An urban legend says that a data science task is mainly finished after the development of models. The truth is that a much more important phase follows, often tougher than model development: managing and governing these ready-to-use models to keep your data science project relevant for the long haul.
This post details the process of bringing a data science project to life and keeping it alive. If you're a visual learner, you might prefer tuning into my Open Data Science Conference presentation, First Aid Kit for Data Science: Keeping Machine Learning Alive. In just over 24 minutes, I cover the machine-learning lifecycle, which includes finding the right data, preparing and exploring it and building, registering and reassigning models. I use a fraud detection project as an example.
Model management: more than deployment
Model deployment is not only about putting models into production, it's also about the management of the models, the monitoring of the models and taking next-best actions based on their performance.
And yet this part of the data science process is perceived as boring by many data scientists. How can we help? Well, SAS Model Manager helps to take the burden out of model management and governance.
Do you need to develop your models in SAS to use SAS Model Manager? No, whether the preference is for SAS, R or Python or a mixture, this approach brings everything under a single umbrella.
How to bring AI models alive
Data science goes much further than the development of models. A data science project is only successful when the developed models are creating value for the business. And this is only accomplished when the models are operationalized and supporting the decision-making process of the business end users.
SAS Model Manager is a library of models that are approved by the data scientist after the development process, and ready to run in a production environment. It is a store of models we can pick and choose from, and where every model runs with a guaranteed quality, regardless the model’s source language. With just one click we can bring any model to the desired production environment.
Why you should create multiple models for the same task
In general, it is a good practice to develop multiple AI models that support the same task. The reason for this is simple: if one model fails or the performance of that model degrades drastically, there is always another model that can take over. In the Machine Learning world, this approach is often referred to as the Champion-Challenger approach, where the Champion model is the model that currently has the best performance for the AI task at hand. The Champion model is the model that typically runs in production and is continuously challenged by the so-called Challenger models. As soon as the Champion model fails or one of the Challenger models defeats the Champion model, the current Champion model can be quickly replaced, and the continuity of the AI system can be guaranteed.
One of the challenges many data scientists face is that it is often very hard to compare data science models originating from different languages. So how do we choose our current Champion model? Working with SAS Model Manager, it’s possible to incorporate models created in any open source language so that there is the necessary history, governance and the ability to compare the various models even if they originate from different languages.
Why you should track model performance
In today’s world everything is volatile and constantly changing, and that is no different in data science. A perfect model today is not necessarily the perfect model tomorrow. It is therefore of utmost importance to keep track of the models’ performance over time.
This is basically what Machine Learning is striving for. In the term Machine Learning, we have the word ‘Learning’. Learning is not a one-time exercise, but a continuous improvement process. Making sure that your models are reflecting the latest changes in the data is becoming more and more an essential part of data science. Does that mean that your job as a data scientist is mostly occupied with updating your models and not with the cool development phase? Of course not, SAS Model Manager allows a data scientist to trigger automatically the retraining process at a predefined time stamp or at a predefined event (e.g., performance of the models does not satisfy the requirements anymore), guaranteeing that your model always is built with the latest data available. The governance of AI projects implicitly requires follow-up of AI projects on three levels:
Input: Does the current data still correspond to data used to train the model?
AI models are trained using data. And data changes over time. A significant or a permanent change in the data might result in an AI performance degradation. It is therefore extremely important to track changes in the data.
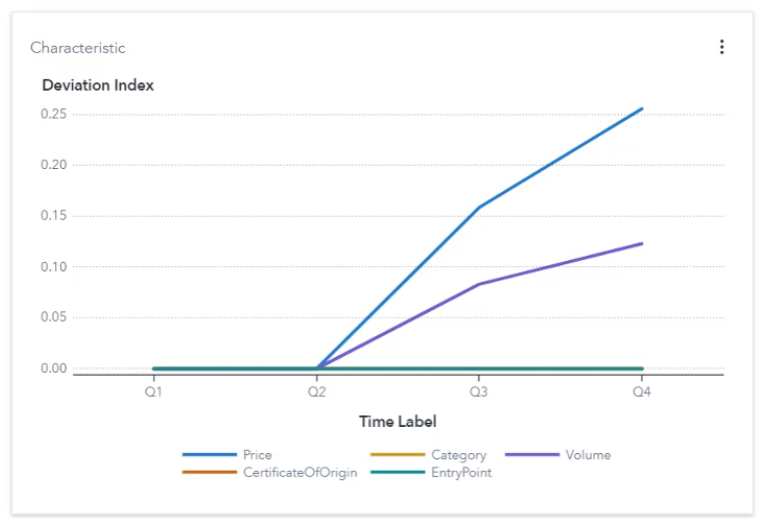
Model performance: Does current model performance still fit the range expected?
A typical pattern when measuring the performance of AI models over time is depicted in Figure 2 below. The performance of a freshly trained AI model resembles closely the performance that is achieved during AI model training. However, as time passes, the observed performance deviates more and more from the expected performance.
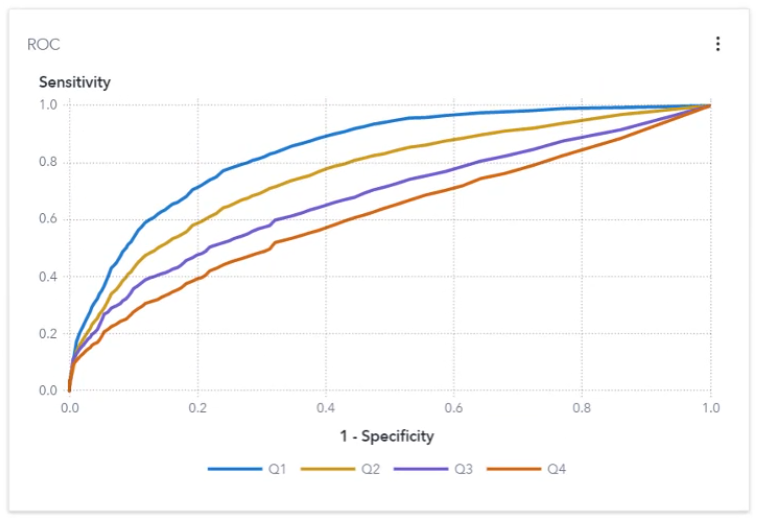
Output: Does the model output (score, predictions) still correspond to the output we targeted in model creation?
From a statistical point of view, most AI models are said to interpolate or generalize the data. In other words, they learn patterns from data. That means that they are trained to make educated guesses on new unseen data that fall within the data values that are used to build the AI model. An AI model trained to recognize animals, will work well when applied to animals, but will fail drastically when applied to humans. When the AI model is applied to new data that fall outside the data values, care should be taken when interpreting the results. Data output deviation graphs can help to assess how representative the output results are compared to the expected output data.
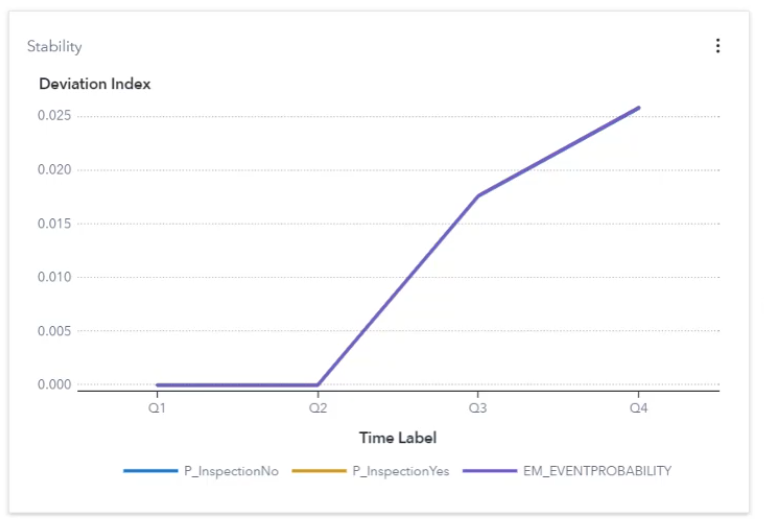
Figure 3: The observed output probabilities of a classification project are compared to the expected output probabilities.
Model usefulness: next-best actions identify steps
The reason why every data scientist should consider the use of SAS Model Manager is that it does not only automatically record performance over time, but ‘next-best actions’ can be automatically coupled with any performance breach that is observed. For example:
- Is the Champion model still performing well? Keep using the Champion model.
- Do we see that a Challenger model is outperforming the Champion model? Let’s automatically switch the current Champion for the better Challenger model.
- Are all models underperforming? Let’s retrain them all and automatically select the new Champion model.
And if none of those governance options can save the quality of your project, let’s inform the data scientists and re-initiate the development cycle in their preferred coding language.
Data scientists out there may get their enjoyment from model development, but that is wasted effort if there is not a means of managing and governing those models when in production. At least SAS Model Manager can do this for you, leaving data scientists to focus on the work they enjoy in the knowledge those efforts will be put to good use.
LEARN MORE | Organize and manage all types of analytic models and pipelines





