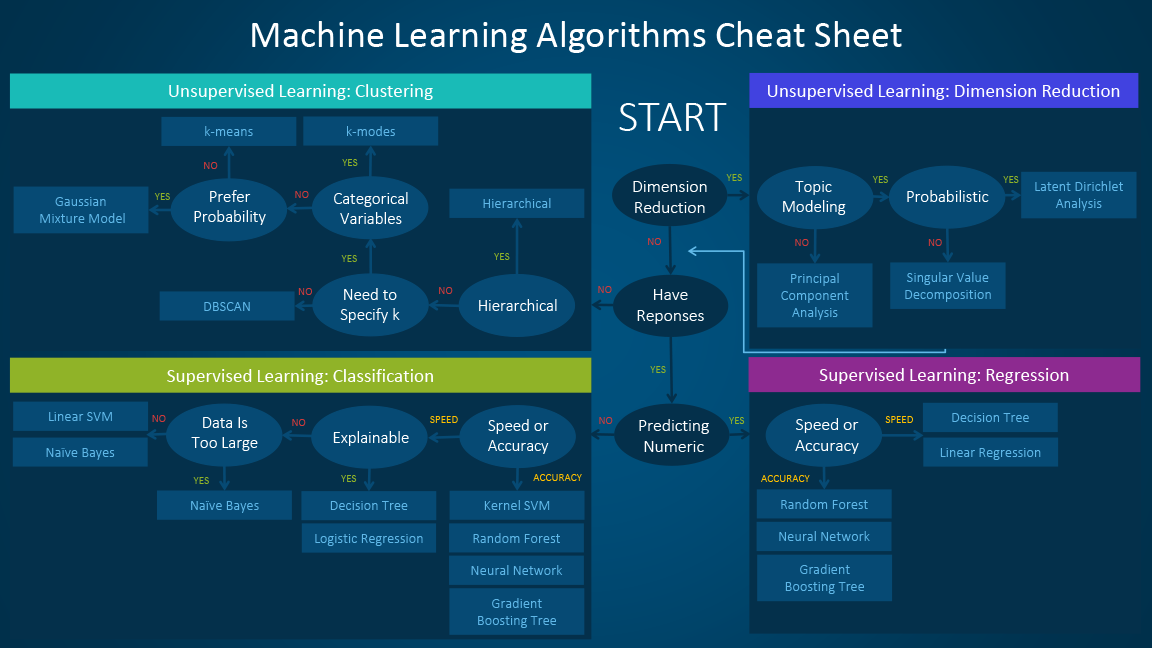
How to handle RSVP ‘maybe’s’

They say nothing in life is certain other than death and taxes, but there something else I’ve found I can count on from experience: sending out invites for a party on social media only to receive a few affirmative responses and a whole slew of “maybe”. I know my friends