Im vorangegangenen Blog habe ich die „vier Säulen des Vertrauens“ für automatisierte Entscheidungen vorgestellt. Dieser hat gezeigt: Erklärbarkeit und Transparenz beziehen sich auf den gesamten analytischen Prozess. Wie sieht es aber mit der „Blackbox“ der maschinellen Lernalgorithmen aus? Auch dort muss Transparenz durch eine analytische Plattform gewährleistet sein.
Die gute Nachricht: Ganz so dunkel sind Algorithmen gar nicht. Wenn wir auch keine leicht verständlichen Regelwerke ableiten können, so können wir doch – unabhängig vom konkreten Verfahren – untersuchen, was entscheidende Faktoren bei der algorithmischen Entscheidung sind. Das Forschungsfeld, das sich mit dieser Erklärbarkeit beschäftigt, heißt „Fairness, Accountability, and Transparency in Machine Learning“, kurz: FAT ML.
Was macht einen guten Algorithmus aus?
Gelernte Modelle sollen nicht nur gut, sondern auch interpretierbar und fair sein. Was heißt das genau? Dafür sind folgende Fragen zu beantworten:
- Gibt es Auffälligkeiten in den Trainingsdaten, die das maschinelle Lernmodell zwangsläufig übernommen hat? Wer die Daten auswählt oder kontrolliert, bestimmt nämlich schon wesentlich die erlernbaren Zusammenhänge mit. Das führen eindrückliche Beispiele vor Augen: Microsofts Chatbot Tay ist durch gezielte Nutzerinteraktionen vom „freundlichen Gesellen“ zum Hater geworden, beim Projekt „Norman“ haben MIT-Forscher ein Lernverfahren gezielt durch Datenauswahl zum „Psychopathen“ erzogen.
- Sind wichtige Zusammenhänge in den Daten ordentlich abgebildet? Kann sich jeder auf das gelernte Modell verlassen? Das Modell mag zwar auf die Trainingsdaten angewandt gut funktionieren, aber sind die erlernten Zusammenhänge allgemein genug, um sie auf neue Daten zu übertragen?
- Ist das Modell diskriminierungsfrei? Zum Beispiel darf eine Versicherung das Merkmal „Geschlecht“ oder dazu stark korrelierende Merkmale nicht zur Tarifierung verwenden. Und nicht nur diese recht einfach zu erkennende Art der Unterscheidung von Anspruchsgruppen ist problematisch. Bekomme ich den schlechteren Tarif oder den teureren Kredit, weil ich den falschen Vornamen habe? Bekomme ich den Job nicht, weil ich das falsche Geschlecht habe? In Daten kann mehr oder weniger starke strukturelle und kulturelle Voreingenommenheit stecken, die dann algorithmisch gelernt und sogar verstärkt wird.
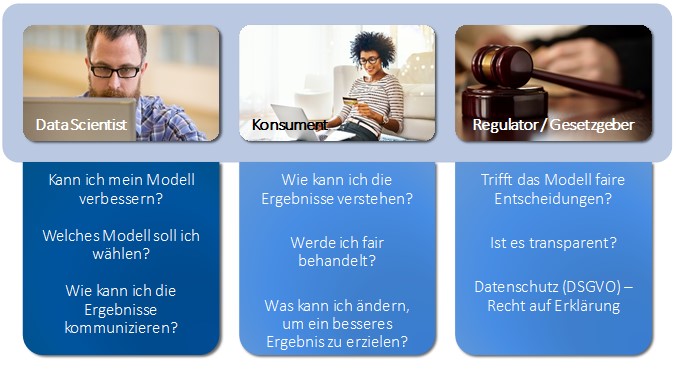
Diese und ähnliche Fragen sind aus unterschiedlichen Perspektiven für Unternehmen, Konsumenten, Behörden und Gesetzgeber wichtig, wie die folgende Abbildung zusammenfasst.
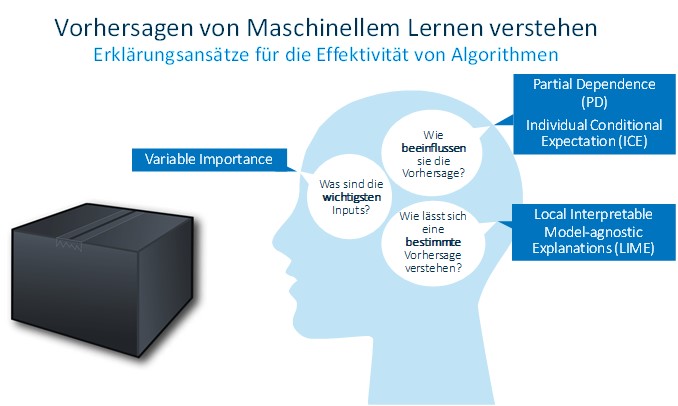
Welche Möglichkeiten gibt es nun, in die Blackbox eines Algorithmus zu schauen? Dies ist, wie oben angedeutet, ein aktuelles Forschungsfeld. Einige Erklärungsansätze für die Effektivität von Algorithmen fasst die folgende Grafik zusammen. Wichtig ist, dass alle diese diagnostischen Verfahren unabhängig vom konkreten maschinellen Lernalgorithmus (modell-agnostisch) sind.
Schauen wir uns am Beispiel „Partial Dependence“ (PD) an, wie man sich solche diagnostischen Möglichkeiten vorstellen kann. Angenommen, wir haben für eine medizinische Diagnoseanwendung ein Modell trainiert, das anhand von Patientenmerkmalen die Wahrscheinlichkeit bestimmen soll, dass der Patient unter Grippe leidet.
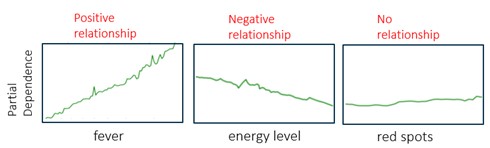
Fieber versus Hautausschlag
Ein PD-Diagramm stellt die funktionale Beziehung zwischen den einzelnen Modellinputs (also zum Beispiel Fieber, Allgemeinzustand und Hautausschlag) und den Vorhersagen des Modells dar. Ein PD-Diagramm bildet auch ab, wie die Vorhersagen des Modells von den Werten der interessierenden Eingangsgrößen abhängen – wobei gleichzeitig der Einfluss aller anderen Merkmale berücksichtig wird. So hat Fieber im Diagramm unten einen stark positiven Einfluss auf die Grippewahrscheinlichkeit, der Allgemeinzustand des Patienten einen leicht negativen, während der Hautausschlag eher indifferent ist.
Um diese Grafiken zu erstellen, müssen wir für die möglichen Werte des untersuchten Inputs feststellen, welche durchschnittliche Wahrscheinlichkeit für Grippe das fragliche Modell vorhersagt, wenn wir die anderen Inputs variieren. Im Beispiel: Für die Erstellung der PD-Grafik für „Fieber“ wird das jeweilige Vorhersagemodell mehrmals mit einem bestimmten Fieber-Wert (z. B.: 36,2 °C) und einer zufälligen Variation aller anderen Merkmale befüttert. Der Mittelwert der Modellvorhersagen (also die Wahrscheinlichkeit für die Diagnose „Grippe“) wird als PD-Wert für Fieber = 36,2 eingetragen. Dies wird nun für alle Fieber-Werte (36,3; 36,4; 36,5; …) wiederholt, woraus sich die grüne Linie in der Grafik ergibt. Diese zeigt uns schließlich den Einfluss von „Fieber“ bei gleichzeitiger Berücksichtigung aller anderen Merkmale.
Wie dieses Vorgehen zeigt, müssen wir das Modell nicht „aufbohren“: Es ist egal, wie es im Inneren strukturiert ist und wie es algorithmisch zustande kommt. So haben wir mit der Partial Dependence ein Diagnosewerkzeug, das einen speziellen Aspekt maschineller Lernalgorithmen transparent machen kann.
Dieses und andere Verfahren sind bei SAS übrigens bereits an Bord.
Die schwarze Kiste lässt sich öffnen
Fazit meiner kleinen Blogserie: Jeder, der mittels KI Prozesse und Entscheidungen automatisiert, muss sich mit den beschriebenen ethischen Aspekten auseinandersetzen – aus moralischen, regulatorischen und praktischen Gründen. Denn schließlich möchte kein Unternehmen, dass sich schlechte Resultate negativ aufs Image auswirken. Erklärbarkeit und Transparenz beziehen sich auf den gesamten analytischen Prozess, nicht nur auf einen Algorithmus des maschinellen Lernens, der eine Entscheidung automatisiert. Aber auch die berühmt-berüchtigten Machine-Learning-Algorithmen sind keine für immer und ewig verschlossene Black-Box. Eine Rechtfertigung für die Folgen des KI-Einsatzes kann niemals sein: „Der Algorithmus hat mich dazu gebracht“. Erst Vertrauen und Transparenz bauen Hürden für den Einsatz von KI ab – zum Vorteil von Verbrauchern, dem Gesetzgeber und Unternehmen, die Datenanalysen einsetzen.
"AI Momentum, Maturity and Models for Success" - Ergebnisse aus einer globalen Umfrage unter 305 Führungskräften und Vordenkern





