Cultural heritage is defined as an expression of the ways of living developed by a community and passed on from generation to generation, including customs, practices, places, objects, artistic expressions, and values (ICOMOS, 2002). This far-reaching concept transcends through generations and is continuously evolving as time goes by. Conservation efforts of things, structures, traditions of the past – which involves activities such as restoration, reconstruction, retrofitting, among others – are therefore, involves interconnected and overlapping constructs that can be region-specific, ideology-centered, and cater to specific regulatory restrictions. On top of that, with many professionals delving into the world of cultural conservation from different backgrounds, expertise, and values results in nuances in cultural heritage management, conservation techniques and practices.
As a cultural heritage advocate, I have seen countless conservation efforts, both locally and overseas, where the interpretation of conservation activities varies, resulting to mismanaged cultural treasures; sadly, some are destroyed beyond repair. Questions such as: Are policies regarding visual integrity the same here and overseas? Does repainting activities form part of a retrofitting method? How similar are reconstruction activities to actual replacement? The idea to have a single source (a wordbook) of heritage terms, concepts, and practices that’s understandable, accessible, and usable to practitioners is the subject of my master’s research paper. In this article, I will share how SAS Visual Text Analytics (within the academia offering, SAS Viya for Learners 3.5) easily analyzes similar words and phrases coming from various cultural heritage-related documents to construct a heritage wordbook that cultural workers can use to identify what relevant conservation technique to use on a structure/artifact.
The qualitative research methods include archival research and analysis, data trimming, and software analysis. The data input for this study consists of 63 cultural heritage research projects, international guidelines, and legislations from local and international sources written/accessed from 1961-2023. The data is trimmed to acquire this cleaned data: the reference or source, and the source's "definition of terms/glossary" equivalent of each article:

The CSV file is then loaded into the SAS Studio function of SAS Viya for Learners. Within SAS Model Studio, the text analytics pipeline nodes used include:
The Concept Node which enables users to "work with semantic attributes, entity types, facts, or relationships, and extracts pieces of the text using rules written in the language interpretation for textual information (LITI) syntax." The concept rule used is:
CLASSIFIER:<text/phrase> CONCEPT_RULE:(AND, "_c{<text/phrase>}", "defines", "refers") Where, AND Takes one or more arguments. Matches if all arguments occur in the document, in any order. (Model Studio: SAS® Visual Text Analytics 8.5) |
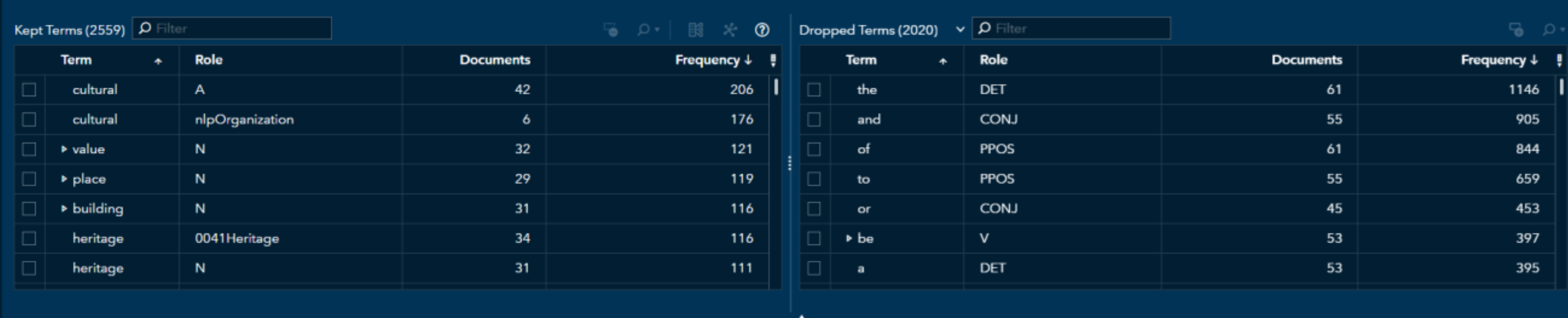
The Text Parsing Node enables you to view and explore the terms that are present in your document collection. During the parsing process, terms are either kept or dropped based on their importance. (Model Studio: SAS® Visual Text Analytics 8.5) During the data collection, this node allows me to remove parts of speech and see the number of documents that matched the "kept terms" and "frequency" it showed up:
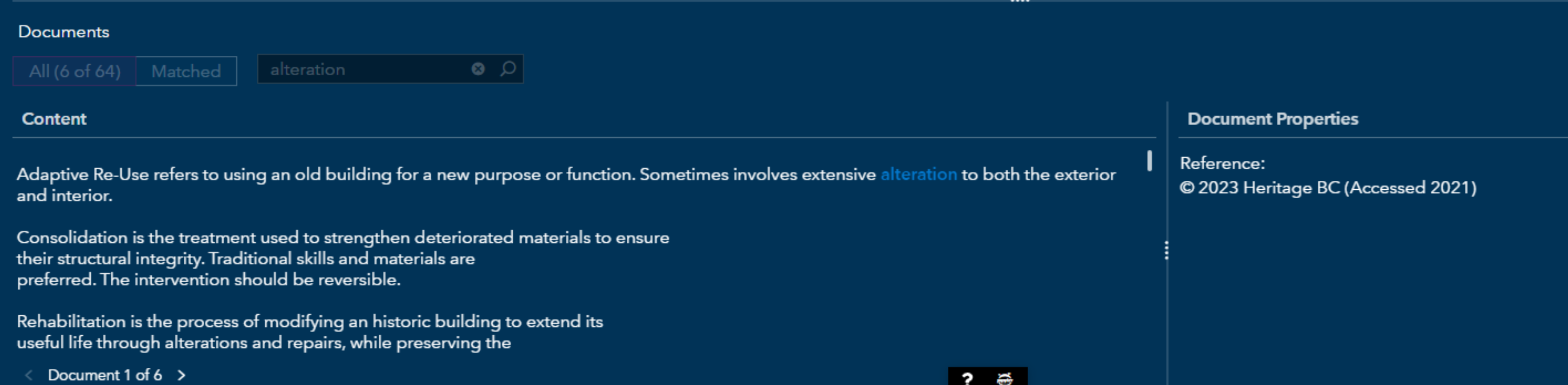
Document selection allows me to search for a term/concept and the reference it came from, which is especially useful since a wordbook cannot be built without a bibliography section.
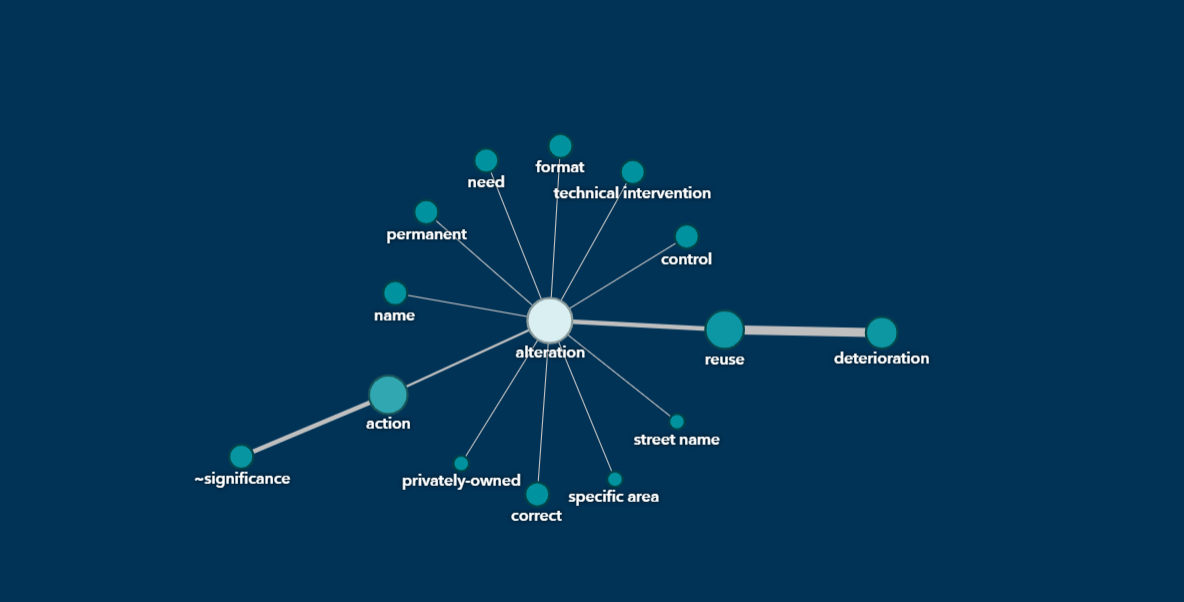
Finally, the term map lets me visualize the similar terms and concepts against each other:
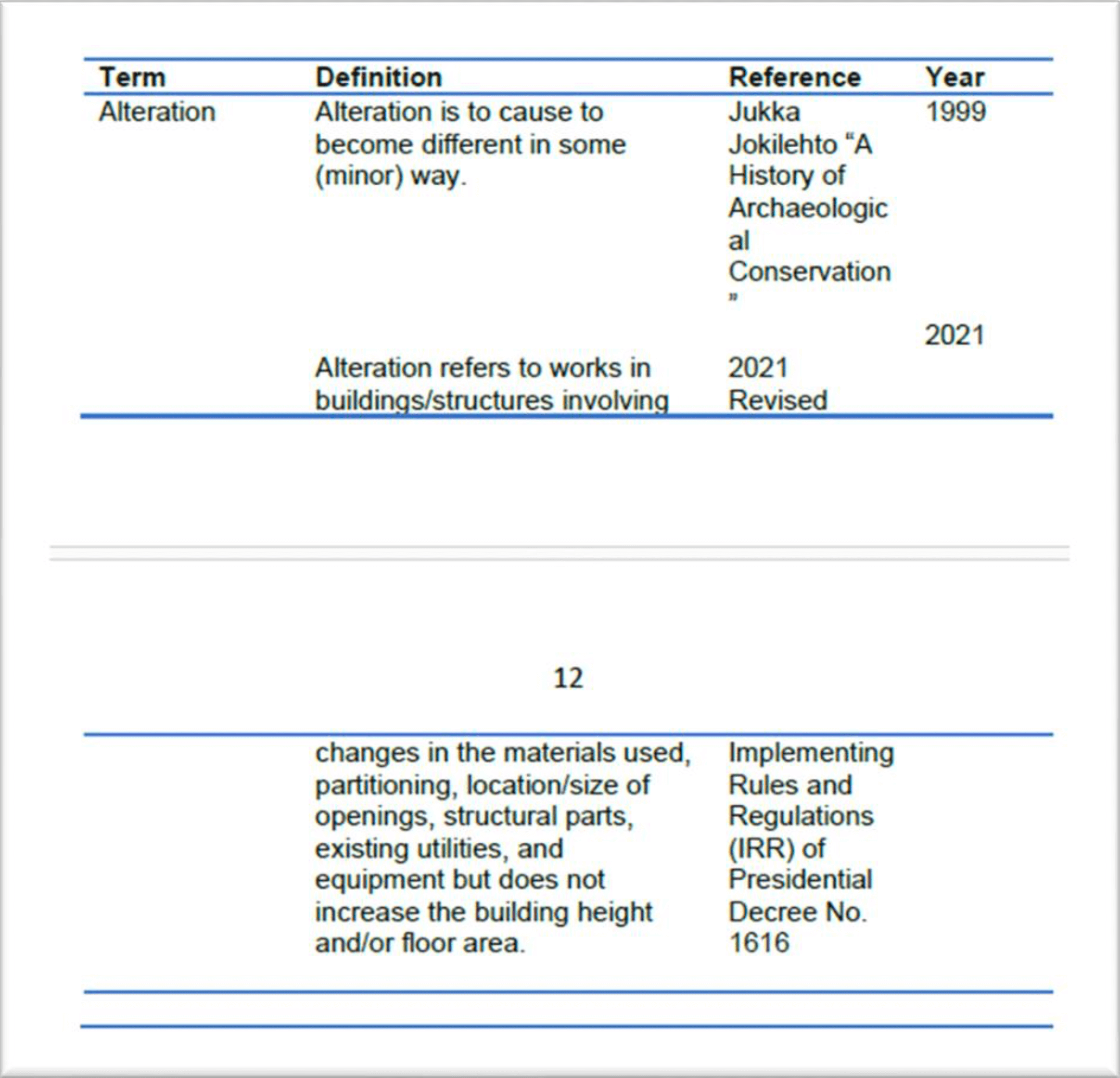
From the 63 references used, the results from these iterative steps include 308 unique terms and concepts classified and 441 definitions fetched.
Based on the steps done, the following stages contribute to the development of the wordbook with end users: Relevancy Scoring, Similarity Scoring and Term Mapping, and Text Classification. This all makes it possible to extract base terms and concepts, score definitions sources from the documents, and evaluate their levels of relativity between each term quantitatively.
In summary, as there is a continuous adoption of new terms and concepts, there should be measures in place to ensure that workflow processes utilized are abreast to word evolution as it happens. How we interpret words, integrate new ones, and tag concepts as obsolete constantly changes. Every word tells a story over time. That’s why the usage of a wordbook goes hand in hand with constant review of the data source where it was generated from. There is much to do and more to explore with the upcoming release of SAS Viya for Learners 4. It is interesting to note how the work above fares with other capabilities such as deriving terms in a local language, and its usability/accessibility to those who are SAS beginners/novice users. Through the appropriate usage of existing academic resources made available to students, I believe that more can be done to bring analytics to different disciplines including cultural heritage.

1 Comment
This is a very interesting blogpost. Thank you very much for sharing your research and your perspective.