
Luego de otro largo lapso, termino publicando el siguiente artículo de la serie ¡Explícate!. En este veremos cómo la teoría de juegos nos da una mano para interpretar mejor nuestros modelos de machine learning, utilizando las ideas del premio nobel de economía Lloyd Shapley.
Entenderemos los conceptos detrás de la teoría que da respaldo, el funcionamiento del algoritmo, como interpretar los resultados y algunos cuidados que hay que tener a la hora de usarlo, que como todas las cosas, tiene sus peros.
Este artículo incluye los siguientes tópicos:
- Un juego cooperativo
- Shapley value
- SHAP
- Un ejemplo
- ¿Cómo funciona Kernel SHAP?
- Consideraciones de uso
1. Un juego cooperativo
Para darnos una idea de cómo funciona este algoritmo busquemos entender un poco la teoría detrás del mismo, imaginándonos la siguiente situación: Se realiza un torneo del fabuloso juego X, el juego de moda. Para ganar el torneo los equipos deben sumar la mayor cantidad de puntos posibles. Los equipos que participen pueden estar conformados de 1 a 3 personas, y el equipo que gane recibirá un fabuloso premio económico.
Tres amigos: A, B y C (si lo sé, no soy bueno poniendo nombres) les encanta jugar a X y se anotan muy contentos en el torneo. Cuentan con habilidades diferentes y complementarias entre sí, juegan muy bien en equipo y saben que más allá de los resultados la van a pasar muy bien participando.
El torneo termina y pasa algo inesperado, consiguen 3500 y ¡ganan el torneo! Y con él, su fabuloso premio. Luego de los (largos) festejos, toca el turno de hacer algo que ni siquiera se lo habían planteado: Distribuir el premio.
Ellos, antes de ser jugadores del fabuloso X, son amigos. Saben que no todos contribuyeron de la misma forma y piensan como buscar una forma justa de repartir. A A se le ocurre usar su máquina del tiempo (les dije que tenían que usar la imaginación, ¿no?) y propone que cada uno compita el torneo de forma individual para ver cuántos puntos lograba cada uno por sí solo, el entendía que, a mejor desempeño individual, más premio le correspondía. Todos están de acuerdo, realizan los viajes temporales y repiten el torneo consiguiendo los siguientes puntajes individuales:
A = 1000 B = 1200 C = 1800
A se lamentó tener la máquina del tiempo. B se alegró de no ser A. Pero C, quizás el mejor jugador del mundo de X, reflexionó y se dio cuenta el desempeño individual no era una buena forma de valorar la importancia de los jugadores de un equipo. Pensó que quizás un jugador no sea muy bueno individualmente, pero puede potenciar al resto del equipo y eso brinda el mismo valor, o más, que un excelente jugador individual. Hacen falta más C en el mundo sin lugar a duda.
Con la sabiduría de C, decidieron volver a competir el torneo, esta vez jugando en coaliciones (sub-equipos) de 2: AB, AC y BC. Buscaban tratar de entender cuanto aporta cada uno al juego de equipo. Las coaliciones consiguieron los siguientes puntajes:
AB = 2500 AC = 2100 BC=2000
Ya habían competido de todas las formas posibles, sólo restaba ver como con esa información podían conseguir cuanto contribuyo cada uno en el puntaje total.
B que se había especializado en economía matemática se propuso calcular las contribuciones de cada uno razonando de la siguiente manera:
- A hizo 1000 puntos. Por lo tanto, aportó 1000 puntos.
- Cuando participo con B, juntos hicieron 2500. Como A hizo 1000, los 1500 excedentes son los que aportó de B
- Con la participación de los 3 llegaron a 3500. Como A y B hicieron 2500, los 1000 excedentes son los puntos que aporta de C.
Como se habrán dado cuenta esa forma de ver los aportes dependen del orden de los participantes que uno considera. Si en vez de empezar por A, continuar por B y finalmente analizar C, hacemos C A B, tendremos que los aportes de A, B y C serían 300, 1400 y 1800 respectivamente.
Como el orden de cómo se evalúa depende el valor, llamamos a estos valores contribuciones marginales. Y podemos armar una tabla con todas las posibles formas de ordenar los participantes (permutaciones) y calcular sus contribuciones marginales:
 Finalmente, para calcular la contribución de cada participante, tomamos los promedios de todas sus contribuciones marginales. De esta forma quedo que de los 3500 que consiguieron en total, 1100 son mérito de A, 1150 son mérito de B y 1250 lo son de C.
Finalmente, para calcular la contribución de cada participante, tomamos los promedios de todas sus contribuciones marginales. De esta forma quedo que de los 3500 que consiguieron en total, 1100 son mérito de A, 1150 son mérito de B y 1250 lo son de C.
O lo que es lo mismo, a A le correspondía el 31,4% del premio, a B el 32,8% y a C el 35,8%.
Todos quedaron muy contentos con el resultado, porque lo consideraron muy justo, y empezaron a prepararse para el torneo de X del año siguiente.
2. Shapley value
Lo que aplicó B, no es más que la contribución que le dio el premio Nobel de economía al matemático Lloyd Shapley (nostalgic paper). Entra en el marco de la teoría de juegos cooperativos, que estudia la interacción de los jugadores cuando colaboran para un mismo objetivo.
Shapley estudió como tratar de distribuir la ganancia obtenida por un equipo de una forma justa, entendiendo por justa, cualquier forma de distribución que tenga las siguientes propiedades (en lenguaje coloquial)
- Si un jugador no aporta ninguna ganancia, su contribución debe ser 0
- La suma de las contribuciones individuales tiene que ser igual a la ganancia total.
- Equal treatment of equals: Si dos jugadores que no pertenecen a una coalición, si cuando se unen individualmente a esta generan la misma ganancia, entonces, deben tener las mismas contribuciones.
- Y debe ser lineal sobre la función de ganancia… because maths. Hablando en serio, si un juego tiene más de una ganancia, la contribución de un jugador en la ganancia total debe ser igual a la suma de las contribuciones de cada una de las ganancias del juego.
Con el fin de lograr una distribución de la ganancia que cumpla con las propiedades anteriores, Lloyd propone la fórmula
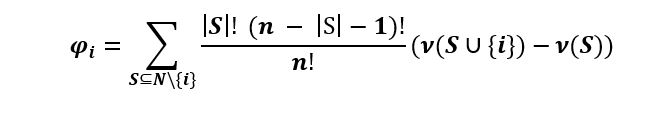
La fórmula calcula para un jugador i su contribución φi, donde n es la cantidad total de jugadores, S son las coaliciones que no incluyen a i y v la función que devuelve la ganancia de cada coalición.
Lloyd demuestra que cumple con las propiedades deseadas, y además demuestra que es la única que puede cumplirlas. En su honor, a esta distribución se llaman el valor de Shapley.
Esta fórmula no es más que una forma de escribir lo que hicimos con la tabla del ejemplo anterior, algo que se puede ejemplificar fácilmente usando el caso de A, donde S ϵ { ∅, B, BC }.
El valor de Shapley se usa ampliamente, ya que no siempre es necesario una máquina del tiempo para formar una función de ganancia.
3. SHAP
¿Y esto que tiene que ver con modelos y su explicabilidad? Para responder esta pregunta tenemos que ir al paper de Scott Lundherg y Su-In Lee.
Ellos plantean que se puede usar el valor de Shapley para explicar las predicciones de los modelos black-box. ¿Cómo? Explicando el score resultante como la ganancia de un juego cooperativo donde los jugadores son las variables predictoras sobre las que hay que calcular su contribución.
Los autores buscan una explicación más justa de los aportes de las variables que la controvertida importancia de las variables que algunos modelos nos entregan. Además, buscan explicar los scores para casos individuales y no los aportes globales de las variables al modelo, por ende, es un algoritmo de explicabilidad local.
Para esto, ellos desarrollan el concepto de SHAP (SHapley Additive exPlanations) Value, que busca explicar el score como la suma de las contribuciones marginales de variables a través de un modelo explicativo lineal: Donde
Donde
- g es el modelo explicativo de un modelo f que busca explicar el score para el punto x , o sea, f (x).
- M es la cantidad total de variables
- z' ∈ {0,1}M es un vector binario que representa a una coalición de variables, o sea, si tenemos las variables {A, B, C}, entonces z' = (0,1,1) representa a la coalición formada B y por C. Por ende, los z'j sólo pueden ser 1 o 0. Si el vector z' está compuesto de todos 1s, entonces lo definimos como x', refiriéndonos a x como el input que buscamos explicar.
- ϕ0 la esperanza de la salida del modelo en los datos de entrenamiento.
- Por último ϕj los parámetros del modelo cuyos valores buscan ser las contribuciones para cada variable.
Sin mucho esfuerzo podemos reemplazar para un modelo con los inputs A, B y C
Como vimos en el apartado anterior, la única forma de hacer esta distribución de manera justa es con los valores de Shapley. Si queremos ser más precisos, los autores usan otras propiedades deseables similares, pero no vamos a bajar a tanto detalle.
¿Y cómo calcular los SHAP value? existe un algoritmo llamado Kernel SHAP que es agnóstico al modelo, esto significa, que no importa cómo funciona el mismo, pueden ser árboles, redes neuronales, bayesianos, SVM, etc., kernel SHAP nos va a la contribución de las variables en el score.
4. Un ejemplo
Antes de adentrarnos a cómo funciona kernel SHAP, veamos como con un ejemplo como interpretar sus resultados, ya que los autores hacen gala que sus explicaciones son muy intuitivas.
Para esto vamos a seguir usando el conjunto de datos de esta serie de artículos que busca predecir qué empleados van a abandonar la empresa el próximo año. Modelamos con una red neuronal multicapa y buscamos entender para nuevos casos sus scores con kernel SHAP.
En el primer caso que analizamos para un empleado en puntual, nuestro modelo nos dio un score de 0.9916. Esto nos está diciendo que es empleado con una alta propensión a abandonar la empresa. Para entender cuáles son los drivers que pueden estar influyendo en un score tan alto, aplicamos kernel SHAP y nos devuelve el siguiente resultado:
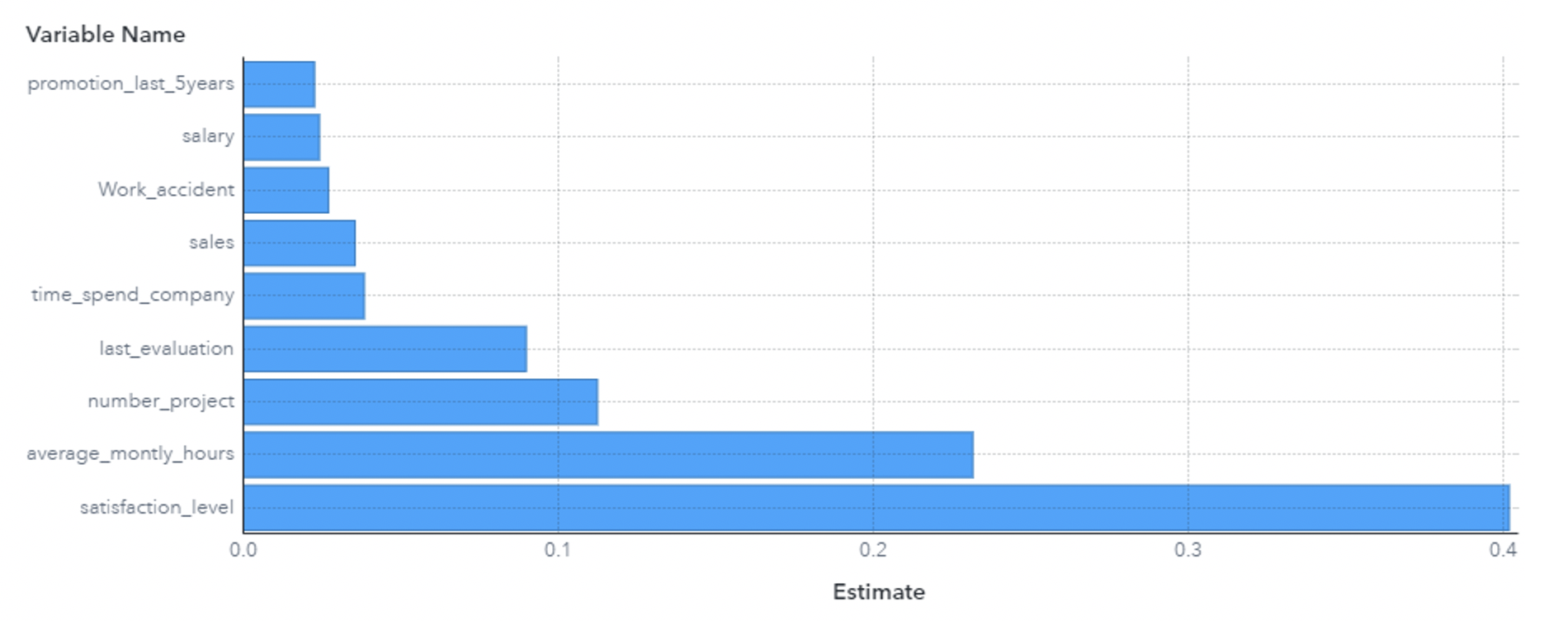
El gráfico nos muestra cómo contribuyen todas las variables, o sea, es el ϕ de cada variable. La mayor contribución la da el nivel de satisfacción, que cuando miramos el registro original, vemos que es de los más bajos. La segunda contribución es las horas promedio por mes, y cuando miramos la variable original, vemos que es uno de los que más trabajan, ya que tiene una gran cantidad de proyectos, la tercera variable que más contribuye.
En cambio, si miramos el caso de un empleado con un score de 0.0102, lo que significa, según el modelo es muy poco probable que se vaya de la empresa, la contribución de las variables es la siguiente.
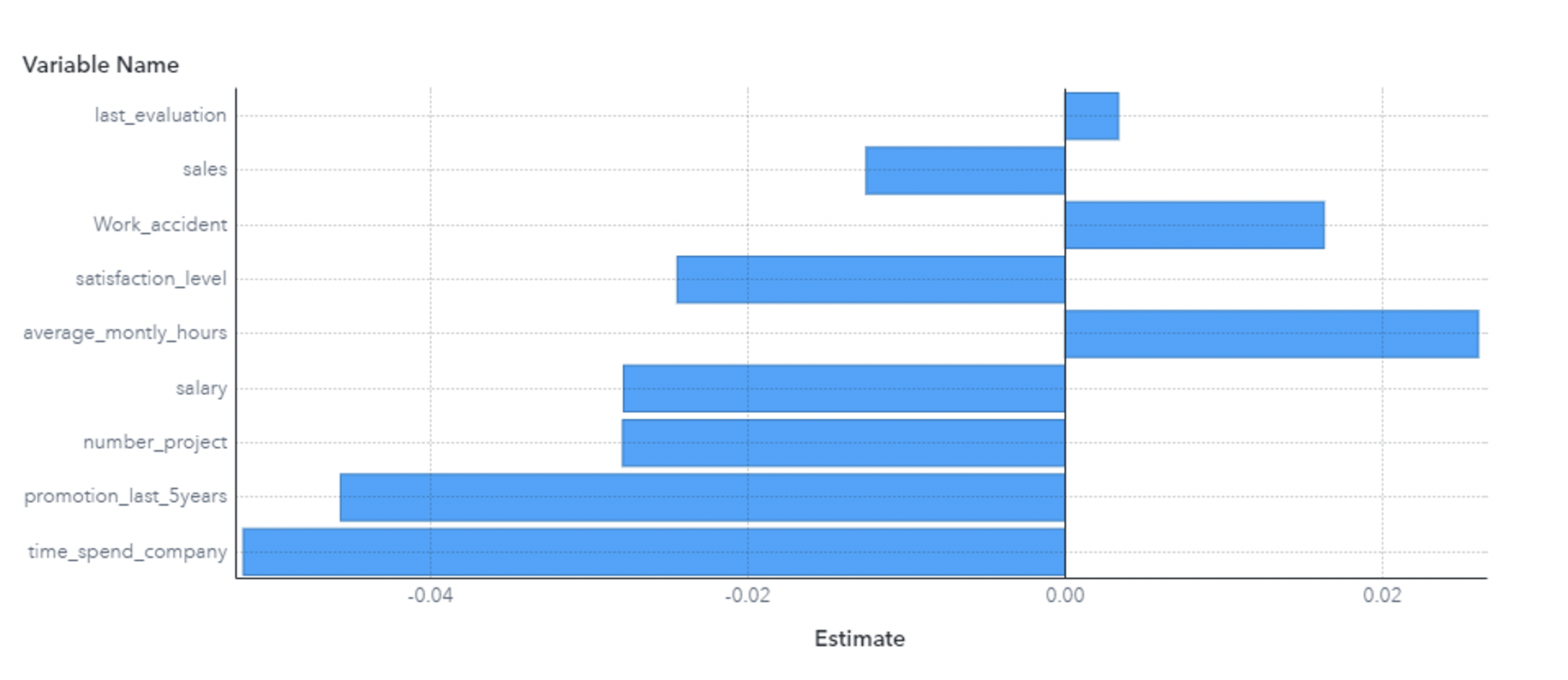
Vemos que tiene la mayoría de las variables menores que cero, lo cual es bueno si no queremos que abandone la empresa.
Si uno observa un poco más el último gráfico se podrá dar cuenta que, sin conocer números exactos, la suma de todos los valores va a ser menor que cero. ¿Cómo? ¿Cómo puede ser que la suma nos dé negativa si el score nos dio 0,0102?
Bueno, en ambos gráficos falta un valor que es la intersección de la regresión lineal, el ϕ0, que si recordamos es igual a la esperanza de la salida del modelo ajustado a los datos de entrenamiento. Como es un valor constante para todos los casos que se quieran explicar, no se agregó. En este último caso, al estar su score por debajo de esa esperanza, la suma total de las contribuciones da negativa.
Esto nos abre a otra forma de interpretar los resultados. Un empleado a scorear empieza con el valor esperado del modelo, ϕ0, y luego las variables lo aumentan o lo disminuyen cuando contribuyen de forma positiva o negativa. Podemos reflejar estos movimientos en el siguiente gráfico publicado en el paper original.

En los dos casos estudiados se chequea que, si sumamos todas las contribuciones y la intersección, conseguimos la totalidad del score, a diferencia de lo que sucedía con LIME, que nos ofrecía un valor cercano, pero no necesariamente el mismo. Otra diferencia que tiene con el LIME, es que kernel SHAP usa todas las variables y no sólo las más importantes.
5. ¿Cómo funciona Kernel SHAP?
Para trabajar con el valor de Shapley, tenemos que replicar la idea principal detrás de todo: medir la ganancia para las distintas coaliciones de variables, o sea, si queremos explicar la contribución de cada variable en un score f(A = 1.3 ; B= 0.5 ; C=2.1) = 0,32, necesitaríamos calcular la contribución de cada variable a través de las distintas contribuciones marginales: f(A = 1.3), f(B= 0.5 ; C=2.1), f(A = 1.3; C=2.1) y el resto de permutaciones.
Acá nos encontramos con la primera dificultad. Un modelo es una fórmula que espera una cantidad de variables. ¡No podemos hacer desaparecer esas variables!
Algún distraído pensará que bastará con pasarle por valor un missing: Luego de respirar hondo, se les puede recordar que eso es asignar un valor a la variable, no sacarla del modelo.
¿Y cómo se resuelve este pequeño gran problema? No es realmente muy difícil. Tomamos el caso el cual queremos explicar, luego armamos todas las posibles coaliciones de variables. Cuando una variable se encuentra en la coalición se deja el valor original del caso y cuando no, se reemplaza por una muestra aleatoria, o sea, para una coalición nos quedarían muchos nuevos registros. Veamos un ejemplo, si tenes un modelo y las variables de entrada con sus valores fueran A = 1,3; B= 0.5; C=2,1, y en la coalición solo contamos con las variables A y C, entonces se generarían los siguientes registros
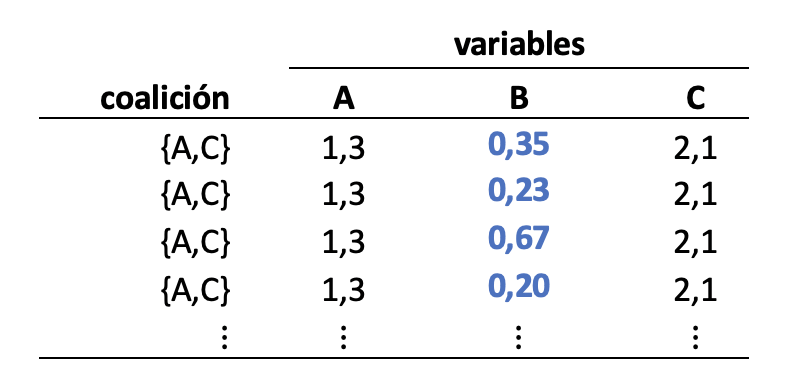
Donde todos los valores de B son tomados de forma aleatoria de otros registros de esa variable. La idea detrás de poner muchos valores de B, es tratar de reducir la dependencia de la variable en la coalición. Ese conjunto de registros puede interpretarse como la esperanza matemática condicional de la coalición.
Con todas las muestras para cada coalición armamos una tabla que se ponderan sus instancias con el kernel Donde
Donde
- M es la cantidad de variables
- |z’| es la cantidad de variables que se encuentran en la coalición.
Con las instancias ponderadas, los autores demuestran que si se realiza una regresión lineal ponderada las influencias de las variables (los de ϕ de g(x') que se obtienen son valores de Shapley. Una palabra: Precioso.
Vemos una fuerte conexión cómo funciona el algoritmo LIME que vimos brevemente en un artículo anterior, ambos modelos explicativos son lineales donde ponderan las instancias, recordando, que el LIME lo hace en función de la distancia que tiene la instancia con respecto al punto que queremos explicar.
6. Consideraciones de uso
Tres consideraciones del uso del algoritmo.
La primera es cómo afectan los valores aleatorios a las contribuciones. La respuesta es simple, con muestras distintas, las contribuciones van a ser distintas, ergo no siempre se va a explicar exactamente de la misma forma el mismo modelo. Parece algo grave, pero no lo es tanto, ya que, si bien hay variaciones, no cambian radicalmente las interpretaciones.
La segunda consideración, hay modelos que tienen la capacidad de trabajar con variables categóricas y datos faltantes sin problemas y sus variables de entrada tienen esa estructura. Kernel SHAP es un modelo regresivo, lo que implica que tiene todas las bondades y también todos sus defectos. En los casos que se encuentren esas variables se va a necesitar transformar las variables para poder usarlo.
Y la última consideración, por si se les pasó por alto, es que el algoritmo necesita evaluar muchas coaliciones. En un conjunto de datos con N variables ¿cuántas posibles coalisiones hay? 2N, un número muy grande.
Sin embargo, si miramos con detenimiento la fórmula de ponderación πx (z') y reemplazamos con algunos valores, para reflejar como varían los pesos en función de la cantidad de variables que entra en la coalición, para un conjunto de datos con 25 variables (M=25)
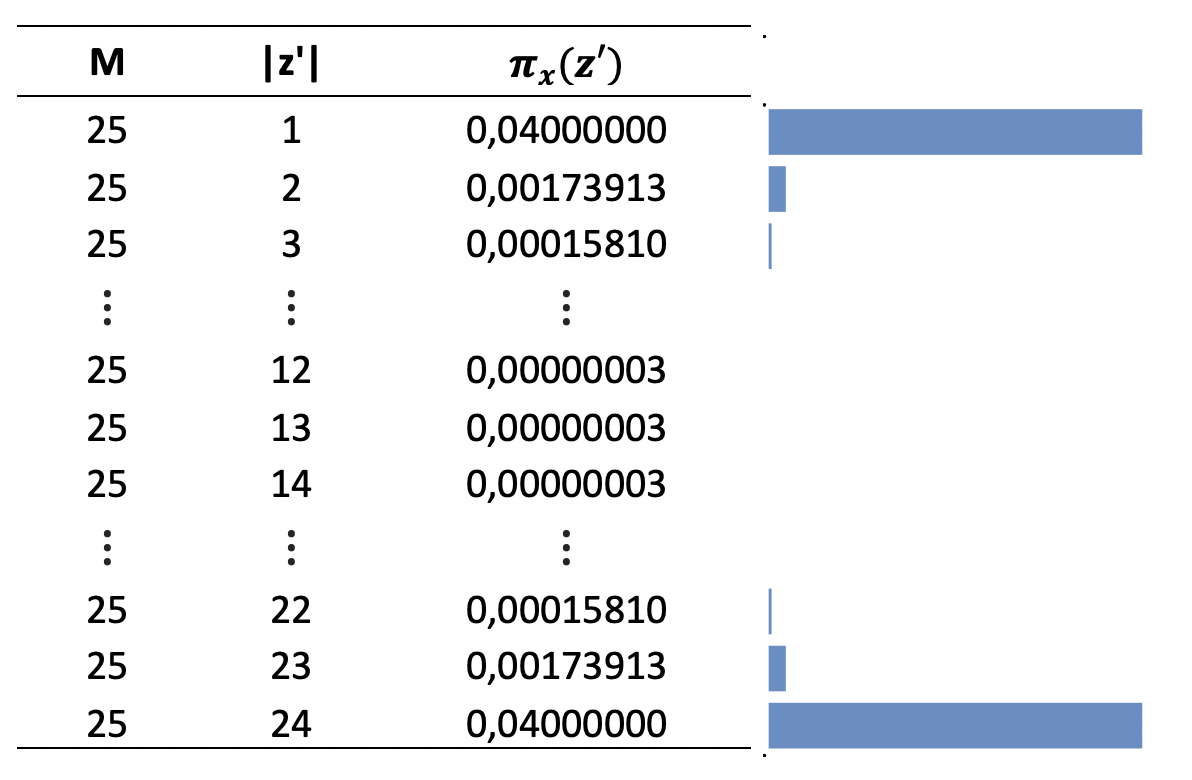 Claramente vemos que el peso de las coaliciones donde participan pocas variables y/o muchas variables son las que más peso tienen (las primeras filas y las últimas filas), con la cual cuando armemos datos para ajustar tenemos que concentrarnos en generar los casos para este tipo de coaliciones. Este reduce considerablemente el tamaño de los datos necesarios, y por consiguiente el procesamiento para el ajuste del modelo explicativo.
Claramente vemos que el peso de las coaliciones donde participan pocas variables y/o muchas variables son las que más peso tienen (las primeras filas y las últimas filas), con la cual cuando armemos datos para ajustar tenemos que concentrarnos en generar los casos para este tipo de coaliciones. Este reduce considerablemente el tamaño de los datos necesarios, y por consiguiente el procesamiento para el ajuste del modelo explicativo.
Si bien con esta forma de muestrear reducimos los tiempos radicalmente, no deja de ser un algoritmo lento y se recomienda su uso para entender casos puntuales, o una muestra si queremos una visión global, pero no está recomendado para usar con millones de casos a la vez.
Unos años después de la publicación del paper, los autores publicaron otro algoritmo, el TreeSHAP para algoritmos basados en árboles (Decision Tree, Random Forest, …) permite utilizar las estructuras de los árboles para calcular la función de ganancia. Con esta modificación se logran bajar los tiempos de cómputo… con algunos peros y consideraciones, que seguro veremos en un futuro artículo.
No quiero cerrar sin recomendar la lectura del libro de Christoph Molnar sobre interpretación de modelos. Un trabajo muy bueno que se encuentra disponible de forma gratuita y que me ayudo a aclarar grises.

1 Comment
Muy buen artículo Alejandro, Kernel Shap rocks!