図を取り上げます。
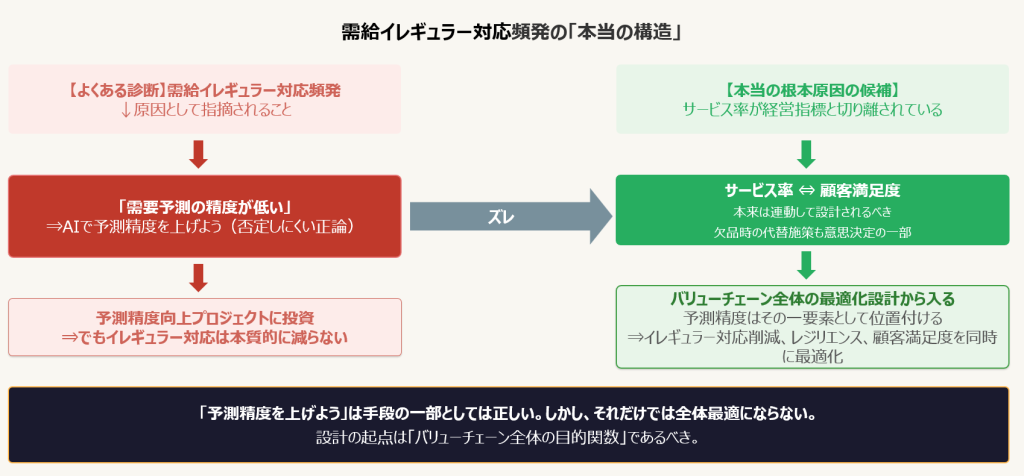
よくある診断:需給イレギュラー対応業務は「予測精度を高めたら改善する」
サプライチェーンにおいて、需給のズレによる急な在庫融通・輸送調整――いわゆる需給イレギュラー対応が頻発していたとします。 この問題を「なぜ起きているのか」と問うと、データサイエンティストから返ってくる答えはほぼ決まっています。
「需要予測の精度が低いからです。AIで精度を上げれば解決します。」
この主張は、否定しにくいのが罠の始まりです。予測は確かに重要です。精度が高い方がいいのは論理的に正しいです。こうして「予測精度向上プロジェクト」に予算と時間が投下されます。 それ自体を検討することは間違いではありませんが、本当にそれが問題の根本原因なのでしょうか?需要のパターンによっては説明変数で十分説明できないパターンが実は全体商品の中で多くを占めることが多く、一部の需要パターンにオーバーフィッティングさせれば精度は出たりしますが、取り扱い商品が多岐にわたる企業ではそれはビジネスとしてスケールしません。POC倒れの典型になります。
これが、私が「見かけの正論の罠(Plausible Trap)」と呼ぶ現象です。 否定できないがゆえに思考停止を招き、より大きな問題を見逃し、本質的な議論をする機会を失ってしまいます。
別の原因仮説:安全在庫の「サービス率」設定の問題
需給イレギュラー対応が頻発する原因は、予測精度だけではありません。 見落とされがちな原因の一つが、安全在庫のサービス率設定だ。率の値そのものではなく、サービス率の概念そのものです。
💡サプライチェーンにおけるサービス率とは
在庫が欠品せずに顧客需要を満たせる確率の目標値。たとえばサービス率95%とは、100回の需要のうち95回は在庫から即応できるよう設計することを意味する。サービス率を高く設定するほど安全在庫量は増え、低く設定するほど欠品リスクが上がる。
ここに重要な問いがあります。サービス率は何を根拠に設定されているか? 多くの企業では、現場のサプライチェーン担当者が設定しており、顧客満足度・収益性・レジリエンスといった経営指標と明示的に連動していないことが多いです。
つまり、需給イレギュラー対応の頻発は「予測が外れたから」ではなく、「サービス率の設定が経営目標と切り離されているから」という別の根本原因を持ちえるということです。 この場合、予測精度をどれだけ上げても、需給イレギュラー対応は本質的には減りません。
さらに深く:サービス率と顧客満足度の再設計
ここで発想の転換が生まれます。サービス率(在庫即応率)は、本来顧客満足度と連動して設計されるべき意思決定なのですが、満足度=即引当率という短絡的な思考になりがちなので注意が必要です。
仮に商品がすぐ届かなくても、その待ち時間に試供品・代替品・特別クーポンを提供するという選択肢があります。 これは単なる「お詫び対応」ではありません。欠品という状況を新たなセールスオポチュニティに変える意思決定です。 顧客は「早く届くこと」だけに満足するのではなく、「丁寧な対応と付加価値」すなわちトータル価値に満足します。
これを実現するためには、在庫・物流の意思決定と、顧客対応・マーケティングの意思決定がバリューチェーン横断で連動しているだけでなく、バリューチェーン全体での評価指標を持つ必要があります。 サービス率の設定という一見「物流の話」が、実は顧客体験・収益・ブランドにまたがる経営判断なのです。
💡この事例が示す構造的教訓
① 見かけの正論に気をつけよ:「予測精度を上げよう」は否定しにくいがゆえに、より本質的な問いを閉じてしまう。Data & AIへの投資が局所最適に流れる典型的な好ましくない状況。
② 問うべきは「どの意思決定が、何と連動しているか」:需給イレギュラー対応の根本原因は、在庫設計と顧客満足度が切り離された意思決定構造にあるという例
③ 全体最適の設計が先:バリューチェーン全体の目的関数(顧客満足・収益・レジリエンス・コスト)を定義してから、その一要素として予測精度向上を位置づけることが重要で、逆ではない。
7. 意思決定モデルを「関数」として設計する
意思決定の統合モデルを構築することは、突き詰めればビジネスプロセスの設計です。 大きく二つの意思決定を、入力(データ・コンテキスト)を受け取り、出力(判断・アクション)を返す関数として定義することになります。
1.バリューチェーン全体(縦 and/or 横)の関数
2.バリューチェーン全体の関数のパラメータとなる個々の部門の意思決定関数
この関数の設計には二つのアプローチがあります。

重要なのは、この二つは対立しないということです。設計が先で、データはその改善手段です。 意思決定の関数を先に定義してからこそ、「どのデータが必要か」「何を測定すべきか」が決まります。 逆ではありません。
意思決定の統合なくして、
データの統合はない。
8. 企業が今すぐ問い直すべき問い
「データ統合プロジェクトを進めている」という企業に、私はいつも同じ問いを投げかけます。
❔根本的な問い
「そのデータ統合の先で、誰の、どの意思決定が、どのように改善されますか?」
もし即座に答えられないなら、その統合プロジェクトはまだ目的を持っていないことになります。
本来の問いの立て方はこうです。
- 改善すべき意思決定を定義する「何の判断を、どう変えると、どの経営指標が動くか」を先に特定する。
- その意思決定に必要なデータ・モデルを逆算する意思決定の「関数」が決まれば、必要な入力(データ)は自然に定まる。
- 縦と横の連動設計をする経営・管理・現場の三層(縦軸)と、バリューチェーンを構成する部門間(横軸)の両方が同じ目的関数の下でつながるよう、プロセスとガバナンスを設計する。
- 動かしながら学習させる設計通りにいかない部分は必ず出る。データに基づくインサイトを意思決定関数に継続的に反映する。
まとめ
「データ統合」は、それ自体では目的になり得ません。 データを置く場所を統一することは、メッシュアーキテクチャの前では意味を失いつつあります。 データを結合・加工することは、あくまで意思決定改善への手段です。
本当に問うべきは「どの意思決定を、どう変えるか」です。 経営・管理・現場という三層の意思決定が連動し、部門をまたぐバリューチェーン全体が最適化される構造ーそれが「意思決定の統合」であり、データドリブン経営(ほんとうは、ディシジョンドリブン経営)の本質です。
データはその統合された意思決定モデルへの入力として機能するとき、初めて企業価値に変わります。 データが先ではなく、意思決定の設計が先なのです。
「何のデータを集めるか」を考える前に、
「何を決め、何を変えるか」を決めよ。
