It’s been an amazing journey with Hadoop.
As we discussed in an earlier blog, Hadoop is informing the basis of a comprehensive data enterprise platform that can power an ecosystem of analytic applications to uncover rich insights on large sets of data.
With YARN (Yet Another Resource Negotiator) as its architectural center, this data platform now enables multiworkload data processing across an array of methods, from batch through interactive to real time. And it’s supported by the key capabilities enterprise data platforms need – governance, security and operations.
Back in 2008, the Hadoop community started to discuss how to move Hadoop beyond batch applications with MapReduce. This eventually led to YARN. The idea then was to give users access to data in many forms concurrently, similar to what a basic operating system would provide.
If you go back in history to examine early operating systems, the basic premise was that the most contentious or scarce resource was hardware (memory, disk and so on). In that era, computers needed a piece of software to manage those resources across users and applications.
Fast forward to 2015. Today, we tend to not worry as much about hardware resources because we can pull together commodity hardware, both storage and compute, into scale-out systems otherwise known as clusters. And while hardware is crucially important to data architectures, the most important resource in today’s modern architecture is data. That’s why the notion of a data operating system is so important. The operative word here is data, not operating system.
When we set out to build Hadoop 2.0, we wanted to fundamentally re-architect Hadoop to be able to run multiple applications against relevant data sets. And we wanted to do so in a way that would allow multiple types of applications to operate efficiently and predictably within the same cluster. This is really the reason behind Apache YARN, which is foundational to Hadoop 2.0.
We’ve completed our data operating system with: storage (Apache HDFS/Apache HBase); metadata management (Apache Atlas) and data governance (Apache Falcon); security (Apache Ranger/Apache Knox); operations (Apache Ambari); and user APIs (Apache Hive, Apache Pig, Apache Spark, Apache Flink, et al.). At Hortonworks, we bring this data operating system to market as Hortonworks Data Platform (HDP).

Figure 1: Apache YARN architecture.
YARN plays a key role in turning Hadoop from a single application system into a multi-application data operating system. YARN also extends the power of Hadoop to incumbent and new technologies found within the data center so that they can take advantage of cost-effective, linear scale storage and data processing.
Now we have taken another exciting step in our joint journey with SAS, which involves integrating SAS® Grid Manager for Hadoop with the YARN resource manager. This will allow SAS jobs to run as first-class citizens in the Hadoop cluster, coexisting and sharing cluster resources with other YARN enabled workloads running Hadoop and third-party YARN enabled applications.
SAS is an innovator in the Hadoop community – and with the latest release, SAS is moving even more of its architecture onto YARN and into Hadoop. SAS® Grid Manager, SAS® Visual Analytics and SAS® High-Performance Analytics are all distributed technologies that run on a cluster of computers.
Although these three products are different in many ways, SAS has integrated each with YARN to coordinate their resource usage when running on a shared Hadoop environment. This allows you to install these products in a shared Hadoop cluster and use YARN as their overarching resource manager. For all three products, workloads will coordinate with other YARN-managed workloads. And when using YARN integration, you can manage and monitor these products like other YARN applications.
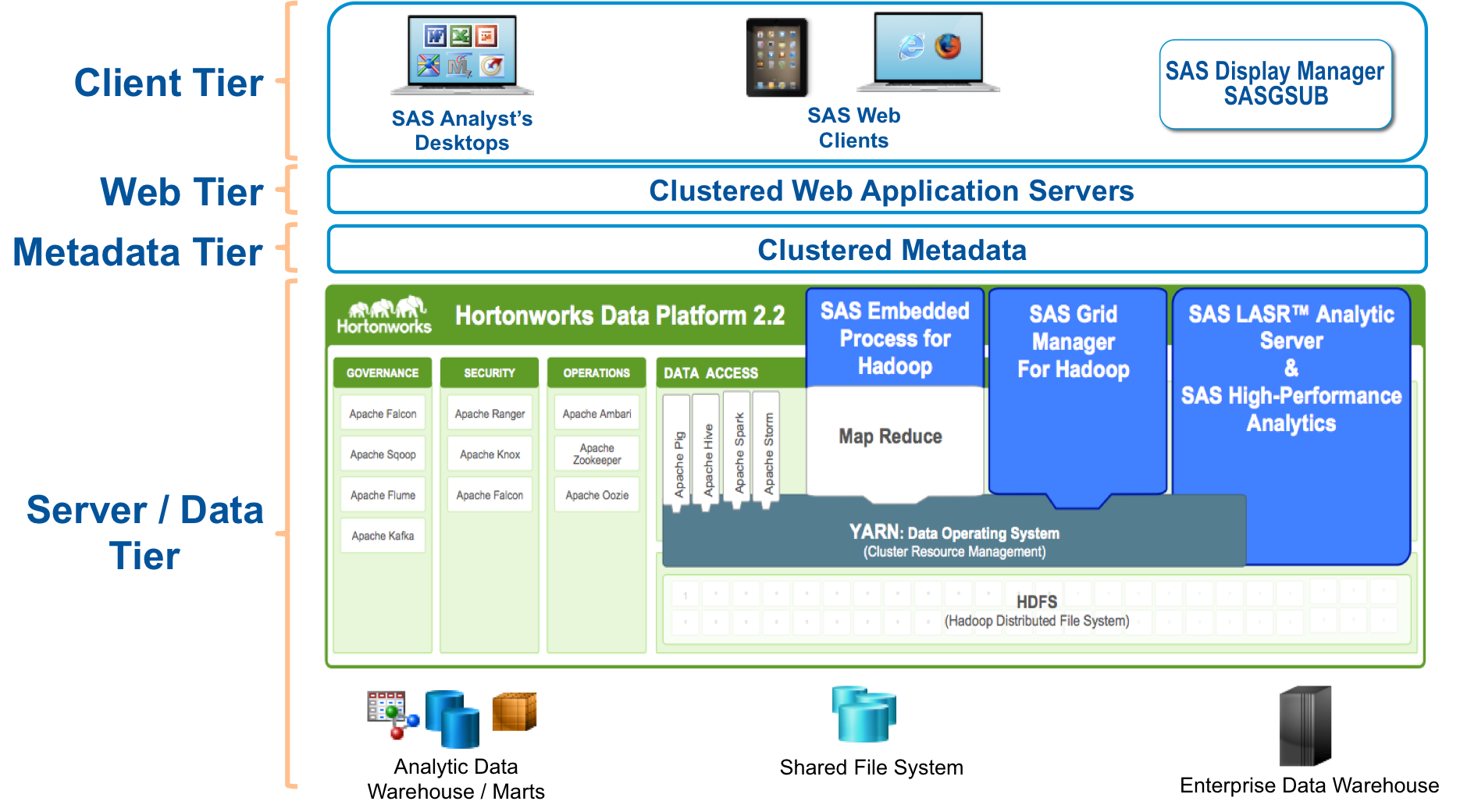
Figure 2: SAS and Hortonworks for the Enterprise.

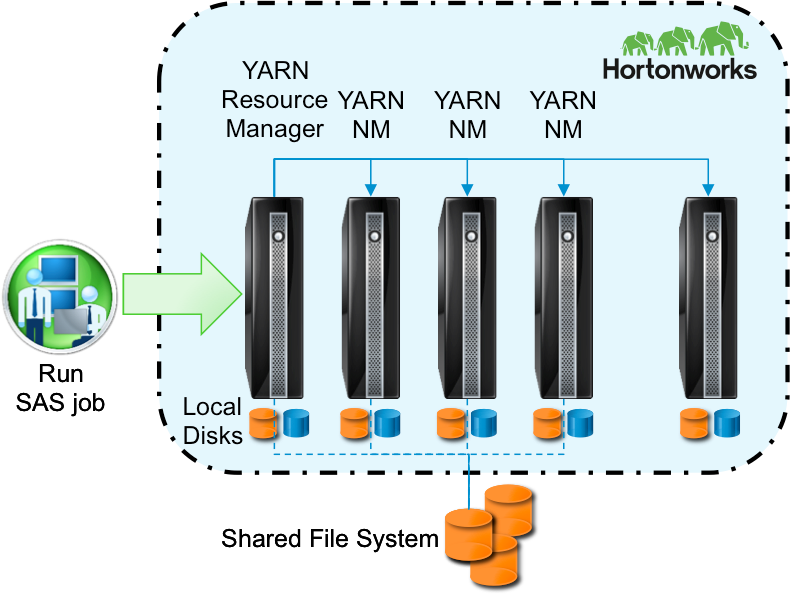
Figure 3: SAS Grid Manager for Hadoop "with" (top) and "in" (bottom) Hortonworks Data Platform.
By integrating SAS Grid Manager with Hadoop YARN, our mutual customers can now:
- Run SAS workloads in the Hadoop cluster, doing analysis where the data is (within the data lake).
- Make use of a unified platform for analysis of SAS applications against the shared data lake. Users can prioritize and schedule SAS workloads in the Hadoop cluster with other workloads, based on business needs.
- Use resources more efficiently and predictably across a variety of SAS workloads, according to shared workload management policies.
- Enforce shared security, governance and operations policies across SAS workloads, alongside other applications being managed.
Summary
With YARN already turning Hadoop into the de facto data operating system, the engineering partnership between SAS and Hortonworks continues to drive value for enterprises that adopt the modern data architecture. Ongoing joint research and development between the two companies helps ensure that customers who adopt Hadoop will experience consistent operations, scalability and security. All while turning their data into valuable insights through the power of SAS.
Next steps
Hortonworks will be at Strata New York September 29 – October 1. Come meet us there to learn more about our partnership. In the meantime, I encourage you to learn more about Hadoop YARN and how ISVs are building YARN Applications on Hadoop.






