In this article, we summarize our SAS research paper on the application of reinforcement learning to monitor traffic control signals which was recently accepted to the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada. This annual conference is hosted by the Neural Information Processing Systems Foundation, a non-profit corporation that promotes the exchange of ideas in neural information processing systems across multiple disciplines.
Traffic Signal Control Problem (TSCP)

With the emergence of urbanization and the increase in household car ownership, traffic congestion has been one of the major challenges in many highly-populated cities. Traffic congestion can be mitigated by road expansion/correction, sophisticated road allowance rules, or improved traffic signal controlling. Although either of these solutions could decrease travel times and fuel costs, optimizing the traffic signals is more convenient due to limited funding resources and the opportunity of finding more effective strategies. Here we introduce a new framework for learning a general traffic control policy that can be deployed in an intersection of interest and ease its traffic flow.
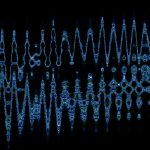
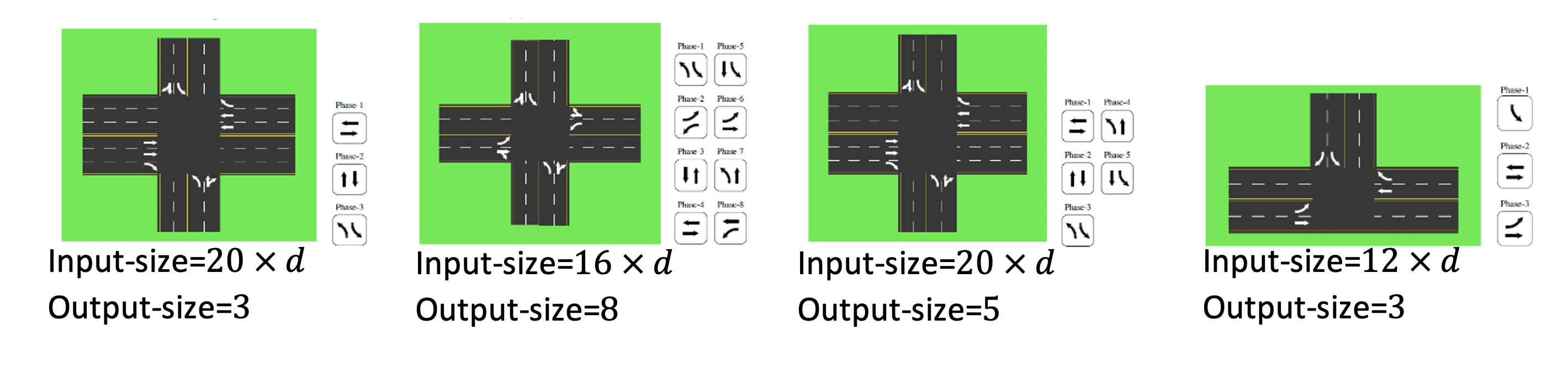
Let’s first define the TSCP. Consider the intersection in the following figure. There are some lanes entering and some leaving the intersection, shown with \(l_1^{in}, \dots, l_6^{out}\) and \(l_1^{out}, \dots, l_6^{out}\), respectively. Also, six sets v1 ... v6 with each showing the involved traffic movements in each lane. A phase is defined as a set of non-conflicting traffic movements, which become red or green together. The decision is which phase becomes green at what time, and the objective is to minimize the average travel time (ATT) of all vehicles in the long-term.
Motivations
There are two main approaches for controlling signalized intersections, namely conventional and adaptive methods. In the former, customarily rule-based fixed cycles and phase times are determined a priori and offline based on historical measurements as well as some assumptions about the underlying problem structure. However, since traffic behavior is dynamically changing, that makes most conventional methods highly inefficient. In adaptive methods, decisions are made based on the current state of the intersection. In this category, methods like Self-organizing Traffic Light Control (SOTL) and MaxPressure brought considerable improvements in traffic signal control; nonetheless, they are short-sighted and do not consider the long-term effects of the decisions on the traffic. Besides, these methods do not use the feedback from previous actions toward making more efficient decisions.
Reinforcement learning
Consider an environment and an agent, interacting with each other in several time-steps. At each time-step t, the agent observes the state of the system, st, takes an action, at, and passes it to the environment, and in response receives reward rt and the new state of the system, s(t+1). The goal is to maximize the sum of rewards in a long time, i.e., \(\sum_{t=0}^T \gamma^t r_t\) where T is an unknown value and 0<γ<1 is a discounting factor. The agent chooses the action based on a policy π which is a mapping function from state to actions. This iterative process is a general definition for Markov Decision Process (MDP). Reinforcement learning (RL) is an area of deep learning that deals with sequential decision-making problems which can be modeled as an MDP, and its goal is to train the agent to achieve the optimal policy.
RL for TSCP
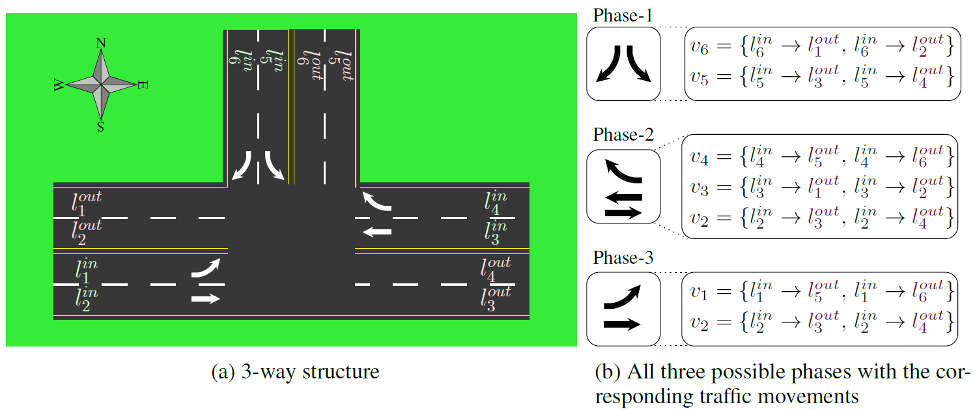
Several reinforcement learning (RL) models are proposed to address these shortcomings. Although, they need to train a new policy for any new intersection or new traffic pattern. For example, if a policy π is trained for an intersection with 12 lanes, it cannot be used in an intersection with 13 lanes. Similarly, if the number of phases is different between two intersections, even if the number of lanes is the same, the policy of one does not work for the other one.
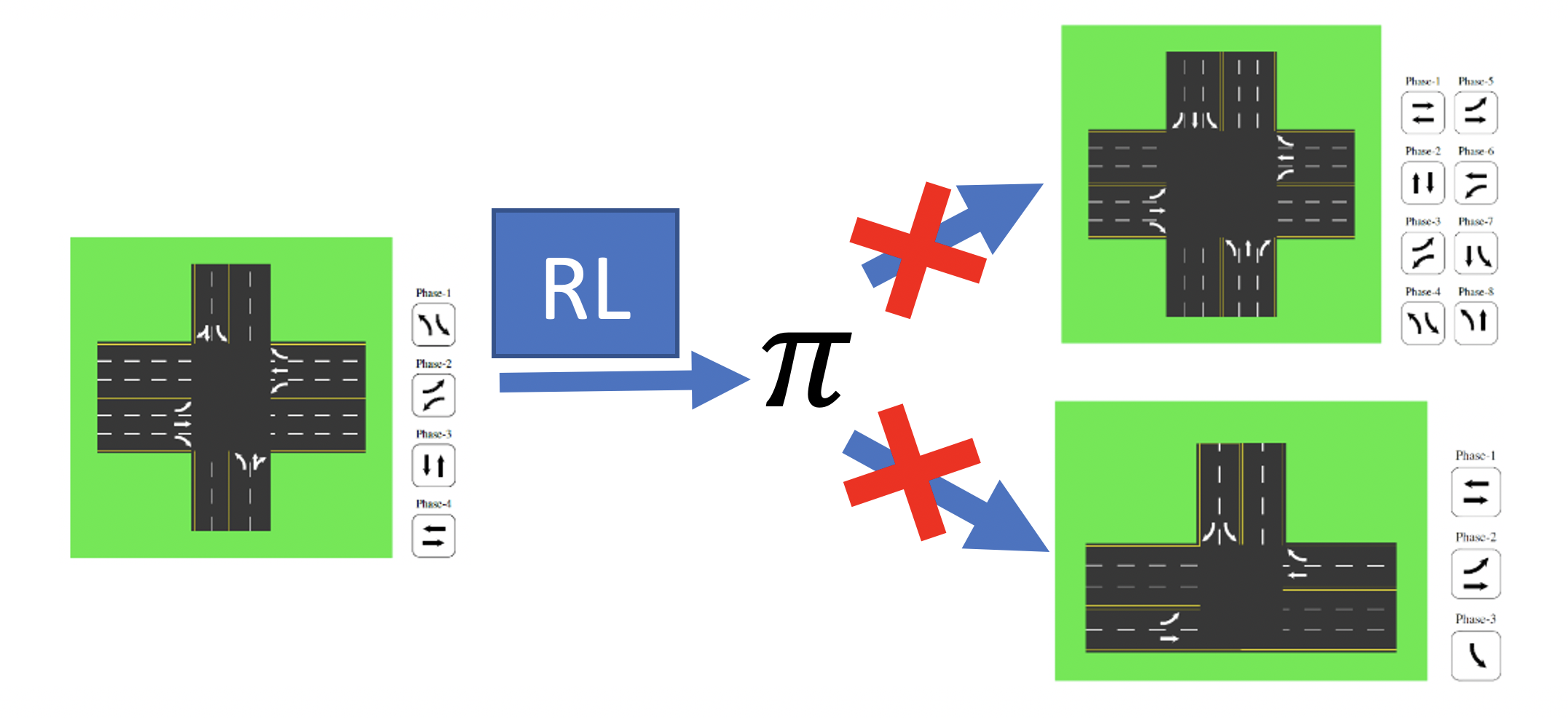
Similarly, the policy which is trained for the noon traffic-peek does not work for other times during the day.
Why existing RL methods are not universal?
The main reason is that there are a different number of inputs and outputs among different intersections. So, a trained model for one intersection does not work for another one.
AttendLight
We propose AttendLight to train a single universal model to use it for any intersection with any number of roads, lanes, phases, and traffic flow. To achieve such functionality, we use two attention models: (i) State-Attention, which handles different numbers of roads/lanes by extracting meaningful phase representations \(z_p^t\) for every phase p. (ii) Action-Attention, which decides for the next phase in an intersection with any number of phases. So, AttendLight does not need to be trained for new intersection and traffic data.
Empirical results
Experiments Setup
We explored 11 intersection topologies, with real-world traffic data from Atlanta and Hangzhou, and synthetic traffic-data with different congestion rates. This results in 112 intersection instances. We followed two training regimes: (i) Single-env regime in which we train and test on single intersections, and the goal is to compare the performance of AttendLight vs the current state of art algorithms. (ii) Multi-env regime, where the goal is to train a single universal policy that works for any new intersection and traffic data with no re-training. For the multi-env regime, we train on 42 training instances and test on 70 unseen instances.
Single-env regime results
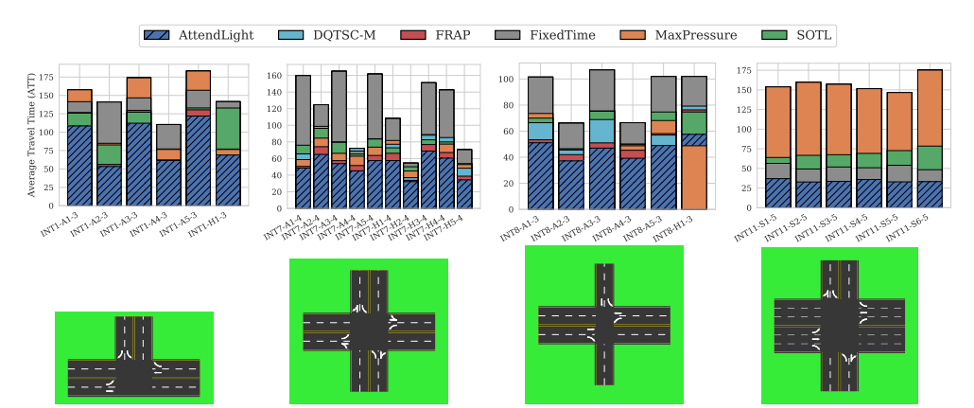
AttendLight achieves the best result on 107 cases out of 112 (96% of cases). Also, on average of 112 cases, AttendLight yields an improvement of 46%, 39%, 34%, 16%, 9% over FixedTime, MaxPressure, SOTL, DQTSC-M, and FRAP, respectively. The following figure shows the comparison of results on four intersections.
Multi-env regime results
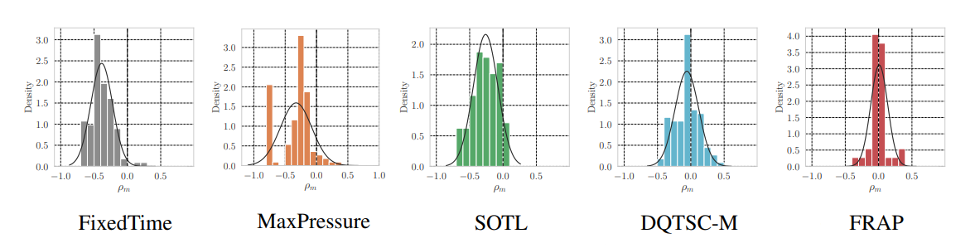
There is no RL algorithm in the literature with the same capability, so we compare AttendLight multi-env regime with single-env policies. In average of 112 cases, AttendLight yields improvement of 39%, 32%, 26%, 5%, and -3% over FixedTime, MaxPressure, SOTL, DQTSC-M, and FRAP, respectively. Note that here we compare the single policies obtained by AttendLight model which is trained on 42 intersection instances and tested on 70 testing intersection instances, though in SOTL, DQTSC-M, and FRAP there are 112 (were applicable) optimized policy, one for each intersection. \(\rho_m = \frac{a_m - b_m}{\max(a_m, b_m)}\) Also, tam where am and bm are the ATT of AttendLight and the baseline method. As you can see, in most baselines, the distribution is leaned toward the negative side which shows the superiority of the AttendLight.
Summary
With AttendLight, we train a single policy to use for any new intersection with any new configuration and traffic-data. In addition, we can use this framework for Assemble-to-Order Systems, Dynamic Matching Problem, and Wireless Resource Allocation with no or small modifications. See more details on the paper!