The “big” part of big data is about enabling insights that were previously indiscernible. It's about uncovering small differences that make a big difference in domains as widespread as health care, public health, marketing and business process optimization, law enforcement and cybersecurity – and even the detection of new subatomic particles.
But the "bigness" of your data is not its most important characteristic. Here are three other considerations when it comes to getting value from big data.
Big variety
Of the three “V’s” of big data (volume, velocity and variety), the best advice for many organizations is to forget about big volume. For my money the real value in big data comes from its variety.
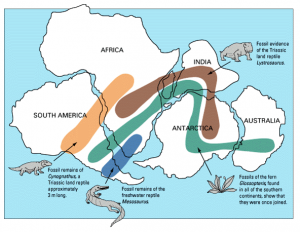
Consider this example from the natural sciences – the discovery and eventual acceptance of plate tectonics. First proposed as the theory of Continental Drift by Alfred Wegener in 1912, it was not until the 1960’s that it was fully accepted based on the overwhelming data-driven evidence acquired across a wide variety of fields:
- Geography: Maps that fit Africa together with South America.
- Geology: Matching geological structures found on both continents.
- Paleontology: Fossil plants and animals on present-day, widely separated continents form definite, connected patterns.
- Bathography: Post-WWII sonar revealed the Mid-Atlantic ridge including a narrow gorge precisely along the crest where the plates were separating.
- Oceanography: Magnetic seafloor mapping revealed a pattern of alternating magnetic striping on either side of that ridge.
- Seismology: Instruments showed that earthquakes are concentrated along the plate boundaries - oceanic trenches and spreading ridges.
Getting value out of your variety is first and foremost a data integration task. Don’t let your big data become Big Silos. Start within a function, like production or marketing, and integrate those data silos first.
For example, in customer service, bring together the separate web, call center and field service data. The next step is to integrate your more far flung disparate systems – valuable insights arise when you’ve got a holistic view of customer and product attributes along with sales data by channel, region and brand.
The value from data integration grows exponentially with each additional data source. Big variety is the future of big data.
Big model
With all the hype over big data, we often overlook the importance of modeling as its necessary counterpart. There are two independent limiting factors when it comes to decision support: The quality of the data, and the quality of the model.
Most of the big data hype assumes that the data is always the limiting factor, and while that may be the case for the majority of projects, I’d venture that bad or inadequate models share more of the blame than we care to admit.
 It’s a balancing act, between the quantity and quality of our data, and the quality and fit-for-purposeness of our models, a relationship that can frequently get out of balance.
It’s a balancing act, between the quantity and quality of our data, and the quality and fit-for-purposeness of our models, a relationship that can frequently get out of balance.
In one instance we may have remarkable models starved for good data, and on the other hand, volumes of sensor or customer data sit idle with no established approach for exploration, analysis and action.
“Recognizing that all of our decisions are based on our models of reality, not reality itself, is a key to understanding decision making. Too many individuals concentrate their efforts on perfecting “the data” that they then proceed to process through models that have little or no semblance of reality. Good models can still generate quality decision support information when the data is less than perfect, but bad models can only generate misleading decision support information – even when the data is perfect. Data is great, but it cannot become quality, actionable information unless it is processed through a valid model.” (~ Douglas Hicks, principle, D.T. Hicks Management Consulting)
Data and models, however, exist not in a vacuum but in the context of a larger decision support system, which is where you should always begin the process: What problems must the business address? What questions does the business need answered? What insights does the business need for innovation? What business decisions and actions need quantitative support? Build your models to support these issues and only then pursue the required data. Big data is the servant, not the master.
Big quality
Unlike data acquisition, which can accumulate exponentially, we generally address data error correction on an exception basis, using manual, linearly-scaled resources. We cannot possibly scale manual data correction to keep up with our increased data volumes, which means we must automate our data quality processes to catch and fix those errors up front with tools at least as robust as our data collection and storage resources.
80 percent of corporate data is unstructured, making it perhaps the single largest potential source of big data. As we start to process, structure and store that unstructured data, through techniques such as text analytics and content categorization, we need to remember to apply the same data quality standards that we do to more traditional transactional data.
To make a data quality initiative work, you need to understand how your business users are going to interact with the data, which in most cases will start with a “search” and then extend into analysis of specific associated terms / fields / categories. Data definitions will need to be just as rigorous for unstructured as for transaction data.
Developing the business rules will likewise come from an in-depth understanding of the user requirements – warranties will be associated with both products and services, products will have part numbers, which via a BOM can be related back to vendor part numbers for the various sub-components, etc.
The biggest challenges will not be between, say, structured customer relationship management and structured product ERP data, but between your structured and unstructured data. Avoiding big silos of bad data will not be an easy task, but can be tackled with a focus on both data integration and data quality.
Extracting tangible value and insights from high-quality, integrated data, no matter its volume, velocity or variety, is where the payoff lies. The consumers of this data, the business users, don’t know or care about its bigness – they just want the right data applicable to their particular business problem, and they want to be able to trust that data and the analysis derived from it.
