This is the second post in my series of machine learning best practices. If you missed it, read the first post, Machine learning best practices: the basics. As we go along, all ten tips will be archived at this machine learning best practices page.
Machine learning commonly requires the use of highly unbalanced data. When detecting fraud or isolating manufacturing defects, for example, the target event is extremely rare – often way below 1 percent. So, even if you’re using a model that’s 99 percent accurate, it might not correctly classify these rare events.
What can you do to find the needles in the haystack?
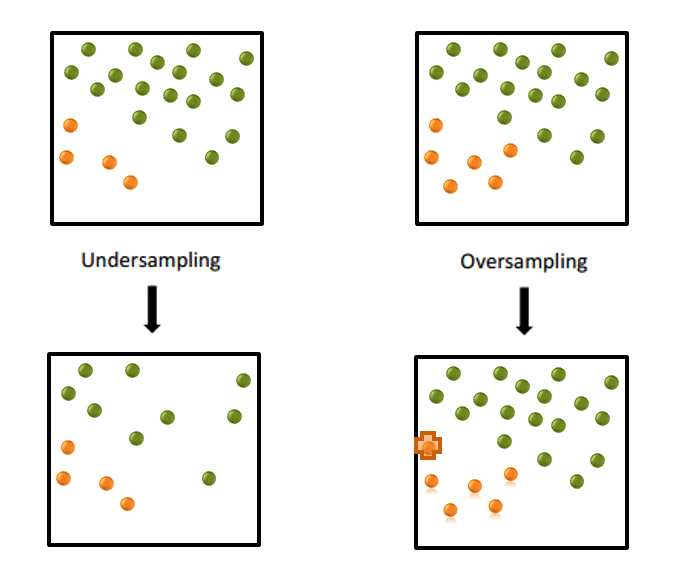
A lot of data scientists frown when they hear the word sampling. I like to use the term focused data selection, where you construct a biased training data set by oversampling or undersampling. As a result, my training data may end up slightly more balanced, often with a 10 percent event level or more (See Figure 1). This higher ratio of events can help the machine learning algorithm learn to better isolate the event signal.
For reference, undersampling removes observations at random to downsize the majority class. Oversampling up-sizes the minority class at random to decrease the level of class disparity.
Another rare event modeling strategy is to use decision processing to place greater weight on correctly classifying the event.
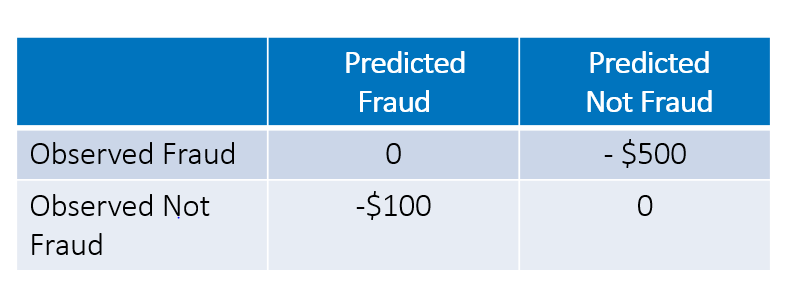
The table above shows the cost associated with each decision outcome. In this scenario, classifying a fraudulent case as not fraudulent has an expected cost of $500. There's also a $100 cost associated with falsely classifying a non-fraudulent case as fraudulent.
Rather than developing a model based on some statistical assessment criterion, here the goal is to select the best model that minimizes total cost. Total cost = False negative X 500 + False Positive X 100. In this strategy, accurately specifying the cost of the two types of misclassification is the key to the success of the algorithm.
My next post will be about combining lots of models. And you can read the whole series by clicking on the image below.
If there are other tips you want me to cover, or if you have tips of your own to share, leave a comment here.








4 Comments
Great series, Wayne! Looking forward to reading all of them and sharing them.
It would be great to hear your perspective on both the algorithms / methodologies as well domain specific feature representation that are required, for instance, in object recognition you can't use the raw image as input, in natural language processing you can't just present the bytestream to the tools, in speech-to-text you can't just put the waveform to the machine. This step of massging the input from raw low level data to higher level conceptual entities that are more meaningful is crucial in all ML applications.
regards, Daymond
Thanks Daymond. Awesome questions. In a subsequent tip I talk about data fusing where the goal is to infuse all kinds of features together in your training data set like images, text and typical structured data. Nothing too elaborate -- trying to keep these tips simple and easy. I also plan to write a whole separate tip series on deep learning after these 10 ML tips run. For brevity, SAS has released image processing now as part of SAS Visual Data Mining and Machine Learning. You can read and store, resize, normalize, filter, apply contours, mutate and so on your images. In November 2017 we will have support for the DICOM format for biomedical images. We have deep network learning now and will extend it in November 2017 with CNNs. You can train your network on a GPU.
To go along with CNNs we are also going to support RNNs which as you know are very good a sequence analyses like speech to text and also time series. Another effort we have underway is delivering natural language interaction to enable the computer to map voice or text commands to the right machine learning library. :For example, What are the most important factors why a customer might churn -- here we run something like a simple decision tree and bring back variable importance measures with some simple narrative annotations. Anyway great question partially answered -- SAS is providing AI toolkits to integrate all kinds of data and deep learning is key. For those of you want to read a bit more bout deep learning at SAS see https://www.sas.com/en_us/insights/analytics/deep-learning.html
Lastly you are such a well known practical data miner. We had the fortune of building out SAS product together. It would be awesome if you could share one or two of your tips if you found time. thanks and would love to see you again.
Pingback: Machine learning best practices: combining lots of models - Subconscious Musings
Wayne this is solid, and I would always recommend factoring in cost before over/under sampling. I'd also say that a 3rd option exists in where you scale back your target problem, which can change the underlying data structure and provide a better training set. Often times the question we're trying to answer with a model might be too broad for integration and production within current environments. This also helps your business partners focus on an easier task to solve and their able to keep-up with the data scientist.