Toc, toc, toc. En algún lugar de Berlín a comienzos del siglo XX, tras esos pequeños tres golpes, se podía observar inconfundibles caras de asombro entre los periodistas y curiosos. En cambio, Wilhelm Von Osten reflejaba en su rostro algo más: felicidad, realización y por qué no, el disfrute de las futuras mieles que le producirían su logro. Verán mis amigos, siempre se creyó hasta ese momento que las matemáticas eran de dominio exclusivo de los seres humanos… y no necesariamente de todos. Es por esta pequeña presunción que el mundo se enmudeció cuando Clever Hans podía responder a preguntas como: ¿Cuánto es 2+3? ¿y 3 x 4? ¿Cuál es el combinatorio de (3 2)? Pues Clever Hans ¡era un caballo!
Von Osten fue un profesor de matemática (¿cuándo no?) que entrenaba caballos para que puedan resolver problemas complejos, respondiendo a las preguntas con golpes de sus pezuñas contra el piso. Y contra todo pronóstico Von Osten logró su cometido: Le preguntó a un caballo cuánto es 2 + 1 y este respondió con tres tocs. Con tamaña victoria empezó a brindar entrevistas y a recorrer el país haciendo espectáculos mostrando su gran hallazgo.
Las malas lenguas que se encuentran en los oscuros foros de internet dicen que los matemáticos temían ser reemplazados por animales a los que sólo debían pagarles con alfalfa, por eso decidieron financiar la investigación a un tal Oskar Pfungst. Hicieron bien, el bueno de Oskar reveló que Clever Hans, era realmente muy listo, pero no en las artes numéricas, sino en el entendimiento del lenguaje corporal. Clever Hans cuando le hacían una pregunta empezaba a patear y observaba los gestos del rostro de Von Osten que inconscientemente hacía a medida Clever iba llegando a la respuesta correcta. El caballo nunca aprendió matemática, solo aprendió a parar. Los matemáticos respiraron aliviados y me gusta pensar que Hans paso el resto de sus días feliz en una granja sin las enceguecedoras luces del espectáculo.
Detengámonos a reflexionar lo que sucedió. Von Osten entrenó una red neuronal (empaquetada en un caballo) usando ejemplos. Por dificultades biológicas, le era imposible entender qué era lo que realmente había aprendido Clever Hans, sólo podía probar su “aprendizaje” con nuevos ejemplos. No lo probó con la suficiente objetividad. Pero cuanta culpa se le puede echar a pobre profesor por dejarse llevar por los buenos resultados de su “modelo”. Y nos hace pensar… que quizás hoy en día algo similar pueda estar pasando con varios modelos basados en algoritmos black-box.
Continuamos con la serie de artículos sobre explicabilidad de modelos black box ([I], [II], [III]), buscando entender como puntúan los algoritmos y en evitar sesgos o errores que se puedan estar produciendo.
LIME
En este artículo abordaremos el algoritmo LIME, un algoritmo desarrollado por Marco Tulio Ribeiro, Sameer Singh, y Carlos Guestrin en el paper "Why Should I Trust You? Explaining the Predictions of Any Classifier".
LIME son las siglas de LOCAL INTERPRETABLE MODEL-AGNOSTIC EXPLANATIONS. Como su nombre lo dice, es un algoritmo agnóstico, o sea puede ayudarnos a dar luz a cualquier tipo de modelo. La "L" de Local, nos dice que nos da interpretaciones de casos puntuales, nos responde preguntas: ¿Por qué el modelo dice que a Jorge está por abandonar la empresa y plantea que Mauro no?
¿Cómo aplicar el algoritmo?
Seguimos con el conjunto de datos de los artículos anteriores, tratando de estimar qué empleado va a abandonar la empresa en el siguiente año, utilizando modelos con una gran precisión, pero difíciles de interpretar. Puntalmente para los siguientes ejemplos usaremos una red neuronal de dos capas.
Supongamos que nuestro modelo dice que Jorge tiene un score de 0.88 para abandonar la empresa (un score muy alto), y queremos entender por qué. Para esto aplicamos LIME sobre nuestro inescrutable modelo sobre la instancia de Jorge, y este nos devuelve que su puntuación se compone de:
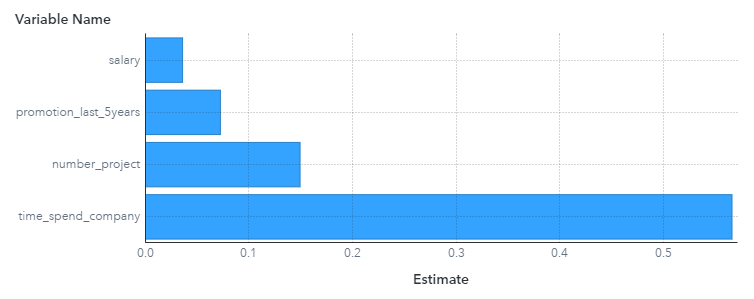
- 0.04 porque se encuentra en la categoría más baja de la escala salarial.
- 0.07 lo aporta que no ha tenido ningún ascenso en los últimos 5 años.
- 0.15 se debe a que estuvo trabajando en 6 proyectos en el último año.
- 0.57 por la variable tiempo que está en la compañía, está hace 6 años.
Vemos que si sumamos todos los aportes no nos da el score original de 0.88. Esto se debe a que es una aproximación explicativa y sólo con las variables más influyentes, resta un 0.05 sin explicar. Igualmente nos basta para tener una visión de la situación de Jorge de acuerdo con el modelo. ¿Qué sugiere que deba hacer su jefe si quiere retener el talento de Jorge dentro de la compañía?
Sigamos con un caso más feliz, el de Mauro con un score de 0.22, LIME nos dice que:

- 0.026 se debe a que se encuentra en la categoría más baja de la escala salarial.
- -0.11 son explicados por que tuvo 3 proyectos durante el año.
- 0.33 el mayor aporte nuevamente se debe a que se encuentra en la compañía hace 5 años.
Vemos que no todas las variables van a aportar en forma positiva al score. En el caso de Jorge, la variable número de proyectos afecta al score en forma positiva. En el caso de Mauro, en forma negativa. O sea, haber tenido 3 proyectos solamente hace que Mauro tenga menos ganas de irse de la empresa.
Y así se puede continuar con todos los casos que son críticos o que nos puedan llamar la atención, al igual que controlar que no se escape ninguna variable extraña entre los cientos que uno suele poner y que nos puede estar contaminando el modelo.
Junto con el modelo SHAP que explicaremos en el siguiente artículo, ambos abren una importante puerta a la utilización de algoritmos más avanzados en el mundo del riesgo crediticio y de aquellos dominios donde un cliente pueda requerir el porqué de la decisión de una empresa. Pero no nos adelantemos mucho, ya abordaremos esa temática en breve.
Entonces, ¿Cómo funciona LIME?
La idea detrás LIME es que, en entornos cercanos a la instancia, cualquier modelo se puede explicar con una función lineal (uff, uno nunca puede escapar del análisis matemático…).
La construcción de esta función lineal se realiza de una forma muy simple. Partiendo del modelo y de una instancia que queremos explicar, tomamos una pequeña muestra alrededor de nuestra instancia y la ponderamos: mientras más lejos están los puntos de la muestra menos peso tienen; más cerca, más peso. Sobre nuestra muestra ponderada ajustamos un modelo Lasso con la predicción de salida de nuestro modelo a explicar. ¿Por qué un Lasso? Si adivinó mi pícaro estadístico, para poder quedarnos con las K variables que son más significativas, solamente vamos a explicar el comportamiento con unas pocas variables.
Para determinar el impacto de la instancia simplemente se multiplica la beta de la variable con el valor de ésta que posee la instancia. Simple.
