Data for Good: 満員電車をなくすことはできるか
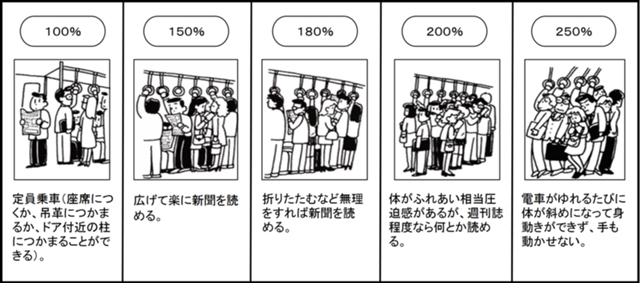
前回のブログ記事では、Data for Good活動の一環として、世界の絶滅危惧種についての考察をしました。本記事では、朝ラッシュ時の鉄道混雑について考えます。 首都圏における鉄道の通勤通学時間帯混雑率は、長期的にみて改善されているものの180%を超える路線が11路線あるなど(2017年)依然として満員電車は解消されていません。不快感や身体の圧迫はもとより、多くの乗客が集中することで、混雑による遅延が発生しています。車両の増備、長編成化、新路線の建設などハード面の強化により大幅な改善を図ることができますが、すでに容量の限界まで運行している場合や、構造物の制約、費用、期間の面からもこれらの施策をすぐに実現することは難しいです。そこで今回は、通勤ラッシュ回避のために乗客が通勤時間をずらすオフピーク通勤の実施について調査し、混雑緩和につながるかを検証したいと思います。 オフピーク通勤(時差通勤)は、個人の自発的な行動によるものであり、多くの会社・学校の始業時間がほぼ同じであるため鉄道事業者が呼びかけても定着することはありませんでした。2016年に「満員電車ゼロ」を含んだ公約を掲げ当選した小池都知事は、公約の実現のためオフピーク通勤を推進するキャンペーンである「時差Biz」を2017年にスタートしました。このことについて、東京都のサイトには以下の文章があります。 満員電車の混雑緩和は、社会の生産性向上のための重要な課題のひとつです。 東京都では、通勤時間をずらすことによって満員電車の混雑緩和を促進する「時差Biz」を実施中です。 時差Bizの参加に資格や決まりはなく、皆様が一斉に取り組むことにより、大きな効果があることが見込まれます。皆様のご参加、お待ちしております。 サイト内では、個人に対して時差通勤を推奨し、企業に対してフレックスタイム制やテレワークの導入などを推奨しています。参加企業は916社、鉄道事業者が集中取組期間中に臨時列車を運行するなど活動の広がりがみられますが、見込まれる効果は未知数なうえ関連するデータや分析結果も乏しいです。そのため簡単ではありますが、オフピーク通勤の効果の有無や程度を具体的に算出します。 まず、平成29年度の首都圏31区間におけるピーク時混雑率を示します。混雑率は、一定時間内の輸送人員(実際に輸送した乗客の数)を輸送力(車両の定員数の合計)で割ったものであり、最も高い東京メトロ東西線(木場→門前仲町)は199%と定員のほぼ2倍の人を乗せています。唯一100%を下回ったのは、JR東日本中央緩行線(代々木→千駄ヶ谷)で、混雑率は97%でした。 輸送人員と輸送力に注目すると、中央快速線の81,560人を筆頭に輸送人員が60,000人を超える路線が13路線ある一方で、輸送力は最も大きい小田急小田原線でも49,416人と大きな差があります。また、ピーク時の運行本数と編成数をみると、多くの路線で10両もしくはそれ以上の車両を2~3分おきに運行していて、これ以上輸送力を強化することは難しいです。 ここからは、オフピーク通勤の効果を検証するため、2つの仮想シナリオが実現した場合の結果を計算します。 1.時差通勤のみ 平成29年度から新たに追加された調査データを利用します。これは、首都圏36区間のピーク時と前後1時間の混雑率を算出したものです。 路線によってピーク時が違うため6:17~7:17から9:02~10:02まで約4時間にわたる混雑率を時間帯の早い順に並べたものが以下のグラフです。路線ごとのばらつきが大きいですが、3等分すると中心部が最も高くなり、ピークより前、ピークより後の順で混雑率が低下しています。このことは始業時間が決まっている場合、それを守るように通勤・通学する人が多いという説明ができるでしょう。 それぞれの路線についてピーク時と前後1時間の合計3時間の輸送人員と輸送力を算出し、そこからピーク時と前後1時間の3時間混雑率を算出したのが(例:ピーク時が7:30-8:30の場合、6:30-9:30の輸送人員/6:30-9:30の輸送力)、以下のグラフです。 混雑率をみると、すべての路線で国が目標としている180%を下回り大きく混雑が緩和されています。このことから、乗客の均等な利用を促す時差通勤は混雑率の低下につながるでしょう。 2.時差通勤+前後時間帯の増発 ピーク時と前後1時間の輸送人員と輸送力を時間帯ごとに示したのが以下のグラフです。ピーク時を中心に山ができていて、多くの乗客がピーク時に集中していることがわかります。 また、それぞれの路線でピーク時の輸送力を前後1時間においても実現した際のシナリオをもとに3時間混雑率を算出しました。(例:ピーク時が7:30-8:30の場合、6:30-9:30の輸送人員/(7:30-8:30の輸送力)×3)その結果、すべての路線で混雑率が150%を下回り、そのうち7路線は100%を下回りました。 しかし、ピーク時の前後1時間の輸送力を増強するためには列車の増発が必要で、鉄道事業者には新たなコストが発生します。このコストに見合うだけの効果が見込めなければ、事業者にとって列車を増発するインセンティブがありませんが、新倉(2009)によると、 増発による増加コストと混雑緩和による利用者便益を試算した結果、両者はほぼ同額でした。また、有料着席列車を導入することで、料金収入によって増加コストを賄うことが可能であるとし、列車の増発は双方にとってメリットがあると示しています。 首都圏36区間のデータからの計算結果をまとめると、ピーク時1時間の混雑率平均は165%でした。(最混雑区間は東京メトロ東西線木場→門前仲町:199%)また、ピーク時と前後1時間を加えた合計3時間の混雑率平均は143%となりました。(最混雑区間は、JR東日本横須賀線武蔵小杉→西大井:177%)そして、ピーク時の輸送力を前後1時間においても実現した場合には、合計3時間の混雑率平均は113%となることがわかりました。(最混雑区間は、東急田園都市線池尻大橋→渋谷:142%) 混雑と遅延の関係 つぎに、遅延証明書の発行状況に関するデータを利用して混雑との関係を調べます。東京圏(対象路線45路線の路線別)における1ヶ月(平日20日間)当たりの遅延証明書発行日数が記載されていて、平成28年度の1位は中央・総武線各駅停車の19.1日です。遅延証明書発行日数が10日を超えるのは45路線のうち29路線で、遅延の発生が常態化しています。 下の散布図は、先ほど使用した混雑率のデータと遅延証明書発行日数を組み合わせたものです。両者には正の相関がみられ、遅延が頻繁に発生している路線ほど混雑率が高くなっています。 遅延の発生は何によって説明されるかを明らかにするため、「混雑率(%)」「列車本数(本/h)」「営業キロ(km)」「他社乗り入れの有無(0or1)」の4つの変数を用いて回帰分析しました。分析の結果、混雑率のみが有意に正の影響を及ぼしていました。 上記データには遅延原因の記載もあり、大規模な遅延(30分以上の遅延)は、人身事故、車両・施設の故障、自然災害が原因である一方、小規模な遅延(10分未満の遅延)は、乗車時間超過が全体の47%を占め、ドアの再開閉が16%でした。これらは利用者の集中によるもので、オフピーク通勤によって混雑が緩和されれば、遅延の発生も減少することが予想されます。そして遅延が原因となっていた混雑の減少が見込まれます。 結論 結果をまとめると、計算上はオフピーク通勤・通学は混雑率の低下につながりますが、実現するには多くの人々の行動を変えなければなりません。そのためには、企業や学校の始業時間を分散させることや柔軟な勤務体系の導入などが必要です。理想的なのは6時台から9時台までムラのない通勤・通学ですが、数十万人が現在の出社・登校時間を変更することになり、さらなる取り組みの拡大が不可欠だといえるでしょう。また、オフピーク時における列車の増発は大幅な混雑緩和につながりますが、増加するコストの負担が課題であり、追加的な調査が必要です。そして、混雑と遅延については互いに影響し合い、一方が減るともう一方も減るという関係があるので、遅延対策の推進も混雑の緩和に寄与することがわかりました。 以上 SAS Visual Analytics 8.3 を用いて朝ラッシュ時におけるオフピーク通勤の有効性検証と混雑と遅延の関係について分析しました。SAS VAの各種使用法については、こちらのブログのシリーズでご説明しております。併せてご参照ください。 SAS Japanでは、学生がData for Goodを行うコミュニティ「SAS Japan Student Data for Good community」を発足します。目的としては、社会問題へのアプローチを通してData Scienceの流れの経験・スキルの向上、学生間の交流拡大、社会への貢献の達成があります。主な活動はふたつに分けられ、一つは社会課題の解決に向けたデータ分析で、オンラインでの議論や定期的な集まり、作成したレポートの公開、アクション(施策)の提案をします。もう一つは、イベント参加で、データサイエンスに関する講演への参加、データ分析コンペ出場、勉強会をすることを予定しています。これまで大学の講義や自習で学んだスキルの実践・アウトプットの場になるうえ、議論をしながらプロジェクトを進めることができます。(知識・アイデアの共有、その他参加者同士の交流)これは大人数の講義や独学ではできないですし、最終的には社会貢献にもつながります。 興味をお持ちでしたら以下のアドレスまでご連絡ください。みなさんの参加をお待ちしています。 JPNAcademicTeam@sas.com