Pueden acceder a la parte I de esta serie de artículos en este link.
Antes de continuar donde dejamos el artículo anterior, veamos un artículo publicado hace unos días que tiene ver con nuestro tópico: How Important is that Machine Learning Model be Understandable? We analyze poll results. Este artículo muestra los resultados de una encuesta hecha hace unos días por la gente de KDnuggets, donde se le pregunta a la comunidad qué tan importante es que sus modelos sean entendibles por humanos, y donde el 85% de las respuestas confirmaron que siempre o frecuentemente es requerido. Un número más alto del que esperaba.
Al momento de publicar la encuesta, la plataforma referenció un caso muy comentado este año: el de un importante retail online que desarrolló un software de reclutamiento que usaba AI para ayudar a revisar los currículos y hacer recomendaciones. El software resultó favorecer a los hombres porque su modelo fue entrenado con los currículos presentados en una época donde la mayoría de la planta era masculina, por lo que la empresa decidió discontinuarlo (más detalle en Amazon scraps secret AI recruiting tool that showed bias against women).
Este ejemplo ilustra cuán importante es conocer la forma en que los modelos toman decisiones. Es fundamental para poder encontrar errores en el diseño del experimento (aunque errores de este tipo podrían ser favorables a la humanidad como muestra este comic de SMBC rise of the machines).
Volviendo a la línea principal de esta serie de artículos, la idea es explorar diversas técnicas para entender como predicen los modelos de machine learning avanzados, utilizando un caso de uso de churn de empleados. Es decir, tratar de predecir quienes son los empleados que van a abandonar una empresa en el transcurso del siguiente año. Esta es una de las problemáticas que trata la rama People Analytics (también conocida como HR Analytics o Workforce Analytics) que se está volviendo cada vez más importante dentro de las empresas que dependen del valor de su capital humano para mantenerse competitivas. En particular, la renuncia de un empleado a una empresa puede generar un gran dolor para la misma, y poder entender qué empleados tienen mayor propensión a irse es un insight muy valioso que se puede utilizar para prevenir la partida… si es que esta no se desea.
Para predecir el churn de empleados, contamos con un conjunto de datos con 15.000 registros aproximadamente, de los cuales cerca del 20% termina renunciando. Las variables que cuentan son: sector al que pertenece, rango salarial (bajo-medio-alto), antigüedad, encuesta de satisfacción, cantidad accidentes que tuvo, última evaluación, cantidad de proyectos, promedio de cantidad de horas trabajadas por mes y promociones que haya tenido.
Se aplicaron dos modelos del tipo black box, un gradient boosting y una red neuronal. En ambos casos sus parámetros se buscaron por autotunning, dejando a la máquina el esfuerzo de encontrar la mejor combinación de parámetros (mientras el buen científico de datos se toma un café). El mejor modelo resultó ser el gradient boosting, pero como no es el fin de este artículo no vamos a profundizar en los estadísticos resultantes.
Partial Dependence Plots (PDP)
La primera técnica a evaluar muestra el efecto marginal de una variable en el valor predicho por el modelo. PDP muestra si la relación entre el target y una variable de entrada es lineal, monótona o más compleja. Su construcción es simple, para profundizar pueden consultar el paper de Friedman [1]. En esta técnica, es importante destacar dos cosas:
- Es un método agnóstico al modelo, no importa el algoritmo que se usó: Random Forest, Redes Neuronales, etc. Para construir los gráficos necesita solamente de la entrada de datos que se usó para entrenar y la salida del mismo (predicción).
- Es un método global: se construye utilizando la totalidad de los casos o una muestra representativa de estos. De esta forma, la técnica explica como una variable influye al target con respecto a la población, a diferencia de los otros métodos que se enfocan en entender la relación del modelo con un individuo.
En nuestro caso trabajamos con pocas variables, algo que no es habitual... para nada. Por eso la recomendación a la hora de analizar las variables es usar el indicador de importancia de variable. La importancia de variable depende del algoritmo y de su parametrización, pero en nuestro ejemplo, la variable más importante es el nivel de satisfacción del empleado para ambos modelos, y por eso mismo empezaremos analizando esta variable:
Gradient Boosting
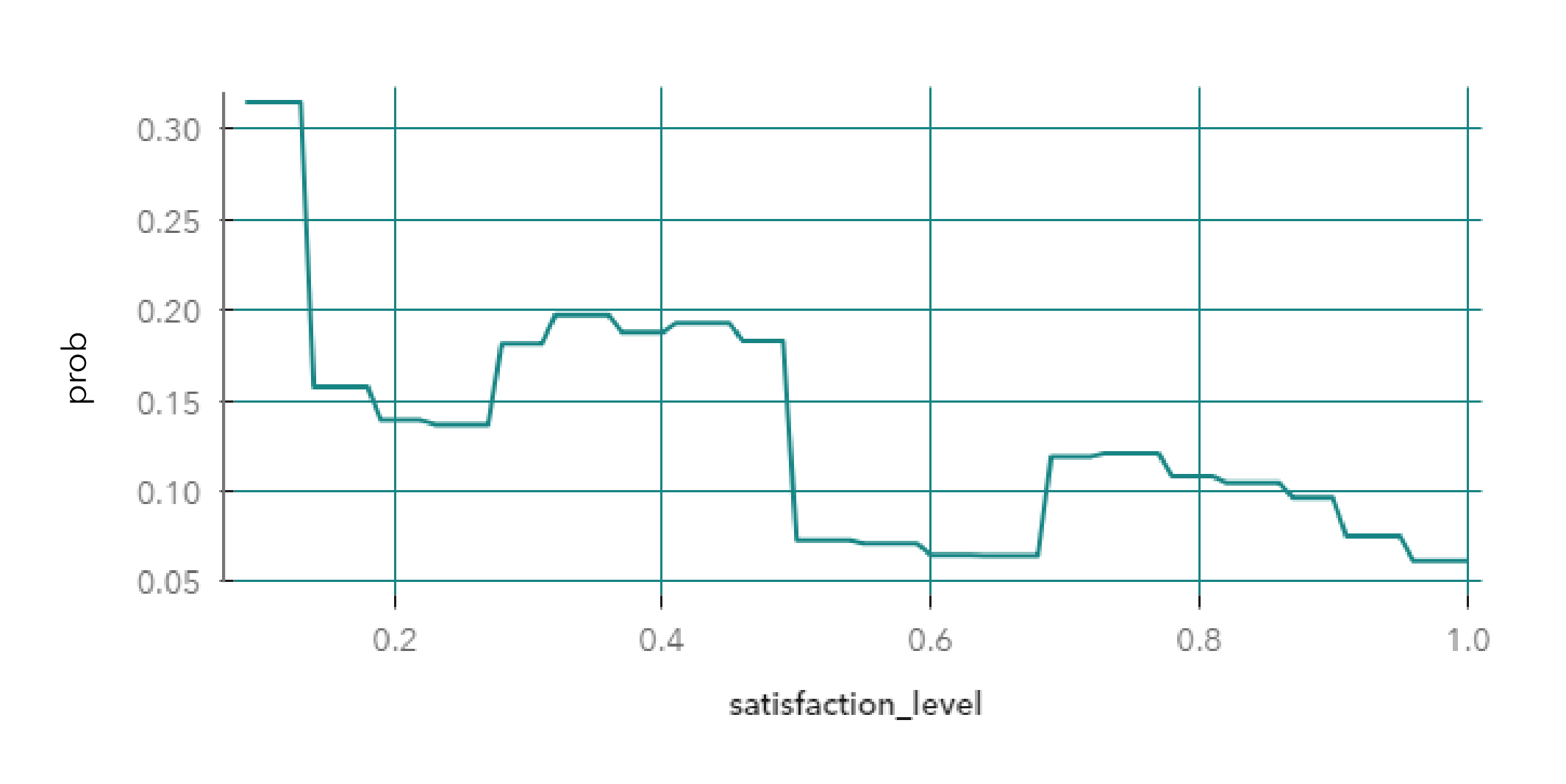
Red Neuronal

Ambas curvas reflejan claramente (hasta con cierta belleza) la forma en que cada algoritmo aprende. Primero el gradient boosting, con sus cortes rectos, propio de un ensamble de árboles de decisión, que se ajusta a la forma de los datos como un termoplástico. Por otro lado, la red neuronal se ajusta a los datos con curvas suaves. En estos ejemplos, se lee claramente que en ambos casos la contribución de la variable a la probabilidad de abandono (eje y) es mayor cuando el empleado se encuentra insatisfecho (eje x). El modelo de gradient boosting marca la presencia de segmentos intermedios, a diferencia de la red neuronal que mantiene un segmento y luego desciende suavemente hasta decidir que los empleados más satisfechos tienen menor probabilidad de irse.
Sólo como mero ejercicio, si para la misma variable analizamos un modelo logístico, únicamente veríamos una interacción puramente lineal (como es de esperar). Nos perderíamos la riqueza de los modelos anteriores, además de su precisión.
Regresión Logística

Continuamos analizando la dedicación en horas (promedio) por mes:
Gradient Boosting

Red Neuronal

En esta variable vemos que a mayor cantidad de horas, mayor es la probabilidad de perder a un empleado. La red neuronal platea que esta probabilidad va a crecer de forma (casi) lineal, cuando el gradient boosting lo plantea de una forma más abrupta. Una explicación plausible de este comportamiento podría verse si complementamos al PDP con el histograma de la variable.
Por último, veamos un PDP sobre una variable categórica, como es el rango salarial. Ambos modelos coinciden en que mientras más alto es el sueldo, menor es la probabilidad de que el empleado se vaya.
Gradient Boosting

Red Neuronal

Brevemente analizamos los resultados con un ejemplo práctico para ver como los modelos actúan frente a los cambios de una variable. Hay que tener presente que no siempre ver la interacción de una sola variable es suficiente. Pero nos ofrece una opción, no sólo para entender como un modelo ve a un fenómeno, sino también para elegir el modelo que lo interprete mejor.
Los espero en la próxima entrega.
[1] J. H. Friedman. Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29:1189–1232, 2001.
