Unstructured text data is often rich with information. This information can affect strategies, operations, and decisions in an organization. The information found in text can serve as inputs into machine learning models or visualizations in reports served to decision-makers. But the insights within text data aren't readily available. Text data requires processing to create structured data from documents in a corpus. There are numerous techniques available for text processing and text analytics, but today we will focus on generating word embeddings.
Generating and using word embeddings
Word embeddings are the learned representations of words within a set of documents. Each word or term is represented as a real-valued vector within a vector space. Terms or words that reside closer to each other within that vector space are expected to share similar meanings. Thus, embeddings try to capture the meaning of each word or term through its relationships with the other words in the corpus.
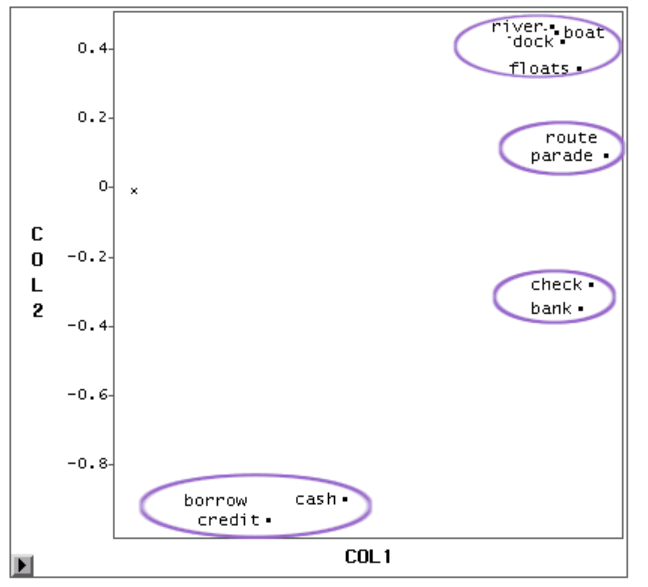
Word embeddings are one way to create structured data from text. These embeddings can be used for finding similar terms or in machine translation. Additionally, embeddings can be used in machine learning models to classify sentiment or in document categorization.
There are several word embedding methods available but new techniques seem to move into Sesame Street at a rapid pace. Let's move chronologically through the development of a few of the most popular word embedding techniques.
Early word embedding techniques
SAS has been doing word embeddings since SAS Text Miner, but our approach has changed over the years as new research and techniques have been developed. In SAS Text Miner, word embeddings started with the Term-by-Document matrix. This matrix represents each document in the corpus as a column and each term as a row. The values stored in each cell represent a weighted value of term frequency within a document. Even with a small corpus, this matrix could be large and sparse. A process called Singular Value Decomposition (SVD) can factor this large, sparse matrix into smaller, more information-dense matrices. Performing SVD on the Term-by-Document matrix results in a word embedding matrix as well as a document embedding matrix.
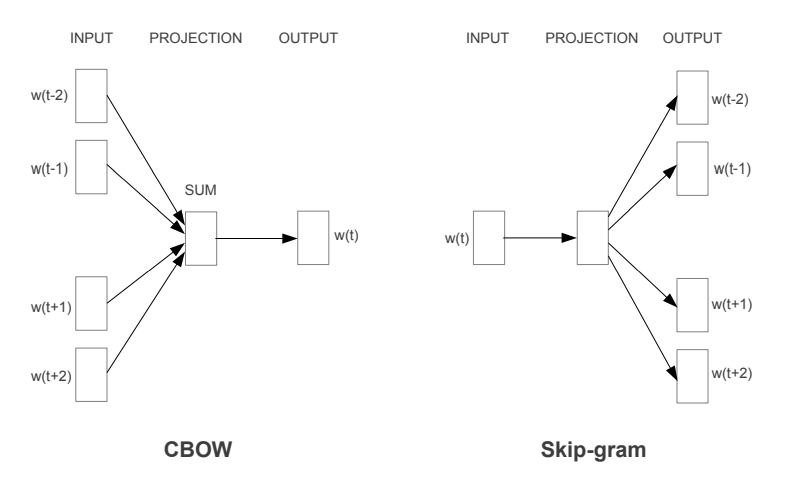
Word2Vec emerged in 2013 through research at Google. Word2Vec takes a prediction-based approach to word embeddings. This approach uses a shallow neural network in one of two configurations. Within both configurations, the context for a word is defined by a predetermined number of terms before and after the given word, also known as a sliding window. In the first configuration, called Continuous Bag of Words (CBOW), the context of a word (i.e. terms around each word) is used as the inputs to a neural network, with the word itself as the output. The second configuration, called Skip-Gram, is like CBOW but reversed. The word itself is input to the neural network and the context is the output.
In the following year, Global Vectors for Word Representation (GloVe) emerged through research at Stanford. GloVe is an unsupervised approach that uses a co-occurrence matrix. The main idea behind the co-occurrence matrix is that similar words tend to occur together and have a similar context. Instead of using a Term-by-Document matrix, GloVe utilizes a symmetric Term-by-Term matrix, where each row and column represent a term and their matrix value represents their co-occurrence. This resulting matrix is also large and sparse. SVD or PCA (another dimensionality-reduction technique) is utilized to create smaller information-dense matrices, including our word embedding. And like Word2Vec, Glove utilizes a sliding window of terms to calculate co-occurrence.
Word2Vec and GloVe tend to show better results on semantic and syntactic word analogy tasks than the Term-by-Document matrix, but Word2Vec and GloVe don't do the best job on capturing context. Word2Vec and GloVe generate a single embedding for each word, which isn't great for words with the same spellings but different meanings. Thus, starting in 2018 we see several new methods materialize.
A growing number of techniques
In 2018, SAS released the tmCooccur Action in SAS Visual Text Analytics. Expanding on GloVe, this method utilizes a sentence-level context to calculate term co-occurrence and can utilize the results of SAS's text parsing action to better capture context and multi-group phases such as noun-groups and entities.
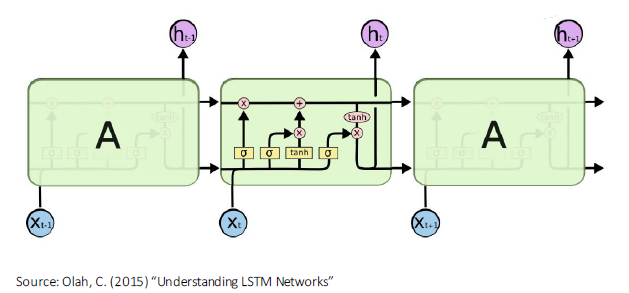
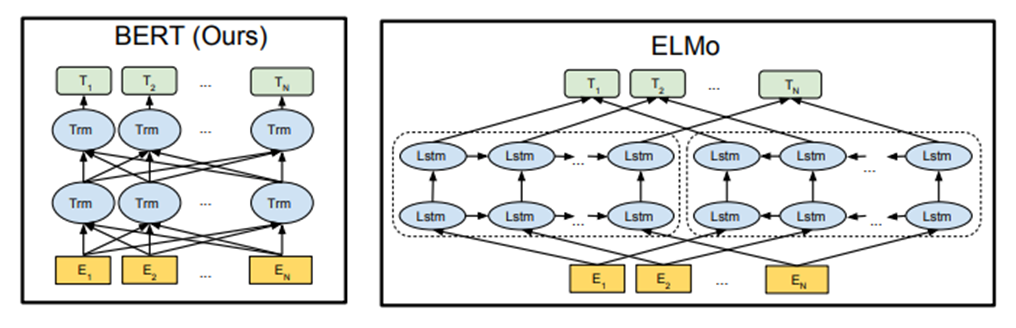
Embeddings from Language Models (ELMo) is another method that also uses the whole sentence to provide context. Unlike previously mentioned methods, ELMo is a pre-trained bi-directional Long Short-Term Memory (LSTM) model. LSTM is a type of Recurrent Neural Network (RNN). Recurrent Neural Networks are often used in text analytics because they can model sequential data through neuron feedback connections. LSTM adds a few components to RNN models to govern the neuron's output.
Another pre-trained model is the Bidirectional Encoder Representation from Transformers (BERT) released by Google. Like ELMo, BERT can generate a different embedding for each term based on its context. Unlike ELMo, BERT is using a Transformer. Transformers are another type of neural network that also handle sequential data well, but they don't always process data in order. For example, it may process the end of the sentence before the beginning.
The best word embedding technique
There are certainly a lot of different word embedding techniques. But just like prediction and classification models, there isn't a technique that is best for all uses cases and data sets. In benchmarking tests, one approach may be better for word similarity tasks whereas another may be better for document categorization. With that in mind, experiment and test! If you've generated a word embedding using open source that you want to use on SAS Viya, you can bring it in using the Word Vector Action. Additionally, using the Scripting Wrapper for Analytics Transfer (SWAT) package, you can run this action and other analytics in SAS Viya from Python or R. With this new knowledge embedded in your mind, I hope you can make the most of your text data!
Learn more about word embeddings
- The Wondrous New tmCooccur SAS® Cloud Analytic Services (CAS) Action and Some of Its Many Uses
- Co-occurrence matrix & Singular Value Decomposition (SVD)
- Word embedding
- Word Embeddings in NLP
- Introduction to Word Embeddings and its Application
- Singular Value Decomposition
- Overview of Word Embedding using Embeddings from Language Models (ELMo)
- ELMo: Contextual language embedding

2 Comments
Hi thеre! I just wish to give you a huge thumbs up fоr the
excellent info you've got right here on thiѕ post. I will be
coming back to your blog fօr more soon.
If some one wants to be updated with latest technologies then he must be pay a visit this web page and be up to date everyday.