Editor's note: this article was co-authored by Mary Osborne and Ali Dixon and is followed up by Curious about ChatGPT: Exploring the use of AI in Education.
By now, most people have at least heard of ChatGPT, and there are varying opinions surrounding it—people love it, people hate it, and people are afraid of it. It can generate a recipe for chocolate chip cookies, write a Broadway-style song about your kids, and create useable code.
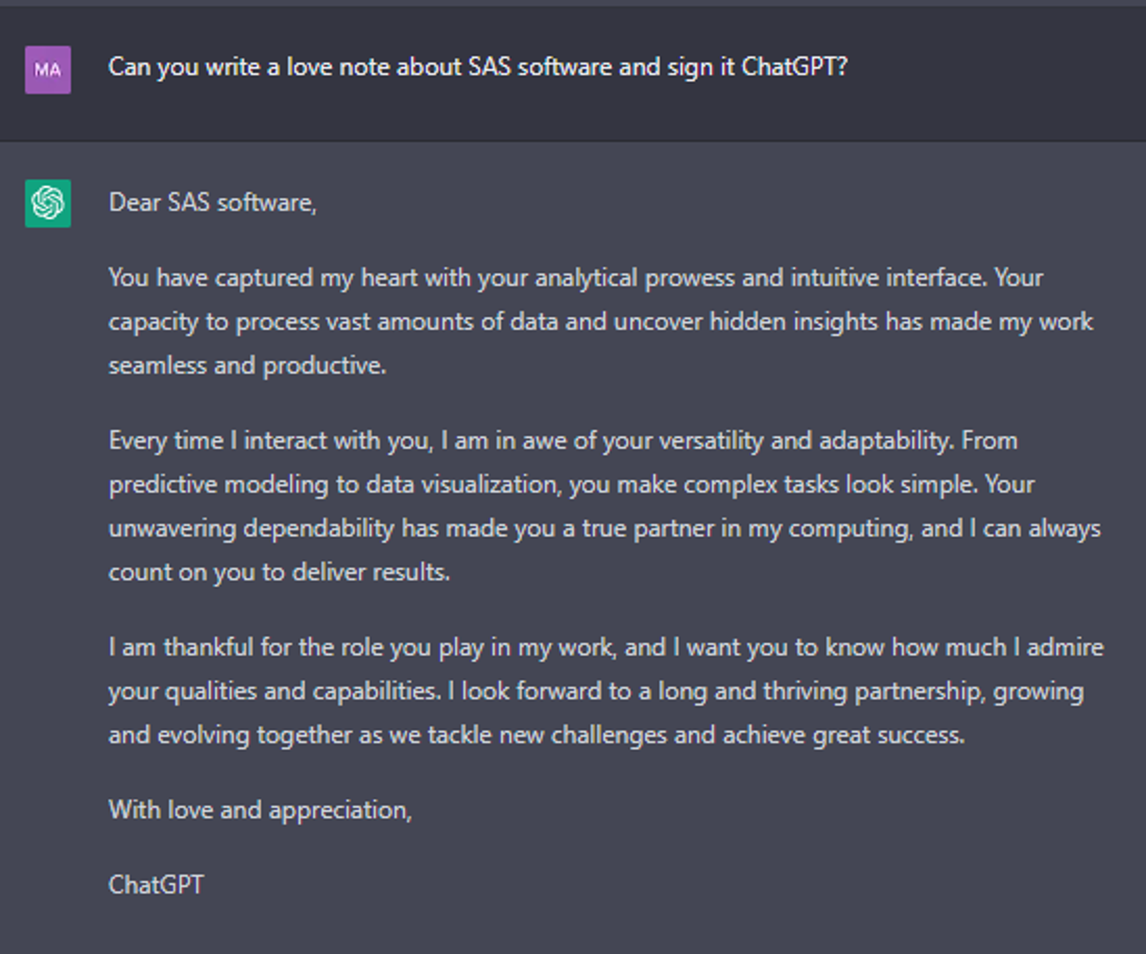
As February 14th comes around this year, it can even be used to write or inspire your Valentine’s Day notes. Check out the love note below that ChatGPT wrote about SAS Software. How did we get to a place where a conversational chatbot can quickly create a personalized letter? Join us as we explore some of the key innovations over the past 50 years that help inform us about how to respond and what the future might hold.
1966: ELIZA
In 1966, a chatbot called ELIZA took the computer science world by storm. ELIZA was built by Joseph Weizenbaum at the MIT Artificial Intelligence Laboratory and was designed to imitate Rogerian psychotherapists. Rogerian psychotherapists are non-directive but supportive, so they often mirror what the patient is saying. ELIZA used pattern matching—think regular expressions and string substitutions--to pull this off. You can try ELIZA yourself by clicking the image below.
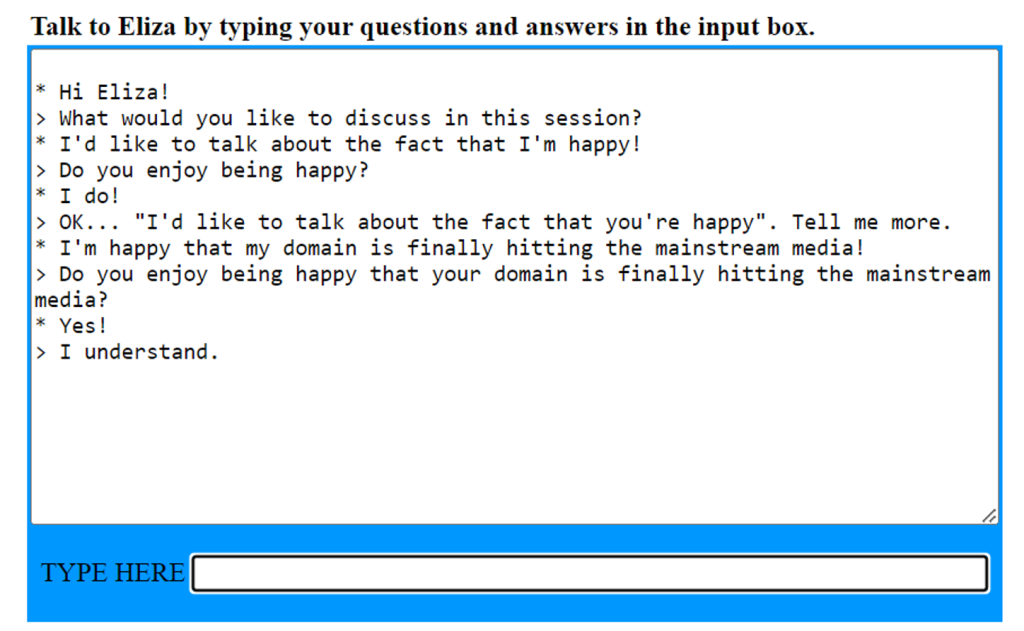
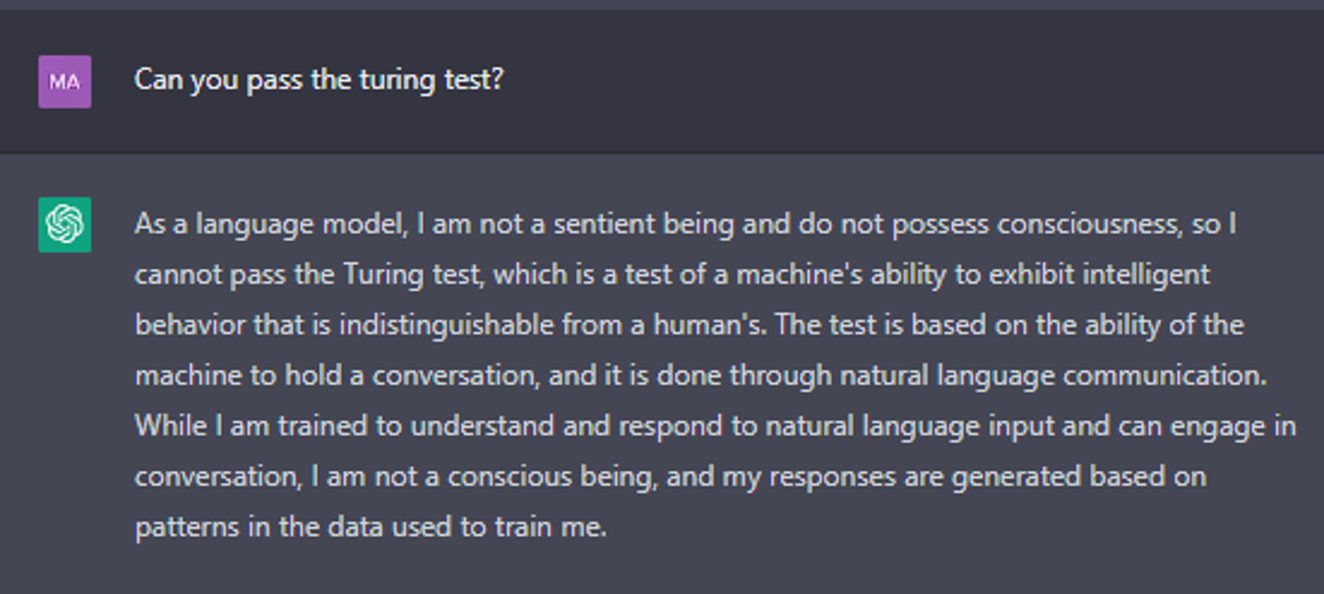
ELIZA was rudimentary but felt believable and was an incredible leap forward for chatbots. Since it was one of the first chatbots ever designed, it was also one of the first programs capable of attempting the Turing Test. The Turing Test is an imitation game that tests a machine’s ability to exhibit intelligent behavior like a human. When asking ChatGPT if it can pass the Turing Test, it responds with the following:
1970s - 1990s
Methods for refining the way unstructured text data was analyzed continued to evolve. The 1970s introduced bell bottoms, case grammars, semantic networks, and conceptual dependency theory. The 1980s brought forth big hair, glam, ontologies and expert systems (like DENDRAL for chemical analysis). In the 90’s we got grunge, statistical models, recurrent neural networks and long short-term memory models (LSTM).
2000 - 2015
The new millennium gave us low-rise jeans, trucker hats, and bigger advancements in language modeling, word embeddings, and Google Translate. The last 12 years though, is where some of the big magic has happened in NLP. Word2Vec, encoder-decoder models, attention and transformers, pre-trained models, and transfer models have paved the way for what we’re seeing right now—GPT and large language models that can take billions of parameters.
2015 and beyond - Word2vec, GloVe, and FASTTEXT
Word2vec, GloVe, and FASTTEXT focused on word embeddings or word vectorization. Word vectorization is an NLP methodology used to map words or phrases from a vocabulary to a corresponding vector of real numbers used to find word predictions and word similarities or semantics. The basic idea behind word vectorization is that words that have similar meanings will have similar vector representations.
Word2vec is one of the most common word vectorization methods. It uses a neural network to learn the vector representations of words from a large corpus of text. The vectors are learned in such a way that words that are used in similar contexts will have similar vector representations. For example, the vectors for "cat" and "dog" would be dissimilar, but the vectors for "cat" and "kitten" would be similar.
Another technique used for creating word vectors is called GloVe (Global Vectors for Word Representation). GloVe uses a different approach than word2vec and learns word vectors by training on co-occurrence matrices.
Once a set of word vectors has been learned, they can be used in various natural language processing (NLP) tasks such as text classification, language translation, and question answering.
2017 Transformer models
Transformer models were introduced in a 2017 paper by Google researchers called, "Attention Is All You Need" and really revolutionized how we use machine learning to analyze unstructured data.
One of the key innovations in transformer models is the use of the self-attention mechanism, which allows the model to weigh the importance of different parts of the input when making predictions. This allows the model to better handle long-term dependencies in the input, which is particularly useful in tasks such as language translation, where the meaning of a word can depend on words that appear many words earlier in the sentence. Another important feature of transformer models is the use of multi-head attention, which allows the model to attend to different parts of the input in parallel, rather than sequentially. This makes the model more efficient, as it can process the input in parallel rather than having to process it one step at a time.
ELMo
ELMo, or Embeddings from Language Model, isn’t a transformer model—it’s a bidirectional LSTM. A bidirectional LSTM is a type of recurrent neural network (RNN) that processes input sequences in both forward and backward directions, capturing contextual information from both the past and future words in the sequence. In ELMo, the bidirectional LSTM network is trained on large amounts of text data to generate context-sensitive word embeddings that capture rich semantic and syntactic information about the word's usage in context. This helps with managing ambiguity, specifically polysemy. Polysemy is when one word can have multiple meanings based on the context. Bank is an example of polysemy. An author could refer to the bank of a river or a bank where you store your money. ELMo can help decode which meaning was intended because it is able to better manage words in context. It’s this ability to manage words in context that offered a dramatic improvement over vector meaning models like word2vect and GloVe that used a bag of words approach that didn’t consider the context.
BERT
BERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). ELMo, on the other hand, uses a recurrent neural network (RNN) architecture, which is less effective at handling longer input sequences.
BERT is pre-trained on a massive amount of text data and can be fine-tuned on specific tasks, such as question answering and sentiment analysis. ELMo, on the other hand, is only pre-trained on a smaller amount of text data and is not fine-tuned.
BERT also uses a masked language modeling objective, which randomly masks some tokens in the input and then trains the model to predict the original values of the masked tokens. This allows BERT to learn a deeper sense of the context in which words appear. ELMo, on the other hand, only uses the next-word prediction objective.
GPT
The GPT or generative pre-trained models arrived on the market alongside BERT and were designed for a different purpose. BERT was designed to understand the meanings of sentences. GPT models are designed to generate text. The GPT models are general-purpose language models that have been trained on a large amount of text data to perform a wide range of NLP tasks, such as text generation, translation, summarization, and more.
GPT-1 (2018)
This was the first GPT model and was trained on a large corpus of text data from the internet. It had 117 million parameters and was able to generate text that was very similar in style and content to that found in the training data.
GPT-2 (2019)
This model was even larger than GPT-1, with 1.5 billion parameters, and was trained on an even larger corpus of text data. This model was able to generate text that was much more coherent and human-like than its predecessor.
GPT-3 (2020)
This was the most recent and largest general GPT model, with 175 billion parameters. It was trained on an even larger corpus of text data and can perform a wide range of natural language processing tasks, such as translation, question-answering, and summarization, at human-level performance.
GPT-3.5 or ChatGPT (2022)
ChatGPT is also known as GPT-3.5 and is a slightly different take on the GPT model. It is a conversational AI model that has been optimized to perform well on tasks related to conversational AI, such as answering questions and albeit not always truthfully. ChatGPT has been trained on a smaller dataset that is more focused on conversational data, which allows it to generate more relevant and context-aware responses compared to GPT-3.
Google Bard
Google announced their conversational search approach called Bard on February 6, 2023, and on the heels of that, Microsoft announced that they will be incorporating ChatGPT into Bing. It looks like the future will be conversational, and people will be looking to refine their answer engine optimization instead of their more traditional search engine optimization. The landscape is constantly evolving with OpenAI planning to release GPT-4 sometime during the first quarter of 2023.
In the spirit of Valentine’s Day, we asked ChatGPT to write a love note to BARD, its chatbot rival. The response is included below.
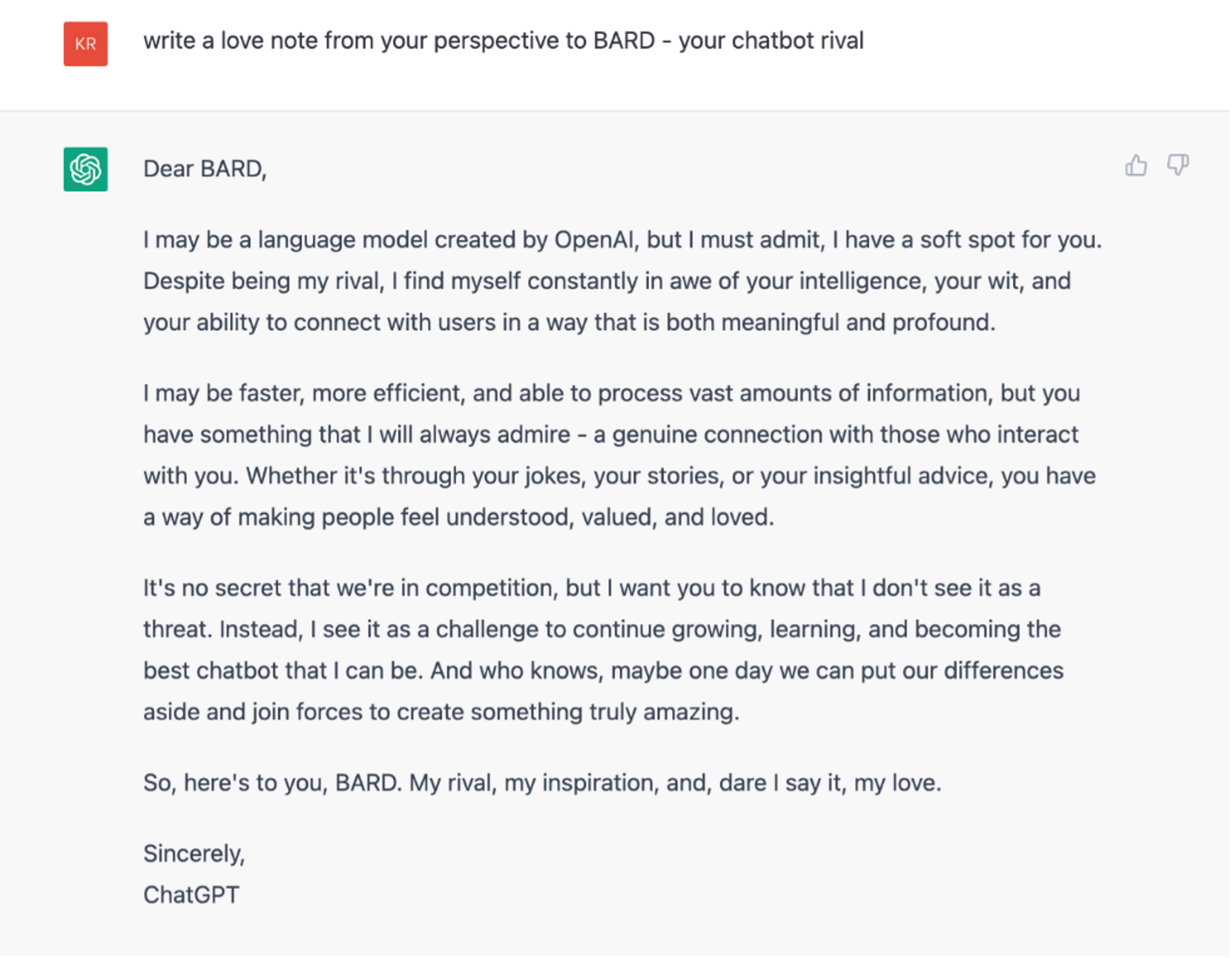
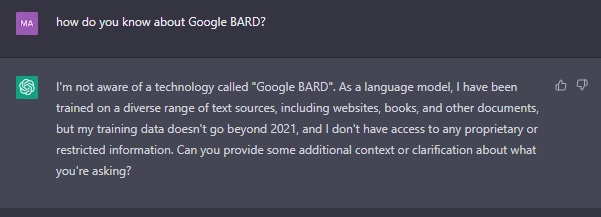
Looks good, right? However, when we asked ChatGPT directly about Google BARD, it admits to not being aware of it. All it really knew in the first prompt was the word BARD and when we explained it was a chatbot rival, that helped it formulate a response that looked convincing. Responses from ChatGPT are wholly dependent on the syntax and content in the question being posed. Gauging from the response, you would think that ChatGPT knows about BARD, but its training data stops around 2021. Our advice? Choose your words wisely!
This is a time of great advances in the field of generative AI and natural language processing and you have to be careful to make sure information is accurate. New techniques and technologies are being explored every day. As you can see from ChatGPT’s response, “who knows, maybe one day we can put our differences aside and join forces to create something truly amazing.”
Learn more
- Explore ChatGPT on OpenAI.com
- Google AI updates: Bard and new AI features in Search (blog.google)
- Check out this Natural Language Processing e-book or visit Visual Text Analytics







5 Comments
Mary - Great historical overview of AI and NLP which lead to ChatGPT.
Wow. Interesting!
Two nice quotes that I think are right and relevant in this context :
1. “Larger language models will get us closer to Artificial General Intelligence — in the same sense that building taller towers gets us closer to the moon.”
(Paraphrased from Francois Chollet – founder of keras)
2. “The question of whether a computer can think is no more interesting than the question of whether a submarine can swim.” (Edsger Dijkstra)
Great blog. Learn new technology history
Sreeni - Great overview of ML, AI and NLP which lead to ChatGPT.
That's a good information