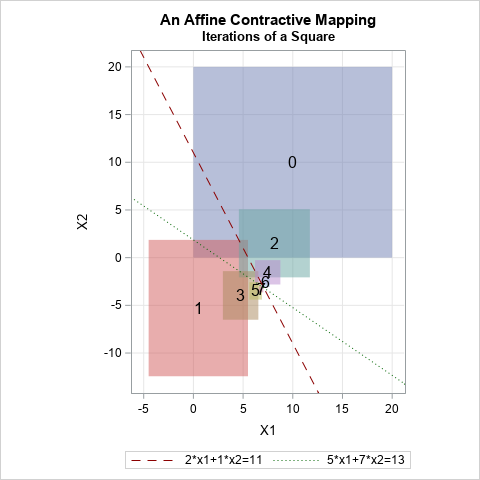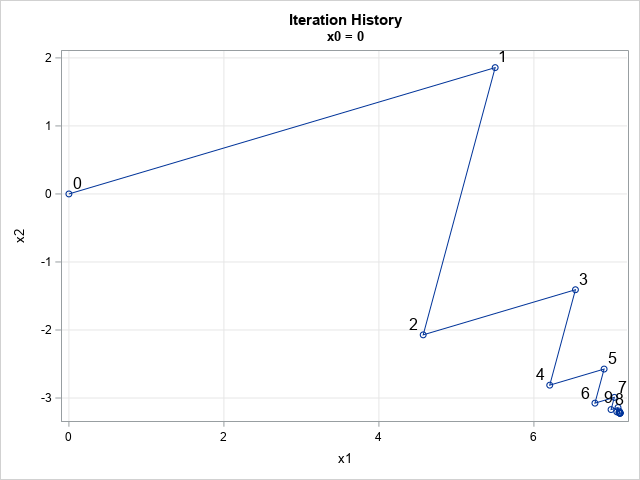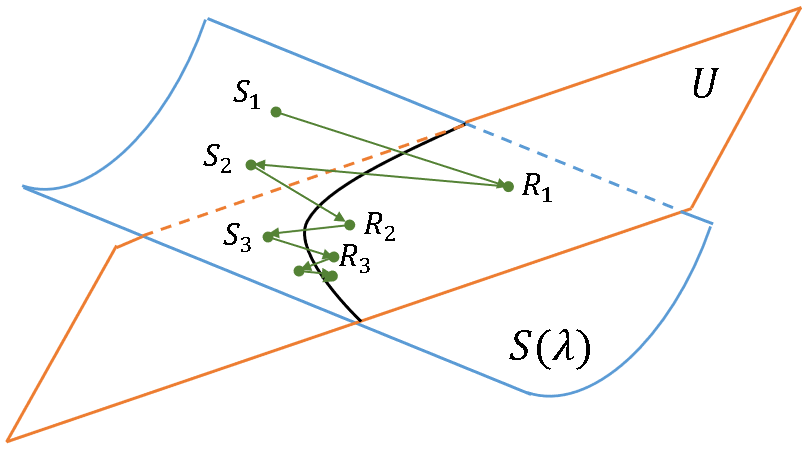
Generate correlation matrices with specified eigenvalues

A previous article discusses how to generate a random covariance matrix with a specified set of (positive) eigenvalues. A SAS programmer asked whether it is possible to produce a correlation matrix that has a specified set of eigenvalues. After discussing the problem with a friend, I am happy to report