This is the seventh post in my series of machine best practices. Catch up by reading the first post or the whole series now.
Generalization is the learned model’s ability to fit well to new, unseen data instead of the data it was trained on. Overfitting refers to a model that fits your training data too well (see Figure 1). Underfitting refers to a model that does not fit the training data well and also does not generalize on new data (Figure 2). If your model is overfitted or underfitted, then it simply will not generalize well.
Generalization is a balancing act, where you shift between models with high bias and those with high variance. Algorithms are sexy but using the right evaluation metric is essential to selecting models that will generalize well on new data.
-
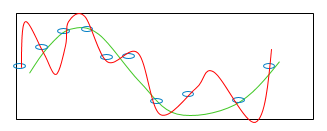
- Figure 1. Overfitting with high variance. The green curve represents the true model. The blue circles represent the training examples. The red curve is the estimated learner.
-
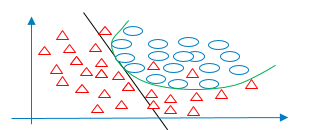
- Figure 2: Underfitting with high bias.
Tips for generalization include:
- If you have high variance error, use more data or subset features.
- If you have high bias error, use more features.
I almost always use a test data set, which is a true hold out data set that is NOT used for modeling but is used to get an unbiased estimate of how well my model generalizes. If I don’t have enough data for partitioning into train, validation and test data sets, I will use k-fold cross validation to evaluate model generalization.
Another way to avoid overfitting is introducing regularization on the parameters of the model. Several regularizations can be selected such as L1, L2 or L21. For a detailed discussion of regularization, refer to the blog post, Preventing Model Over-fitting Using Various Regularizations.
My next post will be about adding features to training data. To read all the posts in this series, click the image below. If there are other tips you want me to cover, or if you have tips of your own to share, leave a comment here.







