
Optimization for machine learning is essential to ensure that data mining models can learn from training data in order to generalize to future test data. Data mining models can have millions of parameters that depend on the training data and, in general, have no analytic definition. In such cases, effective models with good generalization capabilities can only be found by using optimization strategies. Optimization algorithms come in all shapes and sizes, just like anything in life. Attempting to create a single optimization algorithm for all problems would be as foolhardy as seeking to create a single motor vehicle for all drivers —there is a reason we have semi-trucks, automobiles, motorcycles, etc. Each prototype is developed for a specific use case. Just as in the motor vehicle world, optimization for machine learning has its super stars that receive more attention than other approaches that may be more practical in certain scenarios, so let me explain some ways to think about different algorithms with an analogy related to my personal experience with monster trucks.
My son fell in love with monster trucks sometime after he turned two years old. He had a favorite monster truck that he refused to put down, day or night. When he turned two, I unwisely thought he would enjoy a monster truck rally and purchased tickets, imagining father and son duo making great memories together. If you have never been to a monster truck rally, I don’t think I can convey to you how loud the sporadically-revved monster truck engine can truly be. The sound feels like a physical force hitting squarely in the chest, sending waves of vibrations outward. Despite purchasing sound suppression “monster truck tire” ear muffs for my son, he was not a happy camper and refused to enter the stadium. Instead he repeatedly asked to go home. I circled the outer ring of the stadium, where convenience stands sell hot dogs, turkey drumsticks, and monster truck paraphernalia. I naïvely hoped he would relax and decide to go inside to watch the show. I even resorted to bribery — “whatever monster truck you want I’ll buy if you just go inside the stadium with me.” But within 20 minutes of the rally starting and relentless loop of “I want to go home, Daddy,” the mighty father and son duo passed perplexed ticket-taking staff on our retreat to the parking lot in search of our humble but reliable 2010 Toyota Corolla.

My biggest fear was that my son’s deep love and fascination with monster trucks had been destroyed. Fortunately, he continued watching Hard Hat Harry monster truck episodes incessantly with his current favorite monster truck snuggled safe beside him. So I know more fun facts about monster trucks than I care to admit. For example, monster trucks can actually drive on water, have front and back wheel steering, windows at the driver’s feet for wheelie control, engines that shut off remotely, are capable of consecutive back-flips, can jump over 230 feet without injury, and put away seven gallons of gas traveling less than a mile. When not on exhibitions, monster trucks require constant tuning and tweaking, such as shaving rubber from their gigantic tires to reduce weight and permit them to fly as high as possible on jumps. Monster trucks are their owners' passion, and they don’t mind spending 24/7 maintaining these (I now realize) technological marvels created by human ingenuity and perhaps too much spare time.
Despite how much my son loves them, I have zero desire to own a monster truck. I am a busy dad and value time even more than money (to my wife’s lament). Though my son would be overjoyed if I brought home a truck with tires that towered over him, I personally prioritize factors of safety, fuel efficiency, reliability, and simplicity.
There are reliable and powerful motor vehicles that we use to make our lives easier, and then there are even more powerful ones that astound and enlighten us at competitions. We similarly have superstar algorithms that do optimization for machine learning that can be used to train rich and expressive deep learning models to perform amazing feats of learning, such as the recent showdown between Atari Games and a deep learning tool. One of the stars of today's machine learning show is stochastic gradient methods and the dual coordinate descent variants. These methods:
- are surprisingly simple to describe in serial, while requiring eloquent mathematics to explain convergence and in practice
- can train a model remarkably fast (with careful initialization)
- are currently producing world record results.
This trifecta makes stochastic gradient descent (SGD) the ideal material for journal articles. Prototype approaches can be created relatively quickly, requiring publishable mathematics to prove convergence, pounded home with surprisingly good results. Like a pendulum swinging, my personal opinion is that the stochastic gradient algorithms are (1) awesome, (2) incredibly useful, practical, and relevant, and (3) may be eclipsing classes of algorithms that for many end users could actually be more practical and relevant when applicable.
As my career has progressed and I have been immersed in diverse optimization groups, this experience has impressed upon me the philosophy that for every class of algorithms there exists a class of problems where the given algorithm appears superior. This is sometimes referred to as the no free lunch theorem of optimization. For end users, this simply means that true robustness cannot come from any single best class of algorithms, no matter how loud its monster engine may roar. Robustness must start with diversity.

An example of someone thinking outside the current mainstream is the relatively recent work on Hessian-free optimization by James Martens. Deep learning models are notoriously hard to solve. Martens’ shows that adapting the second-order methodology of Newton’s method in the Hessian-free context creates an approach that can be used almost out-of-the box. This realization is in stark contrast to many existing approaches, which work only after careful option tuning and initializations. Note that a veteran data miner may spend weeks repeatedly training the same model with the same data in search of the needle in the haystack golden — a set of solver options that result in the best solve time and solution. For example, Figure 1 shows how the choice of the so-called “learning rate” can decide whether an algorithm converges to a meaningful solution or goes nowhere.
This is why I am excited about this Hessian-free approach, because although it is currently not mainstream, and it lacks the rock star status of stochastic gradient descent (SGD) approaches, it has the potential to save the user significant user processing time. I am certainly also excited about SGD, which is a surprisingly effective rock star algorithm being rapidly developed and expanded as part of the SAS software portfolio. Ultimately, our focus is to provide users an arsenal of options to approach any future problem and ideally, like a monster truck, readily roll over any challenge undaunted. We are also working to provide an auto-tune feature that permits the efficient use of the cloud to find the best tool in for any given problem.
Stochastic gradient descent (SGD) approaches dominate the arena these days, with their power proving itself in the frequency with which they are used in competitions. However, not typically reported or advertised is the amount of time the data miner(s) spent tuning both the model and solver options, often called hyper-parameters. Typically the time reported for resulting models only measures the training time using these best parameter, and left unsaid are the long hours of concerted effort hunting, accumulated over weeks, for these hyper-parameters. This consuming tuning process is a well-known property of stochastic gradient methods, because the solvers surface a set of user options that typically need to be tuned for each new problem.
But on a day-to-day basis data miners seek to solve real data problems for their respective companies and organizations and not ascend the leaderboard in a competition. Not all problems are big data problems, and not all problems require the full power and flexibility of SGD. Two questions that all data miners must ask are:
- What model configuration to use?
- What solver should train the model?
The user searches for the unquantifiable best model, best model options, best solver, and best solver options. Combinatorically speaking there are billions of potential combinations one might try, and at times one needs a human expert to narrow down the choices based on as-yet-undefinable and inexplicable human intuition (another artificial intelligence opportunity!). A primary concern when picking a model and a corresponding training algorithm is solve time. How long must the user wait to obtain a working model? And what is the corresponding solution quality? In general users want the best model in the least time.
Personally when I consider solver time I think of two separate quantities:
- User processing time. How much time does the user need to babysit the procedure sitting in front of a computer?
- Computer processing time. How much time does the user need to wait for a given procedure to finish?
Often times we only can quantify (2) and end up leaving (1) unreported. However, a SAS customer’s satisfaction likely hinges on (1) being relatively small, unless this is their day job. I personally love algorithm development and enjoy spending my waking hours seeking to make algorithms faster and more robust. Because of this I jealously guard my time when it comes to other things in my life, such as the car I drive. I don’t own a monster truck and would never be interested in the required a team of mechanics and constant maintenance to achieve world record results. I just want a vehicle that is stable, reliable, and gets me to work, so I can focus entirely on what interests me most.
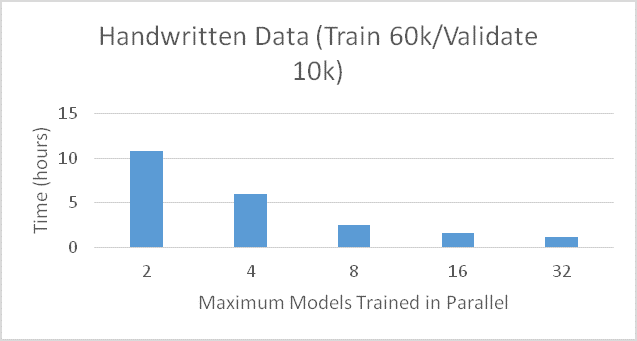
At SAS we want to support all types of customers. We work with experts who prefer total control and are happy to spend significant time manually searching for the best hyper-parameters. But we also work with other practitioners who may be new to data mining or have time constraints and prefer a set-it-and-forget scenario, where SAS searches for options for them. Now, in a cloud environment, we can train many models in parallel for you in the time it takes to build a single model. Figure 2 shows an example where we train up to 32 models concurrently, using four workers for each training session (resulting in a total of 128 workers used) to create 1800 different candidate models. Imagine attempting to run all 1800 models sequentially, manually deciding which options to try next based on the previous solve performance. I have done this for weeks at a time and found it cumbersome, circular (I would try the same options multiple times), and exhausting. Once presented this parallel capability I obtained new records in hours (instead of weeks) in exchange of me making a single click. Further, I am free to take care of other things while the auto-tune procedure works constantly in the background for me.

Another way to cut down on user processing time is using alternative algorithms that require less tuning but perhaps longer run times. Basically, shifting time from (1) to (2), such as with auto-tuning in parallel. This approach may mean substituting rock-star algorithms like SGD for algorithms that are slower and less exciting, such as James Martens’ Hessian-free work mentioned earlier. His may never be a popular approach in competitions, where data mining experts prefer the numerous controls offered by alternative first-order algorithms, because ultimately they need only report computer processing time for the final solve. However, the greatest strength of Martens’ work is the potential gain in reducing the amount of user processing time. In a cloud computing environment we can always conduct multiple training sessions at the same time. So, we don’t necessarily have to choose a favorite when we can run everything at the same time. A good tool box is not one that offers a single tool used to achieve record results but a quality and diverse ensemble of tools that cover all possible use cases. For that reason I think it best to offer both SGD and Hessian-Free, as well as other standard solvers. By having a diverse portfolio, you increase the chance that you have a warm start on the next great idea/algorithm. For example, my son, now five and half, spends more time at the toy store looking at power rangers than monster trucks.
My sturdy and reliable Toyota Corolla, like second-order algorithms, may not ever be as carefully and lovingly tuned to win competitions, but practitioners may be far more satisfied with the results and lesser maintenance time. After all, judging by the vehicles we see on the road, most of us, most of the time, will prefer a practical choice for our transportation rather than a race car or monster truck.
I’ll be expanding on optimization for machine learning later this week at the International Conference on Machine Learning on Friday, June 24. My paper, “Unconventional iterative methods for nonconvex optimization in a matrix-free environment,” is part of a workshop on Optimization Methods for the Next Generation of Machine Learning, and I’m pleased to be joined by such rock stars as Yoshua Bengio of the University of Montreal and Leon Bottou of Facebook AI Research, who are just a few of the stellar people presenting on such topics during the event.






