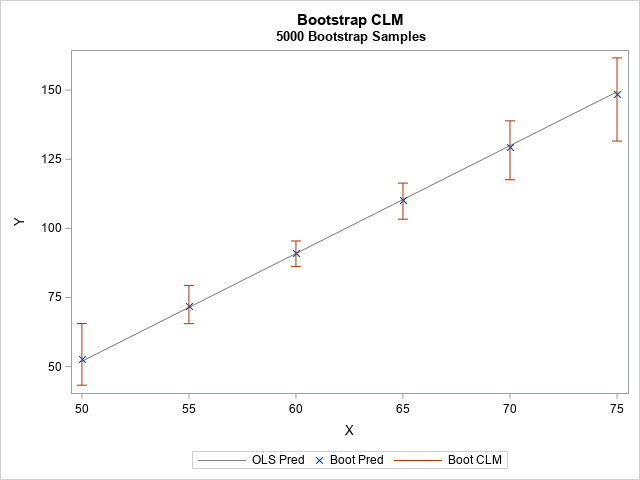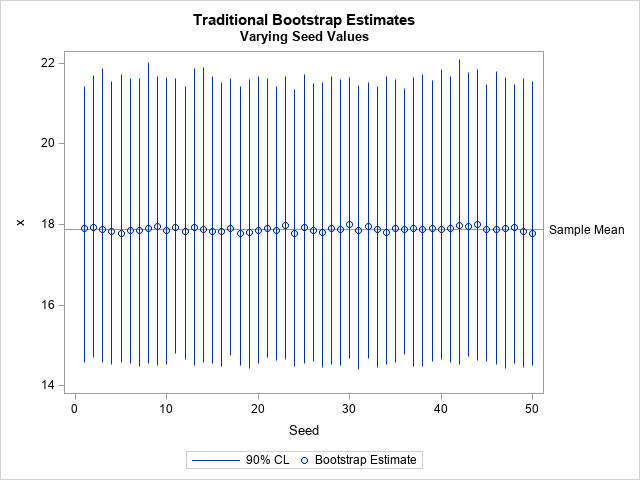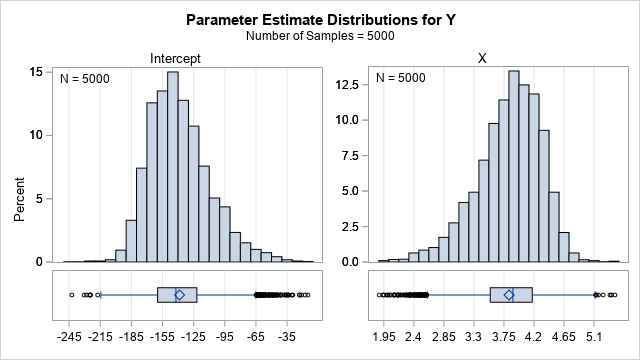
A simple way to bootstrap linear regression models in SAS

I've written many articles about bootstrapping in SAS, including several about bootstrapping in regression models. Many of the articles use a very general bootstrap method that can bootstrap almost any statistic that SAS can compute. The method uses PROC SURVEYSELECT to generate B bootstrap samples from the data, uses the