This is the first in a series of posts about machine learning concepts, where we'll cover everything from learning styles to new dimensions in machine learning research.
What makes machine learning so successful? The answer lies in the core concept of machine learning: a machine can learn from examples and experience.
Before machine learning, machines were programmed with specific instructions and had no need to learn on their own. A machine (without machine learning) is born knowing exactly what it’s supposed to do and how to do it, like a robot arm on an assembly line. These machines work perfectly for tasks with two conditions:
- The programmer knows exactly what actions the machine needs to take to complete the task.
- The programmer can code the actions needed into the machine’s program.
The problem with this approach, as Erik Brynjolfsson and Andrew McAfee put so well, is that “we humans know more than we can tell.”
Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed. - Arthur Samuel, 1959
People are not especially good at explaining our reasoning, especially for abstract or complex tasks. If you ask someone how they recognize faces or voices of people they know, you are more likely to get a blank stare than a useful answer. The fact is, we do not always understand how our highly evolved brains and bodies work, and we are inept at translating our complex decision-making process to the machines.
To overcome this challenge, machine learning bypasses the process of programming exact solutions to tasks. Instead, we teach machines a method of learning, and let them learn by themselves. The process of machine learning can be summarized in three steps:
- Pick a learning method (i.e., a machine learning algorithm) and teach the machine how to learn using the algorithm,
- Set a goal for the machine, and give it examples (training data) for the problem we want it to solve, and
- Allow the machine to learn (build a model) from the examples using the selected learning method.
Congratulations! Now the machine has learned how to solve the problem through its own learning.
A machine learning example
Take image classification as an example. Assume the goal is to determine whether an image shows a cat or a dog. The examples would be various images of cats and dogs with corresponding labels. By being repeatedly exposed to different examples, the machine will learn what features in the examples best distinguish the two species, and apply the learned knowledge to predict labels of new pictures.
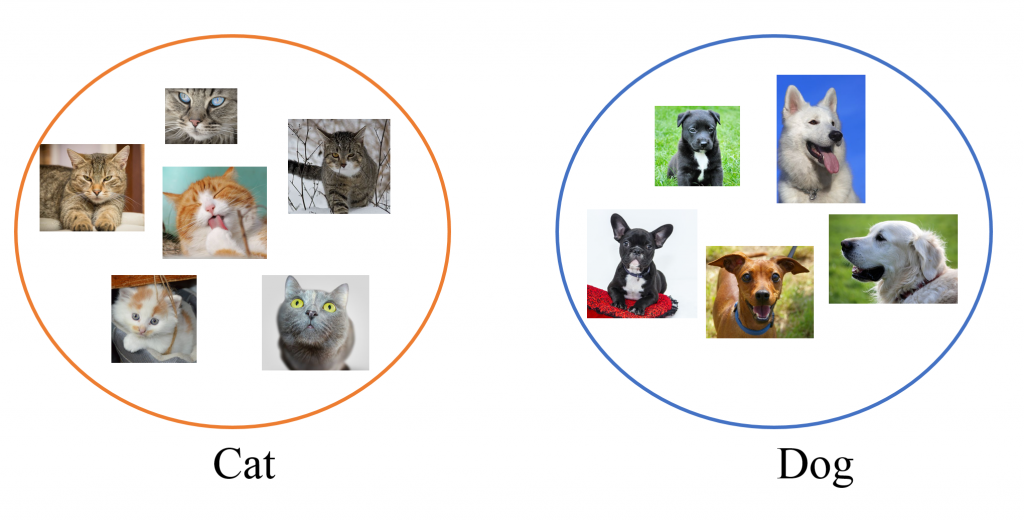
The efficiency of a machine learning model therefore depends on two things: the learning method (machine learning algorithm) used, and the quality of the examples (data) given. The effects of data quality are apparent: a model trained on pictures of real cats and dogs may not be able to correctly classify cartoon animals; if the labels given with the examples are not always correct, the machine may learn the wrong way.
Categories of machine learning
Depending on the nature of the task and types of data available, the best algorithm may vary. The vast majority of machine learning algorithms fall into one of four categories: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
Supervised learning is used when the data come with known labels or outcomes, and is best suited for classification and prediction tasks. The machine will be guided by the different labels and outcome in the available data, and will apply the learned knowledge to predict labels (classification) or values (prediction) of new data. The cat/dog problem above is a supervised learning example, because the data is pre labeled with either cat or dog.
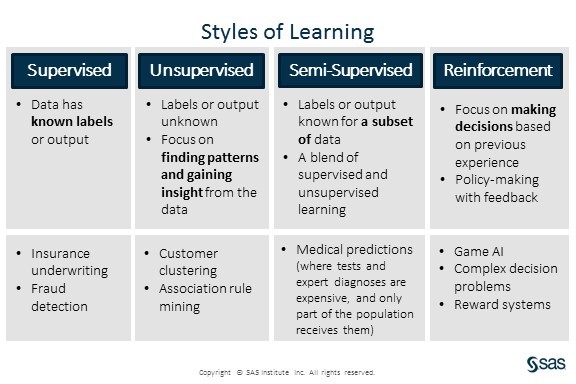
Unsupervised learning does not require labels or outcomes on the data. Instead, unsupervised learning focuses on finding structures and patterns inside the data itself. Finding groups and clusters (clustering), understanding relationships between items (association rule mining), and finding a more compact representation of the data (dimension reduction) are all common uses of unsupervised learning. For example, identifying clusters of drivers with similar driving characteristics and driving habits might allow an insurance company to assign different rates based on those clusters.
Semi-supervised learning is a blend of both the supervised and un-supervised learning styles. It assumes that some of the data given to the machine have labels or outcomes, while some don’t. Often the data without labels are used to grasp a better understanding of the overall data distribution, and then the machine learns to predict/classify the data based on the available labels. Semi-supervised learning is very useful when the labels or outcomes are difficult or expensive to obtain.
Take medical records as an example: tests and diagnoses can be expensive, sometimes patients skip them, and sometimes even positive diagnoses go unreported. According to CDC, only about 7.2 percent of acute hepatitis C cases were reported to CDC in 2014 (2194 reported out of an estimated total of 30,500 cases). In such cases, semi-supervised learning would allow researchers to use both labeled and unlabeled data to build a better prediction model for the disease.
Reinforcement learning is an interactive way of learning, focusing on decision and policy making. In reinforcement learning, the machine takes an action at each step, and receives feedback (a reward) for its action. The goal is to make a policy so that the future actions will maximize rewards. Machines can learn to play games like Chess and Go through reinforcement learning, where they are rewarded or penalized for each move, depending on the game outcome.
Applying machine learning
Machines are, in general, very good learners. When equipped with good data and learning algorithms, the machine can perform many tasks efficiently, matching or sometimes even exceeding human capabilities. However, the usefulness of a machine learning model is also restricted by the learning algorithm used and data available. Thus, we must be careful when designing and applying machine learning to real life.
Check back soon for more posts about machine learning concepts. In upcoming posts, we’ll be talking more about other aspects of machine learning (online vs offline, transfer learning, and unique and effective model structures), existing problems (interpretability, fairness, and accountability) and new directions in research.
To learn more about the opportunities and challenges for machine learning, read the paper, "The Machine Learning Landscape."







1 Comment
Thanks for sharing Xin, this really helps to demistify the topic as it is gaining so much of attention