
This is the second post in a series covering parallel processing in SAS Viya. The first post served as an introduction to parallel processing. It covered parallel processing uses in data science and the SAS Viya products that facilitate it. There are countless opportunities for using parallel processing within data science, and SAS Viya has been designed to take advantage of these opportunities. SAS Viya handles parallelizing tasks automatically where possible. There are also tools available that allow you to further capitalize on SAS Viya’s distributed architecture. One such tool is the scripting language of the CAS server, CASL. This post will discuss parallel processing with CASL.
You will be shown how to perform parallel session processing in CASL through a series of steps. First, the individual CASL functions and statements necessary for handling parallel sessions will be introduced and explained. Example code will also be provided that can be repurposed for your own projects. Next, the performance improvements realized by using parallel sessions will be measured using a Shapley value calculation example program where the total processing time was reduced by 83.36% (6.01 x speedup). This Shapley value calculation example also investigates the relationship between CAS server sizing and performance. Finally, some examples will be given that demonstrate CASL’s flexibility, parallelizing entire CASL programs using parallel runCasl and user-defined action calls.
CASL statements and functions for parallel processing
There are many different language features in CASL used for interacting with parallel sessions. Example 1 below is a simple example meant to demonstrate all the CASL features that will be used in this post. The CASL programs included are meant to be executed in server-side CASL in SAS Viya 4. For more information about this, consult the “How to Run the Examples” section at the end.
/* Standard Action Call */ action table.fetch result = fetch_result status = fetch_status / table = "hmeq"; /* 1. "action" can be omitted */ /* Start a Parallel Session */ parallel_session = create_parallel_session(); /* 1. only available in server-side CASL 2. optional parameter: number-of-workers, default is all workers 3. return value is a string containing the session name for later use */ /* Promote HMEQ Table */ action table.promote result = promote_result status = promote_status / name = "hmeq"; /* 1. tables accessed by parallel sessions must be promoted or loaded into each session individually */ /* Call Action in a Parallel Session, Synchronously */ action table.fetch session = parallel_session result = par_result status = par_status / table = "hmeq"; /* 1. specifying the "session" parameter submits the action to the specified session 2. results/status return just like the action call from above */ /* Call Action in a Parallel Session, Asynchronously */ action table.fetch session = parallel_session async = "FETCH" / table = "hmeq"; /* 1. specifying the "async" parameter submits the action asynchronously 2. result/status is not returned immediately */ /* Wait for Job to Finish */ job = wait_for_next_action(0); /* 1. wait_for_next_action() returns results/status of actions submitted asynchronously to parallel sessions. 2. return is 0 when there are no more jobs 3. dictionary returned contains the following information (not an exhaustive list): session: name of the session the action ran within job: name of the job set with the async= action statement option status: return status of action result: results objects returned by the action log: array of messages produced by the action */ /* End the Parallel Session */ term_parallel_session(parallel_session); /* 1. takes session name as an argument 2. clean up spawned sessions when work is complete */ |
Example 1: Basic steps for parallel processing in CASL
All parallel CASL programs rely on the CASL statements/functions used in Example 1. It’s up to you to start and stop any parallel sessions used as well as handle the action results that come from those sessions. Please consult the CASL documentation for more information regarding these features, as they will be used heavily throughout the remaining examples.
Training two models in parallel
Model training is a common task within data science. Often, many models of different types are trained and then assembled together. If these models do not depend on one another, they can be trained simultaneously. Example 2 uses the workflow from Example 1 to train two separate models at the same time.
/* Dictionary for storing results */ results = {}; /* Tree Parameters */ tree_parameters = { table = "hmeq", target="BAD", inputs={ "CLAGE", "CLNO", "DEBTINC", "LOAN", "MORTDUE", "VALUE","YOJ", "DELINQ", "DEROG", "JOB", "NINQ" }, nominals={"DELINQ", "DEROG", "JOB", "NINQ", "BAD"} }; /* Create Sessions, store names in an array */ sessions = {}; do i = 1 to 2; sessions = sessions + {create_parallel_session()}; end; /* Train Forest Model in session 1 */ decisionTree.forestTrain session = sessions[1] async = "FOREST" / tree_parameters; /* Train Gradboost Model in session 2 */ decisionTree.gbtreeTrain session = sessions[2] async = "GBTREE" / tree_parameters; /* Wait for Actions to Complete */ job = wait_for_next_action(0); do while(job); results[job["job"]] = job["result"]; /* Store Results in Dictionary */ job = wait_for_next_action(0); end; /* End Sessions */ do session over sessions; term_parallel_session(session); end; /* Inspect Results */ describe results; print results; |
Example 2: Training two models in parallel
Training two models at once is faster than training them sequentially unless all the CAS server’s resources are being used. Consider the performance section following Example 4 below for an analysis of speed-ups gained using parallel sessions.
Function for handling parallel action submissions
Most CASL scripts that use parallel sessions resemble the program in Example 2. They use the same language elements and a similar pattern of spawning/terminating sessions. That said, it is feasible to copy the code from Example 2 and modify it to fit your needs. But as the tasks being parallelized become more complicated, and the number of actions that need to be submitted in parallel grows, strain can be placed on the CAS server and the programmer. Below are a few of the things that you must consider when writing such a program:
How many sessions should you use?
There is an upper limit to how many actions a CAS server can process at once before you stop seeing performance improvements. Additionally, starting sessions takes time. Combining these two facts, it’s possible for the total duration of a series of tasks to increase after the CAS server’s computing power has been saturated. For a given task there exists an optimal number of parallel sessions to use to maximize performance. More details regarding selecting how many sessions to use are provided in Example 4.
To queue or not to queue?
Actions can be queued for processing within sessions. More than one action can be submitted to the same session at the same time, where they’ll be run sequentially. When actions are submitted this way, the CAS server does not need to wait on the client for further instructions when it completes an action. It can just start processing the next action in the queue.
When determining whether to use queueing, the main thing to consider is the duration of a single action. If you're submitting multiple fast actions, queueing is a good idea because the overhead of waiting on the client for the next action is high. If you're submitting a few large actions, the overhead is not as cumbersome, so queueing is unnecessary. Using queues when they are not necessary can make your program distribute work sub-optimally, leaving some sessions with no remaining work while other sessions still have a long action queue.
Example function for handling parallel action submissions
If you use parallel sessions in many different projects, you’ll find yourself writing the same CASL code repeatedly to tackle common problems. Problems like handling parallel sessions and action queues. Luckily, most of these steps can be done the same way for many different tasks. In Example 3 below, several functions are provided for handling parallel sessions in a common, reusable way.
function pop(arr); /* pop() returns the first element from an array and removes that element from the array. Arrays are passed by reference, so editing the `arr` argument will edit the array directly Arguments: 1. arr (List) - list-like from which to pop value */ /* Return Index */ ret = arr[1]; /* Modify Array */ if dim(arr) = 1 then arr = {}; else arr = arr[2:dim(arr)]; return ret; end; function callAction(action, parameters, async_session, async_tag); /* callAction() calls an action with the given parameters. If async_tag is set to a string, the action is submitted asynchronously. Arguments: 1. action (String), required - Name of action to call, including action set. i.e. "table.fetch" 2. parameters (Dictionary), required - Dictionary of action parameters. 3. async_session (String), optional - session for executing action. 4. async_tag (String), optional - Tag for submitted job */ /* Submit Action Asychronously */ /* Default value function argument is 0, an int64. isString() checks if the argument was set to a string */ if isString(async_tag) then do; execute(action || " session = async_session async = async_tag / parameters;"); /* Submit Action Synchronously */ end; else do; if !isString(async_session) then async_session = "server"; execute(action || " session = async_session result = CA_RES status = CA_ST / parameters;"); /* Return Action Results and Status */ return( { result = CA_RES, status = CA_ST } ); end; end; function runParallelActions(action_array, num_sessions, num_workers, init_string, batch_size); /* runParallelActions() executes an array of action calls in parallel and returns their results. If num_sessions = 1, actions are executed sequentially. Arguments: 1. action_array (Array) - array of action specifications to run. An action specification is a two-element array where the first element is the action name and the second element is the action parameters 2. num_sessions (Int64) - number of sessions to use for action submission 3. num_workers (Int64) - number of workers to use for each session. 0 means all workers 4. init_string (String) - CASL code to run at the start of a session 5. batch_size (Int64) - number of actions to queue for a single session. 0 means queue all actions immediately. */ /* Action Call Bookkeeping */ action_results = {}; submitted_actions = {}; /* Process Batch Size */ max_batch = ceil(dim(action_array) / num_sessions); if batch_size <= 0 or batch_size > max_batch then batch_size = max_batch; /* Start Parallel Sessions */ sessions = {}; do i = 1 to num_sessions; sessions[i] = create_parallel_session(num_workers); submitted_actions[sessions[i]] = 0; /* Run Start-Up Script */ if isString(init_string) then callAction("sccasl.runCASL",{code = init_string},sessions[i]); end; available_sessions = sessions; /* Big Loop */ still_working = True; next_action = 1; do while(still_working); /* Default to Exiting Loop */ still_working = False; /* Submit Remaining Actions */ if next_action <= dim(action_array) and dim(available_sessions) > 0 then do; /* More Actions to submit, continue working */ still_working = True; /* Grab Session */ session = pop(available_sessions); /* Submit a Batch of Actions */ do action_index = 1 to batch_size; if next_action <= dim(action_array) then do; /* Grab Action */ action = action_array[next_action]; next_action = next_action + 1; /* Submit Action */ callAction(action[1], action[2], session, (String) (next_action - 1)); submitted_actions[session] = submitted_actions[session] + 1; end; end; /* Return to top of loop, prioritizing action submission */ continue; end; /* Gather Submitted Actions */ job = wait_for_next_action(sessions); if job then do; still_working = True; /* Store Action Results */ session = job['session']; action_number = (int64) job['job']; action_results[action_number] = job; /* Re-Use Session */ submitted_actions[session] = submitted_actions[session] - 1; if submitted_actions[session] <= 0 then available_sessions = available_sessions + {session}; end; /* Catch Unreturned Actions */ do session, count over submitted_actions; if count > 0 then still_working = True; end; end; /* End Parallel Sessions */ do session over sessions; term_parallel_session(session); end; return action_results; end; |
Example 3: Functions to assist parallel action execution
The main function to analyze in Example 3 is runParallelActions(). This function accepts an array of action calls. Then it evenly distributes those actions to the specified number of parallel sessions. Finally, it returns the results from those calls in the same order that the actions were submitted. Instead of worrying about starting/stopping sessions and handling wait_for_next_action(), you can create an array of action calls and use runParallelActions() to handle the parallel session work. In addition to specifying the number of sessions to use, you can specify the number of workers to use in each session, CASL code to run when each session starts (useful for loading tables/action sets), and the number of actions to queue into each session at once. The remaining Examples 4-6 make heavy use of runParallelActions() to handle parallel action submission.
Disclaimer
The runParallelActions() function and the parallel session logic contained within it are powerful tools for data scientists. But it is important to remember that CAS resources are often shared by many people within your organization. Submitting too much work to a CAS server at once puts the machine at risk of running out of memory for sufficiently large jobs. Or it may simply use all the available processing power, preventing other users from using the machine. Please be a good steward of shared resources when using runParallelActions() function and other CASL functionality mentioned here.
Parallel Shapley value estimation
The Shapley values are a popular model-agnostic interpretability technique. While very powerful, Shapley values are notoriously expensive to compute. It’s not uncommon for data scientists to calculate Shapley values for many observations but doing so sequentially can take a prohibitive amount of time. Luckily, the Shapley values for two different observations are independent of one another, so they can be calculated in parallel. The parallelShapTest() function in Example 4 calculates the Shapley values for a gradient boosting tree model on several observations from the HMEQ data set in parallel.
function parallelShapTest(num_obs,num_sessions,num_workers); /* Note: This version of the hmeq dataset has a unique column added, _dmIndex_ */ /* _dmIndex_ is used for brevity */ /* Dataset Information */ inputs = {"CLAGE", "CLNO", "DEBTINC", "LOAN", "MORTDUE", "VALUE","YOJ", "DELINQ", "DEROG", "JOB", "NINQ"}; nominals = {"DELINQ", "DEROG", "JOB", "NINQ"}; /* Train a Gradient Boosting Model */ decisionTree.gbtreeTrain result = gb_results status = gb_status / table = "hmeq", target = "BAD", inputs = inputs, nominals = nominals + {"BAD"}, name = "hmeq_gradboost", promote = True /* Make available to subsessions */ } ; /* explainModel.shapleyExplainer parameters */ shap_parms = { table = "hmeq", inputs = inputs, nominals = nominal, predictedTarget = "P_BAD1", modelTable = "hmeq_gradboost" }; /* Shapley Call For Each Observation */ shapley_calls = {}; do i = 1 to num_obs; shap_parm_copy = shap_parms; shap_parm_copy["query"] = { name = "hmeq", where = "_dmIndex_ = " || (String) i }; shapley_calls[i] = {"explainModel.shapleyExplainer",shap_parm_copy}; end; /* Run all Shapley Calls */ start_time = datetime(); shapley_results = runParallelActions(shapley_calls,num_sessions,num_workers); /* ... Process Shapley Values ... */ return datetime() - start_time; end; |
Example 4: CASL function for parallel Shapley calculation
In the next section, the parallelShapTest() function will be called with many different parameter combinations to measure the performance impact of parallel sessions.
Session / Worker count tests
The parallelShapTest() function accepts three parameters: the number of observations for which to calculate Shapley values, the number of sessions to use, and the number of workers to use in each session. The table below contains relative timing information for different session number/worker count combinations. The number of observations was held constant at 100, and the CAS server used had five workers available.
Relative shapleyValueTest() Speed
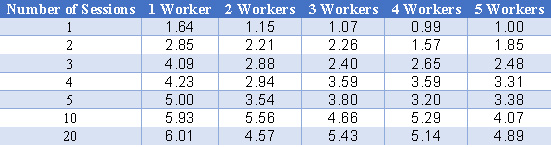
The numbers in the table represent how much faster the shapleyValueTest() call is than the base case for that session number/worker count combination. The base case used for the relative comparison was the single-session, five-worker case because that case represents the default speed the work would take if the actions were submitted sequentially. Only relative performance values are shown here because the absolute duration will vary between SAS Viya installations. As an example, using 20 sessions that each use a single worker is approximately 6.01x faster than running the actions sequentially.
There are two trends to notice. First, using fewer workers per session speeds up the performance significantly. Communicating information between machines can take a lot of time. This communication overhead can sometimes overwhelm the performance gains of using more than one processor. Second, using multiple sessions speeds up performance, but only up to a certain point. There is very little difference in the performance of the 10-session cases and the 20-session cases. After a point, the CAS server will be using all its resources processing actions, and submitting additional actions will produce diminishing returns.
Parallelizing complex flows with runCasl
Not all data science tasks can be done in a single action call. Evaluating a model’s performance on validation data, for instance, takes at least three actions calls: one call to train the model, one call to score the model, and a third call to assess the model. If many of these models need to be trained and assessed, parallelizing those action calls can be complicated because some of them depend on one another. Luckily, we can take advantage of the runCasl action to stitch together a string of action calls. Then we parallelize the execution of the entire CASL program, such as in Example 5 below.
/* Note: This version of the hmeq dataset has a partition column added, _partInd_ */ /* CASL Code for Assessing a Forest Model */ source assess_code; /* Train Forest Model */ decisionTree.forestTrain result = forest_result status = forest_status / table = { name = "hmeq", where = "_partInd_ = 1" }, target = "BAD", inputs = { "CLAGE", "CLNO", "DEBTINC", "LOAN", "MORTDUE", "VALUE","YOJ", "DELINQ", "DEROG", "JOB", "NINQ" }, nominals = {"DELINQ", "DEROG", "JOB", "NINQ", "BAD"}, savestate = "hmeq_forest_astore", encodeName = True, nTree = n_trees ; /* Score Forest Model */ astore.score result = astore_result status = astore_status / table = "hmeq", rstore = "hmeq_forest_astore", casout = "hmeq_astore_scored", copyVars = {"BAD","_partInd_"} ; /* Assess Forest Model */ percentile.assess result = assess_result status = assess_status / table = { name = "hmeq_astore_scored", where = "_partInd_ = 0" }, response = "BAD", inputs = "P_BAD1", event = "1", pVar = {"P_BAD0"}, pEvent = {"0"} ; /* Return Log Loss */ send_response( { MCLL = assess_result["FitStat"][1,"MCLL"] } ); endsource; /* Create Forest Assess Calls */ casl_calls = {}; do n_trees over {50,100,150,200,250,500,1000,2000,5000}; casl_calls = casl_calls + { { "sccasl.runCasl", { code = assess_code, vars = {n_trees = n_trees} } } }; end; /* Run all CASL Calls */ casl_results = runParallelActions(casl_calls,dim(casl_calls),1); do action_index, result over casl_results; print "nTrees: " casl_calls[action_index][2]["vars"]["n_trees"]; print "MCLL: " result["result"]["MCLL"]; print " "; end; |
Example 5: Parallelizing a CASL program with runCasl
In Example 5, a CASL program is written using a source block. This CASL program trains a forest model on a training partition and evaluates its log loss on a validation partition. The CASL program is then submitted multiple times for many different numbers of trees (a forest parameter). And these CASL calls themselves are evaluated in parallel. Effectively any task that can be performed in CASL can be written and executed this way to maximize performance.
Parallelizing complex flows with user-defined action sets
Example 6 is functionally the same as the example above, training and evaluating forest models with different parameters. Instead of using the runCasl action, however, a user-defined action is used. User-defined actions are a powerful way for users to package and share their CASL code with other users. In this example, a user-defined action is defined that performs the training and evaluation task. This action is then submitted many times for different forest parameters.
/* CASL Code for Assessing a Forest Model */ source assess_code; /* Train Forest Model */ decisionTree.forestTrain result = forest_result status = forest_status / table = { name = "hmeq", where = "_partInd_ = 1" }, target = "BAD", inputs = { "CLAGE", "CLNO", "DEBTINC", "LOAN", "MORTDUE", "VALUE","YOJ", "DELINQ", "DEROG", "JOB", "NINQ" }, nominals = {"DELINQ", "DEROG", "JOB", "NINQ", "BAD"}, savestate = "hmeq_forest_astore", encodeName = True, nTree = n_trees ; /* Score Forest Model */ astore.score result = astore_result status = astore_status / table = "hmeq", rstore = "hmeq_forest_astore", casout = "hmeq_astore_scored", copyVars = {"BAD","_partInd_"} ; /* Assess Forest Model */ percentile.assess result = assess_result status = assess_status / table = { name = "hmeq_astore_scored", where = "_partInd_ = 0" }, response = "BAD", inputs = "P_BAD1", event = "1", pVar = {"P_BAD0"}, pEvent = {"0"} ; /* Return Log Loss */ send_response( { MCLL = assess_result["FitStat"][1,"MCLL"] } ); endsource; /* Create Actionset */ builtins.defineActionset / name = "forestAssess", actions = { { name = "assessForest", parms = { { name = "n_trees", type = "int64" } }, definition = assess_code } } ; /* Save Actionset To Table */ builtins.actionsetToTable / actionset = "forestAssess", casout = { name = "forestAssess", promote = True } ; /* Create Initialization String */ source load_string; builtins.actionsetFromTable / table = "forestAssess", name = "forestAssess" ; endsource; /* Create Forest Assess Calls */ casl_calls = {}; do n_trees over {50,100,150,200,250,500,1000,2000,5000}; casl_calls = casl_calls + { { "forestAssess.assessForest", { n_trees = n_trees } } }; end; /* Run all CASL Calls */ casl_results = runParallelActions(casl_calls,dim(casl_calls),1,load_string); do action_index, result over casl_results; print "nTrees: " casl_calls[action_index][2]["n_trees"]; print "MCLL: " result["result"]["MCLL"]; print " "; end; |
Example 6: Parallelizing a CASL program with a user-defined action
Example 6 is almost identical to the runCasl example. There are just a few extra action calls for creating and loading the user-defined action set. User-defined action sets and parallel sessions can be combined to great effect.
Parallel processing in CASL conclusion
This blog series is all about how you can take advantage of SAS Viya and its distributed architecture to run individual data science tasks in parallel. As shown in the previous post, many data science tasks benefit from a parallel implementation. CASL gives you control over exactly what processes are being run in parallel. It can have a significant impact on the performance of common tasks. This was demonstrated in the Shapley value calculations in Example 4. CASL also offers flexibility, allowing users to define and execute entire CASL programs in parallel using tools such as runCasl and user-defined action sets. I hope that the examples in this post have inspired you to utilize parallel CASL sessions in your next data science project.
How to run the examples
There are two ways to use CASL in SAS Viya: client-side CASL statements submitted in PROC CAS and server-side CASL statements submitted using the runCasl action. The CASL language features are different between the runCasl action and PROC CAS. This post includes examples that are meant to be submitted to the CAS server through the runCasl action in a SAS Viya 4 environment. The runCasl action can be submitted using any CAS client. Here’s an example of submitting a CASL program to the CAS server using runCasl from within PROC CAS.
proc cas; source casl_code; /* Code Examples Start Here */ print "Hello from the CAS Server!"; /* Code Examples End Here */ endsource; sccasl.runCASL / code = casl_code; quit; |
It would be overly verbose to include the PROC CAS and QUIT statements for every example in this post. So these statements were omitted, leaving only the server-side CASL code. You can copy and paste the example programs into a source block to run them.
Some of the examples will themselves use source statements, which cannot be nested. For these examples, you can save the server-side CASL program to an external file and load it into CASL using the readPath() function.
proc cas; /* Example Code Stored in External File */ casl_code = readPath("\hello.sas"); sccasl.runCASL / code = casl_code; quit; |
The server-side CASL code being submitted to the CAS server has been saved into a different file and is read in as a string. A similar method can be used in any programming language that has access to the file system and can establish a connection to the CAS server.
LEARN MORE | SAS Viya





2 Comments
Does all this work in SAS Viya 3.5? The article saysThe CASL programs included are meant to be executed in server-side CASL in SAS Viya 4 but I wasn't sure if that meant it wasn't available in 3.5.
Hi Ricky, what would be the big changes to run the examples on viya 3.5?