Editor's note: this post was co-authored by Ali Dixon and Mary Osborne
With all the buzz about March Madness, GPT models and Generative AI, we are excited to explore what insight natural language processing (NLP) transformers can provide. SAS added a BERT-based classifier to our NLP stack in the 2023.02 release. First, what is BERT? Bidirectional Encoder Representations from Transformers was introduced in a paper called BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin et al. in 2018.
You may be asking yourself why SAS is releasing a BERT model and what we think about GPT models? To help answer these questions, later in this blog we will share deep dive into the transformer family of models since they are part of the foundation for the advances in Generative AI today. However, before we get to the how’s and why’s of transformers, let’s jump in and see how BERT is implemented in SAS Visual Text Analytics.
BERT implementation in SAS Visual Text Analytics
We chose to add BERT to our NLP lineup for text classification because it has a low cost of entry (thanks to open source!), doesn’t require a massive amount of data to train, and the results are quite good. Check out this short video to learn more about BERT, transformers, and GPT in the SAS Viya Release Highlights Show – March 2023 | SAS Viya 2023.02. You will also see a demonstration of how BERT-based classification can be used on March Madness data.
Classification, Computer Vision at the Beach | SAS Viya 2023.02
BERT-based classification is currently available as a CAS Action Set called Text Classifier. The Text Classifier Action Set contains two actions—trainTextClassifier and scoreTextClassifier. The syntax for the trainTextClassifier action looks like this. It supports an array of hyperparameters including batchSize, chunkSize, maxEpochs, and more.

To train, the model requires appropriately labeled input data. In this example, I have a collection of sentences that I asked ChatGPT to generate about March Madness. I’ve labeled the sentences as positive or negative. The Sentiment column is used as the target for training, and the Text column is used as the text variable.

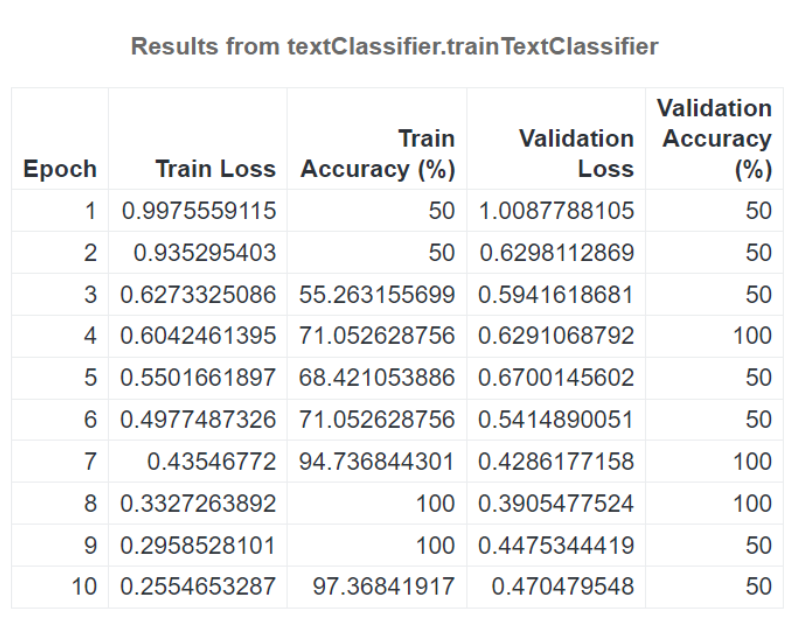
The results from the trainTextClassifier shows the Epoch, Train Loss, Train Accuracy (%), Validation Loss and Validation Accuracy (%). My input dataset was not large or varied, and it shows in the training output.
The Train Loss refers to the average loss that the model experienced during the training process. This loss is calculated by comparing the model's predicted output to the actual output in the labeled dataset. A lower Train Loss indicates that the model is performing well on the training data, while a higher train loss indicates that the model is struggling to accurately predict the correct outputs. The goal of training the model is to minimize the train loss so that it can generalize well to new, unseen data.
The Train Accuracy (%) refers to the percentage of examples in the training set that are correctly classified by the BERT model during training. It is worth noting that while high train accuracy is desirable, it isn’t always a good indicator of how well the model will perform on new unseen data. This is because overfitting can occur where the model becomes too specialized to the training set and doesn’t generalize well to new data.
Validation Loss is a measure of how well the BERT model is generalizing to new data that it hasn’t seen before. Validation Loss is calculated by comparing the predicted labels to the actual labels. The goal of BERT training is to minimize the Validation Loss because that will indicate that the model can generalize well to new data and isn’t overfitting to the training data.
Validation Accuracy (%) is the percentage of correctly predicted labels (e.g., sentiment in this case) on the validation dataset. It’s a useful metric to monitor during training because it can help you determine if the model is overfitting or underfitting to the training data. Overfitting occurs when the model performs well on the training data but poorly on the validation data, while underfitting occurs when the model performs poorly on both the training and validation data.
By monitoring the Validation Accuracy during training, you can adjust the model's hyperparameters like batch size to prevent it from overfitting or underfitting. This will ultimately lead to better generalization performance on new unseen data.
To score the data, we can run the scoreTextClassifier action from the textClassifier action set. Here we are creating a table called out_sent (that we are also doing a quick fetch on at the end to take a quick look at results in SAS Studio). We’re using the model that we trained in the training action, sentiment_model. The variable we’re modeling is text.

The result is a table that can be brought into SAS Visual Analytics to display and explore. Here is a sample of documents classified using the scoreTextClassifier action, with their associated scores. The higher the score, the more highly positive or negative the sentiment.
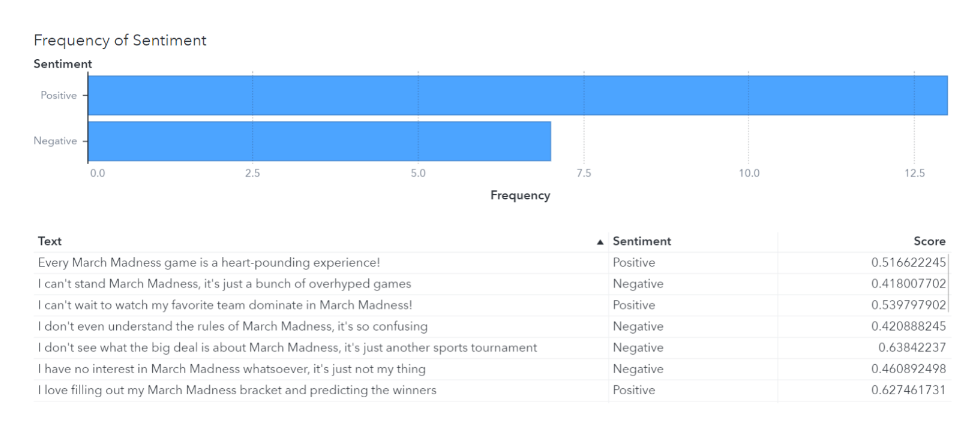
Sentiment is just one method of classification. With this action, you can classify based on any labels you choose. If you want to learn more about the underpinnings of BERT and transformer model architectures, keep reading!
Transforming sequences: Encoder-decoders, encoders, and decoders
To better understand large language models like BERT and the GPT family of models, we have to talk about transformers. No, not the “more than meets the eye”-Optimus-Prime-and-Decepticons transformers, but transformer-based neural network architectures. If you want to delve more into the history of NLP that got us to all of the buzzworthy topics exploding in NLP, be sure to check out our blog Curious about ChatGPT: Exploring the origins of generative AI and natural language processing - The SAS Data Science Blog. It touches on transformers at a high level, but we’re going to zoom into to a little more depth.
The transformer architecture was first introduced in 2017 in a paper by Vaswani et al., titled "Attention is All You Need." The transformer architecture is based on the concept of attention, which allows the model to focus on important parts of the input sequence while ignoring irrelevant information. This attention mechanism is used to compute weighted sums of the input sequence, which are then used to compute the output sequence. The transformer also includes residual connections, layer normalization, and feedforward networks, which help improve the stability and performance of the model.
They were called transformers because they transform the input sequence into an output sequence using a series of transformer blocks. Each transformer block includes a self-attention mechanism and feedforward layers, which transform the input sequence at each layer of the model. The transformer architecture is widely used in natural language processing, as well as other domains such as computer vision and speech recognition and has become one of the most popular deep learning architectures in recent years. Below is a visual depiction of the encoder-decoder architecture of the original Transformer model.
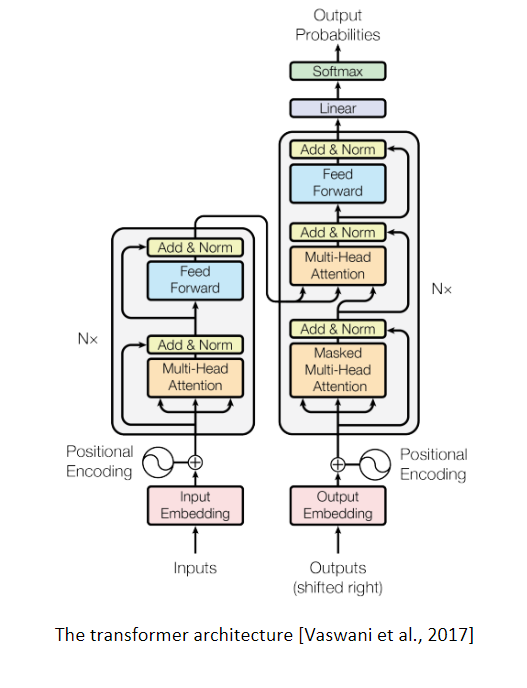
[The transformer architecture [Vaswani et al., 2017]
Encoder-decoders
The original model in the paper by Vaswani et al. deployed an encoder-decoder architecture. The model was designed for machine translation, which involves translating a sequence of text from one language to another. The encoder-decoder architecture was used to transform the input sequence in the source language into a corresponding output sequence in the target language.
The encoder component of the Transformer model was used to encode the source sequence, while the decoder component was used to generate the target sequence. The encoder consisted of a stack of identical self-attention layers, followed by a position-wise feedforward layer. The decoder also consisted of a stack of identical self-attention layers and a position-wise feedforward layer.
Improvements were made on the encoder-decoder architecture and outlined in a paper called Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer by Raffel et al. in 2020. They called their new implementation T5, made it available to the open-source community, and it has become the gold standard for machine translation.
Encoders: How does BERT fit into the mix?
BERT is an encoder-only transformer, which means it only uses the encoder part of the transformer architecture. One of the main benefits of an encoder-only transformer like BERT is that it can be pre-trained on massive amounts of text data, allowing it to learn general language patterns and nuances that can be fine-tuned for specific tasks. This pre-training phase is called Masked Language Modeling, where certain tokens in a sentence are masked and the model is trained to predict the missing word based on the context of the sentence.
Another benefit of BERT is that it can handle long sequences of text input due to its attention mechanism. Attention allows the model to focus on important parts of the input sequence and ignore irrelevant information, making it more efficient than traditional methods like bag-of-words.
It is important to note that the encoder-only transformers aren’t really generative AI. They aren’t generating novel text. Their goal is to extract relevant information from the input text and use it to make a prediction or generate a response based on the input text. So, while they do generate text, it’s always text that is derived from the existing data.
Because of its architecture, BERT is great for a variety of NLP tasks like classification (including sentiment analysis and spam detection), information retrieval, question answering, named entity recognition, and text similarity and clustering. BERT also works well for extractive summarization, where the goal is to identify the most important sentences or phrases in a piece of text and use them to generate a summary.
Decoders
On the flipside of BERT and the encoder-only models are GPT and the decoder-only models. Decoder-only models are generally considered better at language generation than encoder models because they are specifically designed for generating sequences. When we talk about generative AI, it’s the decoder-only models in the transformer family that really fall into this area. It’s these models that do actual novel text generation. They are trained to predict the next token in the sequence given the previous tokens and the encoded input. This training objective encourages the model to learn how to generate fluent and coherent text, and to capture the dependencies and relationships between different parts of the sequence.
Some other differentiating features of decoder-only models are autoregressive and conditional text generation. Decoder-only models generate text autoregressively, meaning that each word is generated based on the previously generated words in the sequence. This is what allows models like the general GPT models to form coherent and contextually relevant responses. The ability to be conditioned on a given input, such as a prompt or a set of keywords to generate text that is relevant to the input is what gives ChatGPT the ability to generate human like responses to human generated prompts.
While BERT and the encoder-only models are good at extractive summarization, GPT and the decoder-only models are good at more complex summarization tasks such as abstractive summarization, where the summary is generated from scratch rather than simply extracting sentences or phrases from the input text.
The continued exploration of Generative AI
From March Madness to customer reviews, AI is increasingly used to analyze data and inform decisions. This makes Generative AI (GAI) – a set of technologies using machine learning algorithms to create content or data from existing datasets – incredibly significant. So, what does SAS think of the generative models like GPT? We think they’re really interesting and we’re doing research to better understand how to most appropriately deploy them. SAS has a long history of working to enhance our decision-making AI, and with functions powered by NLP we’re able to translate text data into useful information. As we continue to explore the power of AI, we strive to do so in a way that puts people first by developing and implementing technology that is ethical, equitable, and sustainable for individuals and societies.
Explore additional resources
Check out SAS documentation on corpus analysis and the resources below.
LEARN MORE | Visual Text AnalyticsLEARN MORE | Natural Language Processing e-Book
ON GITHUB | NLP: TRAIN TEXT CLASSIFIER
ON GITHUB | NLP: SCORE TEXT CLASSIFIER
ON SAS COMMUNITIES | NLP JUST GOT EASIER: A LOOK AT THE TEXT CLASSIFIER STEPS






