All Posts


I often get asked for programming tips. Here, I share three of my favorite tips for beginners. Tip #1: COUNTC and CATS Functions Together The CATS function concatenates all of its arguments after it strips leading and trailing blanks. The COUNTC function counts characters. Together, they can let you operate


Jim Harris says learn the lineage of the data that fed the analysis before you get dazzled by visualizations or algorithms.


The solar farm at SAS world headquarters is a treasure trove of data. Jessica Peter, Senior User Experience Designer at SAS, had an idea about using that treasure in an art installation to show how data can tell a story. Her idea became a reality when she and others at SAS


En lo que a edad se refiere, yo podría ser su padre y si nos estiramos un poco, de algunxs hasta su abuelo. Millennials. Tratan de romper con cadenas que les legamos. Tienen pareja o compañerx, la palabra novio o novia está desterrada. Estudiosxs, curiosxs, esponjas de conocimientos y de


Hearing someone talk about why they love their job is palatable when you have to make small talk at a cocktail party. But why spend your free time reading about why someone loves their job? Well, when you hear firsthand about how people are helping track endangered species using the


모델 리스크 관리(MRM; Model Risk Management)는 새로운 주제가 아닙니다. 금융 기관은 이미 수십 년 전부터 의사결정 과정에서 모델을 활용해왔는데요. 최근 들어 MRM 관련 규제가 한층 더 형식화되고 엄격해지면서 관심이 커지고 있습니다. 유럽은행감독청(EBA; European Banking Authority)의 TRIM(Targeted Review of Internal Models)과 같은 규제는 은행에 모델 관리 컴플라이언스를 위한 더 큰 노력을
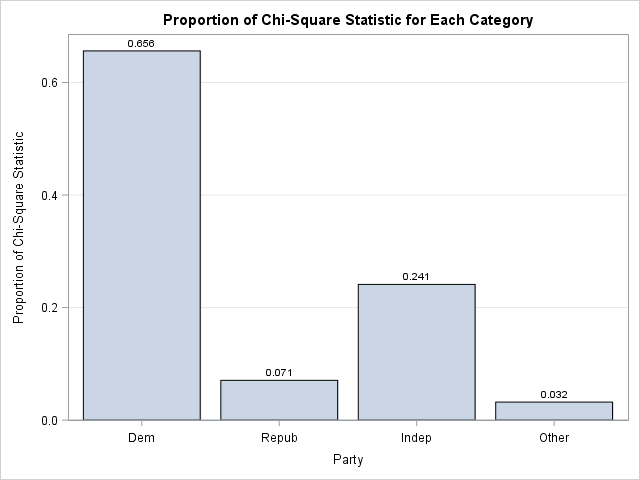

Programmers on a SAS discussion forum recently asked about the chi-square test for proportions as implemented in PROC FREQ in SAS. One person asked the basic question, "how do I test the null hypothesis that the observed proportions are equal to a set of known proportions?" Another person said that


En un mundo que a diario se transforma con los datos y los avances tecnológicos, cada vez son más las organizaciones que están adoptando la Analítica y la Inteligencia Artificial para fortalecer sus procesos y entregar mejores resultados a sus clientes. Este escenario no es ajeno al sector gobierno, que


About two-thirds of the way through her Analytics Experience presentation, Dr. Tricia Wang showed a video from Frans de Waal, a world-renowned primatologist. The video showed two monkeys receiving rewards for giving a researcher a rock. Each time a monkey handed over a rock it received a piece of cucumber.
En la actualidad, se ha masificado el uso de la Inteligencia Artificial (IA) en diferentes aplicaciones de negocio como: los servicios de atención al cliente y la toma de decisiones operativas en diferentes áreas de las empresas, consiguiendo optimizar múltiples procesos, al hacerlos más eficientes y logrando una mayor rentabilidad.


The Grand Buddha at Ling Shan, located on the northern bank of Taihu Lake near Wuxi, China is a fitting metaphor for smart city initiatives in China, specifically Wuxi in the Jiangsu Province in Eastern China. One of the largest Buddha statues in the world, the bronze monument reaches 88
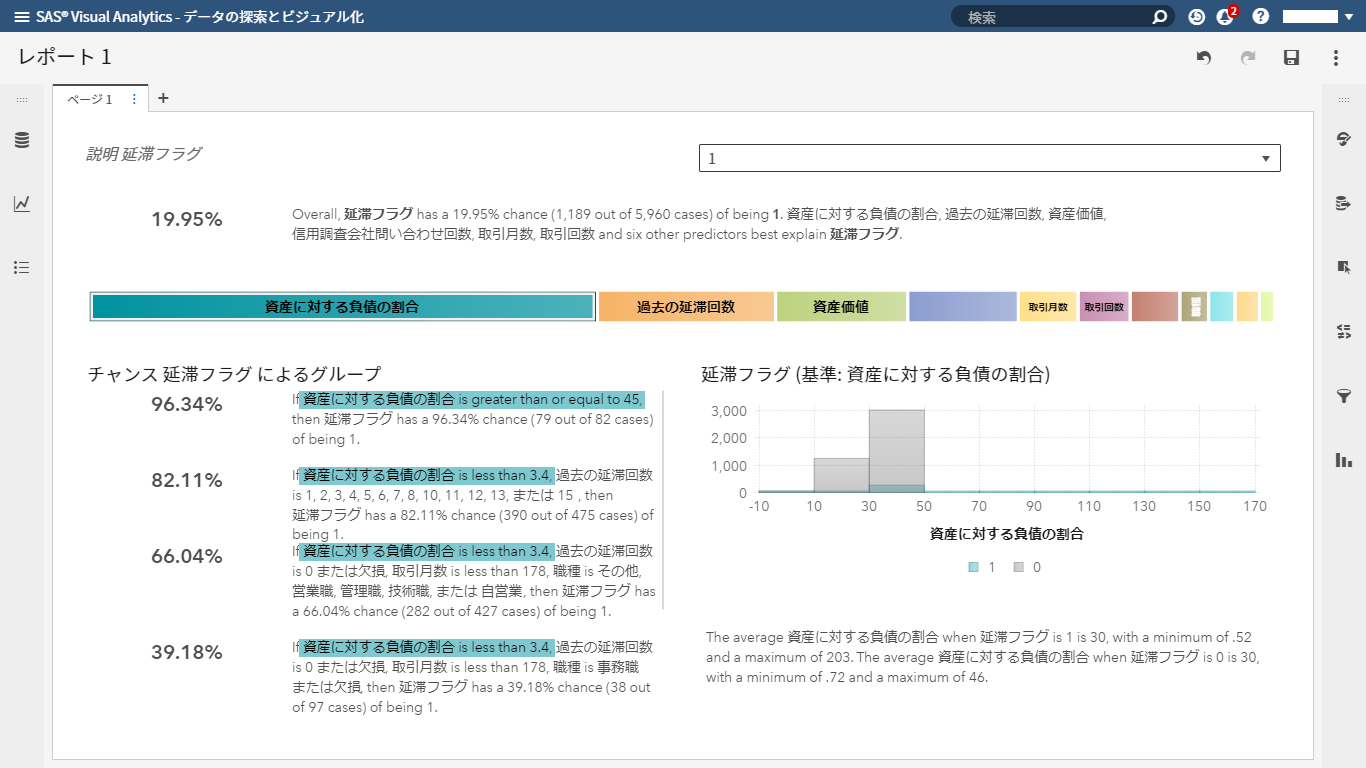

AIプラットフォームSAS Viyaでは、「AI実用化」や「AI民主化」を促進するために、従来から自動予測モデル生成や、機械学習やディープラーニングの判断根拠情報の提供などを可能としていましたが、SAS Visual Analytics on SAS Viyaの最新版8.3では、新たに「自動分析」機能が実装されました。 「自動分析」機能を使用すると、予測(ターゲット)に影響を与えている変数の特定や、変数ごとにどのような条件の組み合わせがターゲットに依存しているのかを「文章(条件文)」で表現して教えてくれます。 この例で使用するデータ「HMEQJ」は、ローンの審査を題材にしたもので、顧客ごとに1行の横持ちのデータです。このデータ内にある「延滞フラグ」が予測対象の項目(ターゲット変数)で、0(延滞なし)、1(延滞あり)の値が含まれています。 データリスト内の「延滞フラグ」を右クリックし、「分析」>「現在のページで分析」を選ぶだけで、「延滞フラグ」をターゲット変数に、その他の変数を説明変数とした分析が自動的に行われ、 以下のような結果が表示されます。 分析結果画面内説明: ① ドロップダウンリストで、予測対象値(0:延滞なし、1:延滞あり)の切り替えが可能です。この例では、「1:延滞あり」を選択し、「延滞する」顧客に関して分析しています。 ② 全体サマリーとして、すべての顧客の内、延滞実績のある顧客は19.95%であり、「延滞する」ことに関して影響度の高い変数が順に表記されています。 ③ 「延滞する」ことに関して影響を与えている変数の度合い(スコア)を視覚的に確認することができます。 ④ 「延滞する」可能性が最も高くなるグループ(条件の組み合わせ)が文章で示されています。この例では、③で「資産に対する負債の割合」が選択され、これに応じて文章内の該当箇所がハイライトしています。 ⑤ この例では、③で「資産に対する負債の割合」が選択され、これに応じて「0:延滞なし、1:延滞あり」別の顧客の分布状況がヒストグラムで表示されています。選択された変数が数値属性の場合は、ヒストグラムで、カテゴリ属性の場合は積み上げ棒グラフで表示されます。 分析に使用する説明変数(要因)に関しては、右側の「データ役割」画面内で選択することができます。 以上のように、分析スキルレベルの高くないビジネスユーザーでも、簡単かつ容易に、そして分かり易くデータから有効な知見を得ることができます。 ※AIプラットフォーム「SAS Viya」を分かり易く学べる「特設サイト」へGO!
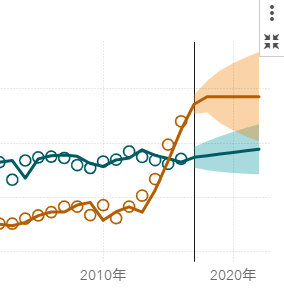
これまでのSAS Visual Analytics 活用例では、一時点のデータを表やグラフに示し、分析していましたが、統計データには毎年、毎月や四半期ごとに集計されているものが多くあります。そこで今回はデータのなかに時間情報が存在する時系列データの操作について説明します。 時系列データには国や地方自治体が公表しているデータに加え、気象情報、商品の売上、株価、為替レートなど様々なデータがあります。時系列データを利用することで、過去の傾向やパターンを把握したり、将来はどうなるのか予測することができます。SAS Visual Analytics のオブジェクトには、時系列データではないと作成できないものがあり、その中でも今回は、二軸の時系列プロットと予測の利用例を説明します。 このスライドでは、日本政府観光局(JNTO)が公開している「年別 訪日外客数・出国日本人数・国際旅行収支(IMF方式)の推移」を利用しました。このファイルには、1959年から2016年までの年ごとの訪日外客数、出国日本人数とその伸び率、国際旅行収支のデータがあります。データのインポートについてスライド内でも説明していますが、インポートの際の注意点など詳細に関してはこちらのブログを参考にしてください。 SAS Visual Analytics 8.3 における時系列データの利用 from SAS Institute Japan 予測オブジェクトでは、自動的に最適な予測モデルが選択されます。オブジェクトを最大化し、詳細を表示すると使用された予測モデルを確認することができます。 スライド内の予測では、ARIMAが使用されていました。 また、データ役割からWhat-If 分析を選択すると、シナリオ分析とゴール探索を実行することができます。シナリオ分析では、要因の値を設定することで、予測値がどれくらい変化するかを確認できます。ゴール探索では、予測の目標値を設定することで、その目標を達成するために必要な要因の値を決定することができます。 今回スライド内で紹介したほかに時系列データを利用するオブジェクトとしては、時系列プロットと比較時系列プロットがあります。作成したオブジェクトを右クリックするとメニューが表示されるのでそこから変更することができます。 引き続き本ブログのシリーズでは、図表・グラフの作成や統計解析の方法について紹介いたします。 第2回和歌山県データ利活用コンペティションへの参加も募集中ですので、高校生・大学生のご参加をお待ちしています。(追記:募集は締め切られました)

고객 인텔리전스(CI)를 위한 챗봇 이미 많은 기업들이 인공지능(AI)으로 비즈니스를 자동화하고, 더 나은 고객 경험을 제공하며, 매출을 높이고 있습니다. 이미 수년 전부터 은행은 인공지능을 활용해 잠재적인 금융 사기를 탐지하고, 통신사는 고객 이탈을 예측해왔는데요. 챗봇은 한 단계 더 나아가 인공지능을 일상 가까이로 가져왔습니다. 챗봇은 머신러닝, 딥러닝, 음성 인식(voice-to-text), 자연어처리(NLP), 추천 엔진 등 여러
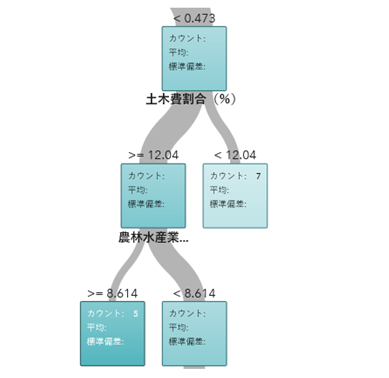
本ブログのシリーズでは、SAS Visual Analyticsを用いた図・グラフの作成や統計解析についてご紹介しています。第5回目となる今回は、ディシジョンツリーを用いた分析方法をご説明します。 第1回和歌山県データ利活用コンペティション:大学生の部の課題は「人口減少問題を解決するための施策」でした。前々回の記事では、各自治体の行政基盤が人口増減率に与える影響を線形回帰を用いて評価しました。この手法は説明変数の与える影響の大きさを定量的に評価できるものの、各説明変数間の関係の読み取ることは困難でした。そこで本記事では同じ題材を用いて「ディシジョンツリー」による分析方法をご説明します。ディシジョンツリーでは、各説明変数が目的変数に及ぼす影響を階層ごとに分析することができます。 前々回の記事と同じく、総務省の「社会・人口統計体系 都道府県データ 社会生活統計指標 :D 行政基盤」と「人口推計:都道府県別人口増減率-総人口」のデータを使用しました。 SAS Visual Analytics 8.3 におけるディシジョンツリーの利用 from SAS Institute Japan 今回の分析において、人口増減に最も大きな影響を与える要素は「財政力指数」でした。都市部など財政力が強い地域の人口が増加しやすいことは感覚的に自然な結果でしょう。 注目すべきは、財政力指数が低い自治体において次に大きな影響を与える要素が「土木費割合」であったことです。無論インフラの整備は市民の暮らしやすさに欠かせない要素ですが、人口増加につながる理由としては、「公共事業による雇用の創出」と捉えることが適切でしょう。今回は行政基盤のみを説明変数に設定しましたが、有効求人倍率や最低賃金等、市民の生活や労働に関連する要素を説明変数に据えることで、より詳細な分析が可能であると予想されます。第一回和歌山県データ利活用コンペティションのサイトにこのテーマに関する優秀作品が掲載されておりますので、ご参照ください。 ディシジョンツリーによる分析は、説明変数が目的変数に及ぼす影響や各説明変数間の関係が理解しやすいというメリットがありますが、モデル作成時に用いたデータに過剰適合し汎化性能が低いというデメリットもあります。目的に応じてツリーの枝数や階層数を適切に調整するようにしましょう。 以上、ディシジョンツリーを用いた分析手法についてご説明しました。本ブログのシリーズの他の記事もぜひご参照ください。 第2回和歌山県データ利活用コンペティションへの参加も募集中ですので、高校生・大学生のご参加をお待ちしております。(追記:募集は締め切られました)