For Hadoop to be successful as part of the modern data architecture, it needs to integrate with existing tools. This integration allows you to reuse existing resources (licenses and personnel) and is typically 60% of the evaluation criteria for integration of Hadoop into the data center. One of the most important tools in many data architectures are the analytics tools, and SAS is a major leader in this space.
Guided by our joint customers deployment models for big data and by working with SAS engineering teams since 2013, we identified a few key primary integration patterns. These patterns are centered around exploiting the inherent scale-out compute and storage capabilities of Hadoop to enhance the richness of SAS analytics.
So far, we have provided connectivity options that address the movement of data and compute between discrete SAS and Hortonworks Data Platform clusters. These options such as SAS access capabilities facilitate widely used analytic workloads that can tolerate the inherent latency overhead of standalone clusters.
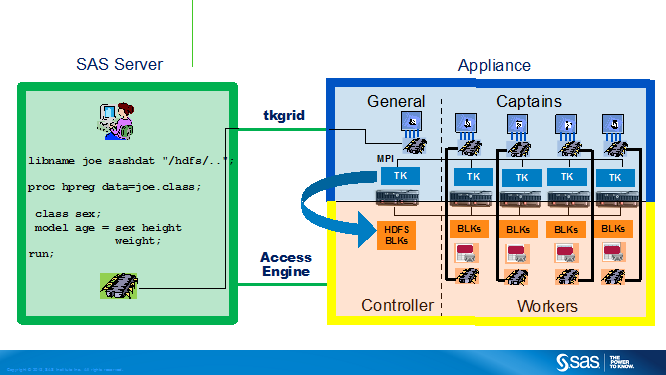
SAS has launched a number of new high-performance analytics (HPA) and in-memory applications that break new ground in fields like statistics, econometrics, optimization, data mining, text mining and forecasting. These high-performance and in-memory optimized workloads have both batch (HPA procedures) and multi-user long-lived (LASR) characteristics to support different usage scenarios. These new applications for complex math as well as real-time and iterative analytics require massive parallelism as well as local data access to meet their performance goals.
While massive parallel clusters can be deployed separately for compute-intensive workloads, local data access is only possible if LASR and HPA coexist with the Hadoop data nodes. This translates to the need to push SAS compute engines directly to the Hadoop cluster, comprising our latest integration pattern.
Apache Hadoop YARN was introduced in Apache Hadoop 2.0 as the architectural center for Apache Hadoop 2. The goal for YARN is to enable diverse application workloads with varying characteristics such as batch, interactive, real-time streaming, statistical analysis and more on a single Hadoop cluster. This enables a modern data architecture without the need for fragmented processing clusters for each workload.
We wrote then: “As the data operating system of Hadoop 2, YARN breaks down silos and enables you to process data simultaneously across batch, interactive and real time methods. It is the prerequisite for Enterprise Hadoop, providing resource management and an architectural center that delivers consistent operations, security, and governance tools across Hadoop workloads. YARN also extends the power of Hadoop to incumbent and new technologies found within the data center so that they to can take advantage of cost effective, linear scale storage and data processing.”
We are very excited today to announce the next step in our joint journey achieved by integrating SAS HPA and LASR with the YARN resource manager so it will run as a first class citizen in the Hadoop cluster, co-existing and sharing cluster resources with other YARN enabled workloads running Hadoop and third-party YARN enabled applications.
With this milestone, we warmly welcome SAS LASR to a growing community of YARN Ready applications.
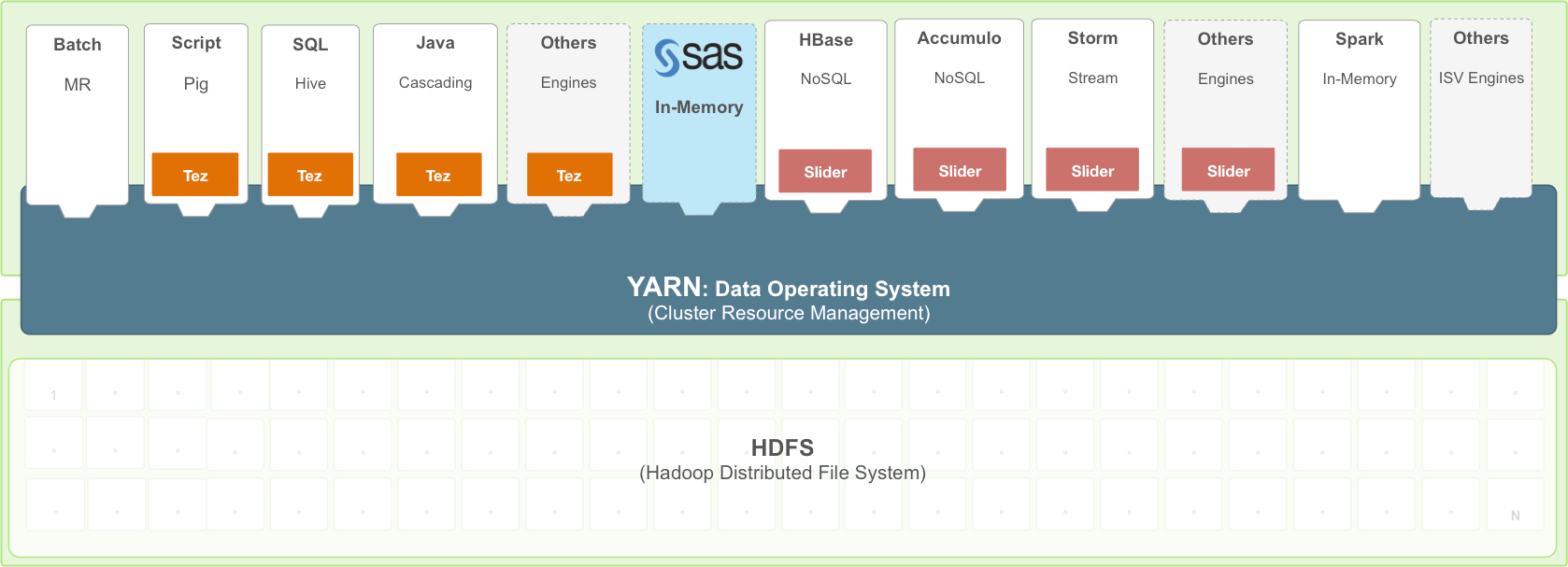
By integrating SAS HPA and LASR with Hadoop YARN, our mutual customers can now benefit from:
- Predictable resource management for co-existing Hadoop workloads and SAS high-performance workloads.
- Low-latency local data access directly from the data nodes.
- Unified Resource Management window-pane for managing SAS HPA, LASR and HDP resources.
Next Steps
Our experience in this integration has triggered additional thoughts on how we can look at extending this integration in the future to make it meet your future needs. We are looking into some exciting new directions that we will share as our plans mature. One such area evoking active discussion in the Hadoop community is how to provide fine-grained workload management in addition to resource management through YARN.
Summary
Integrating SAS HPA and LASR with Apache Hadoop YARN provides tremendous benefits to customers using SAS products and Hadoop. It is a great example of the tremendous openness and vision shown by SAS and how Hadoop YARN is clearly becoming the de-facto data operating system in the big-data world.
We hope you will join us on this exciting journey! And learn more about the Modern Data Architecture.

4 Comments
Pingback: Hadoop Happenings: Getting Started with Data Analytics | Qubole
Thanks Arun. What is the integration framework for HPA and LASR as referred to in the Hortonworks link below. If you can elaborate on the approach, that would be great. Clients with Hadoop appliance investments from different vendors are somewhat hesitant to consider colocating LASR and/or HPA on the same cluster due to support concerns.
"The first step is to determine the appropriate integration framework for your application. If it uses YARN natively, or uses a YARN framework (e.g. Apache Tez, Apache Slider, etc.), you’re well on your way. If it does not use YARN — e.g. it reads directly from HDFS — you’ll want to look into the expanding number of approaches that allow you to move to a YARN-based application..."
More...
http://hortonworks.com/partners/yarn-ready/
Hi
What kind of data warehouse application is suitable for Hive?
can you please help me out
Thanks for such an informative post! YARN combines a central resource manager that reconciles the way applications use Hadoop system resources with node manager agents that monitor the processing operations of individual cluster nodes. Running on commodity hardware clusters, Hadoop has attracted particular interest as a staging area and data store for large volumes of structured and unstructured data intended for use in analytics applications. Separating HDFS from MapReduce with YARN makes the Hadoop environment more suitable for operational applications that can't wait for batch jobs to finish. More at http://www.youtube.com/watch?v=1jMR4cHBwZE