
Imagine if your job was to sort a massive pile of 40,000 stones into about 200 buckets based on their unique properties.
Each stone needs to be carefully examined, categorized and placed in the correct bucket, which takes about five minutes per stone. Fortunately, you’re not alone but part of a team of stone sorters explicitly trained for this task.
Once all the stones are sorted, your team will analyze each bucket and write detailed essays about the stones in them. Overall, this entire process, including training and reviewing, will take your team somewhere between 4,000 and 8,000 hours, equivalent to two to four people working full time for a year.
This grueling sorting process mirrors what government agencies face when dealing with thousands of public comments on proposed regulations. They must digest and respond to each point raised by the public (including corporate stakeholders) in response to a proposed regulation. They must do so to ensure they are protected from a lawsuit. Hence, a rigorous response is necessary every time public comments are provided. Fortunately, with advancements in text analytics and GenAI, this task can be managed effectively while maintaining accuracy.
Improving government processes with text analytics and GenAI
A robust approach has been developed, combining natural language processing (NLP), text analytics and a large language model (LLM) to streamline handling public input. While technology takes over a large part of the otherwise manual work, the subject matter experts stay at the center of the process.
Through text analytics, linguistic rules are used to identify and refine how each unique statement aligns with a different aspect of the regulation. This eliminates the need for arduous manual tasks. Given that government agencies often seek feedback on up to 200 different aspects of regulation, this automated matching process significantly boosts efficiency. Following this, the LLM creates initial summary statements for each regulation aspect based on the identified statements, which a smaller team can fine-tune. This innovative approach assists in the simultaneous handling of multiple regulations, empowering the team to use their creative expertise more effectively.
Putting GenAI and text analytics to the test
We used SAS® Visual Analytics to apply this process to a proposed regulation from the US Environmental Protection Agency (EPA) regarding the transfer of oversight of carbon capture wells to the state of Louisiana. With more than 40,000 comments received, we identified more than 10,000 unique statements. To illustrate this process, we first used text analytics to identify statements containing a concrete recommendation from organizations that were negative toward the regulation overall. We then used GenAI to generate summary information. We developed an interactive dashboard within SAS Visual Analytics to help users verify the summary of recommendations from individuals and organizations who generally oppose the regulation or aspects of it.
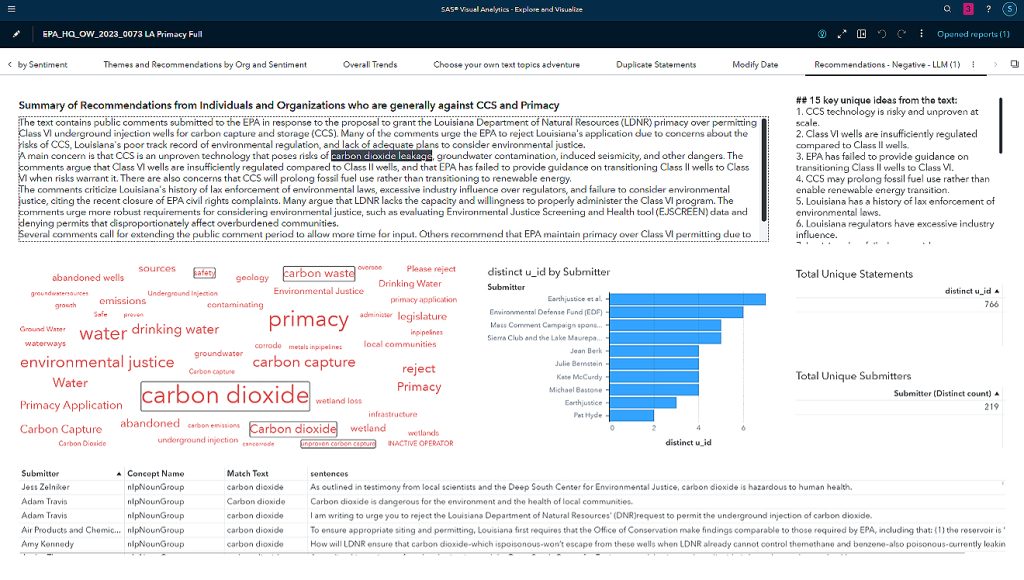
In Figure 1 of the dashboard, the summary descriptions provided in the top and top-right boxes highlight how the LLM summarized the key information. By asking specific questions as headers for each box and providing a summary and 15 key unique ideas, we created an accurate and compelling description of how the public negatively perceives the proposed regulation and how it might be concretely improved.
While tens of thousands of statements are submitted for this regulation, using NLP and text analytics as a pre-filter allowed us to feed only around 5% of the most pertinent statements to the LLM, enabling it to generate an accurate and traceable summarization at less cost. The summary information generated by the LLM can be verified by drilling down into the statements that fed it. In the example, the LLM suggests that carbon dioxide leakage is one of the leading public concerns. For instance, our text analytics process identified key terms such as "carbon dioxide," "carbon waste," "safety," and "unproven carbon capture," aligning with the LLM results illustrated in the word cloud. Through the interactive capabilities offered by SAS Visual Analytics, we could drill down into statements related to these themes to verify the responses generated by the LLM.
Similarly, the dashboard enables exploration of the other critical themes suggested by the LLM, including groundwater contamination, sufficient oversight by Louisiana and concern over well abandonment.
This integration of NLP and SAS Visual Analytics can help other users by:
- Avoiding hallucinations: The NLP and text analytics pre-filtering process assimilates the most relevant source data from various documents, ensuring the outputs are more accurate and reliable.
- Enhancing time to value: By pre-filtering the data, a smaller LLM can handle GenAI tasks more efficiently, leading to quicker results.
- Ensuring privacy and security: Using a local vector database for fine-tuning generative models is possible. This gives users only relevant embeddings to the LLMs via APIs or localized instances of the LLM, ensuring the privacy and security of sensitive data.
- Reducing costs: Text analytics and NLP significantly reduce the amount of information sent to the LLMs. In some cases, only 1 – 5% of the overall data is used for answers. This eliminates the need for excessive external API calls and reduces the computational resources required for localized LLMs.
- Supporting verification: SAS® Viya® enables end-to-end verification and traceability of results, helping users to verify information and trace it back to the statements from which the summaries were derived, potentially thousands of statements. This traceability feature enhances transparency and trust in the generated outputs.
As governments use LLMs to improve productivity and communication, it will be necessary to maintain the accuracy and rigor of existing methods while managing the costs of new technologies. This approach of integrating NLP and text analytics with LLMs allows a government to perform lengthy and complex tasks easier, faster, and less expensively without some of the risks inherent in using GenAI.
