This blog post is part one of a series on model validation. The series is co-authored with my colleague Tamara Fischer.
Introduction
Finding the best approach for deploying analytical models into production is definitely not a new challenge. This final step of deployment – or “the last mile” as my colleague James called it in his blog post – has proven to be the most challenging part of the journey for many data scientists, and is often a stumbling stone.
One possible solution to this challenge is to apply the ideas of continuous integration / continuous delivery (CI/CD) to the area of analytical modeling. Since analytical decisions have become more crucial to business processes and deployment continues to be a challenge, it's worth exploring the benefits of these concepts.
A modelops deployment example
Recently, we were asked by a customer to showcase the benefits of integrating SAS model governance into an analytical ecosystem that includes a diverse set of open-source tools and many different scripting languages next to SAS analytics. Specifically, the customer asked us to describe a continuous integration process for operationalizing analytical models in this environment. In this series of posts, we want to share some of our experiences with you.
Before we dive into the details, let me clarify that the term “model validation" is used in a rather narrow sense here to describe an approving process for analytical models before they are accepted for deployment to a production environment. In this case, since the models will be implemented as part of a CI process, it’s essential that this “pipeline” has to be fully automated.
In total, there are four parts to this blog post series that describe this modeling scenario in detail:
- This post will describe some basic principles of the DevOps (or ModelOps) approach.
- The second post discusses the “test pyramid,” which originally is an industry-standard for test design in software engineering. However, we think it's valuable in the area of analytical test design as well.
- The third post is more “hands-on” in nature. It describes how a model validation pipeline can be implemented in real life – using tools like Git, Jenkins – and SAS Model Manager of course.
- Finally, the fourth post addresses a purely analytical topic. While the first three posts are written with a DevOps engineering audience in mind, the fourth post is aimed more at data scientists. It contains a detailed explanation of an algorithm called the feature contribution index (FCI), how it works and how it can be used with SAS. This algorithm has been essential in the project and we hope you will find that the FCI could be a valuable tool in your analytical toolbox too – whether your aim is to set up a “model validation pipeline” or something completely different.
So, let’s get started. Have fun!
Back to the basics: some DevOps principles
Continuous automation is a popular DevOps method for automatically building, testing and validating code every time a change is made from anyone on a development team. This makes model test automation a typical natural integration use case. While continuous integration is often discussed in the context of DevOps, we're applying the method in ModelOps. Of course, the idea of ModelOps did not appear out of thin air. In fact, its core principles go back to the base characteristics of the DevOps approach. The most important of them being automation, test first and API first.
Automation
By automation we’re referring to both deployment automation and test automation. While the latter is in the focus of this blog, deployment automation is a crucial aspect of CI as well. The latest release of SAS Viya brings a strong focus on container technology, which is typically a good answer to the automation challenge, as containers provide a stable runtime environment for analytical models.
The container becomes the deployable unit that is used to safely ship a model through the environments that are commonly seen as enterprise deployment architectures (development, testing, production, etc.). The current version of SAS Model Manager is a prime example of this principle as it leverages container technology for analytical models written in an open source language like Python and R.
Essentially, Model Manager packages together all the needed ingredients before pushing the model container to a Kubernetes cluster: the Python or R kernel, all client required packages, and finally the analytical model as well. (And by the way: you are on the right track if this process reminds you of the source-to-image (s2i) build mechanism in Kubernetes orchestration platforms such as Red Hat OpenShift.)
In this blog post, we're less concerned about the particular deployment technology in use, but clearly containers fit very well into the concept of automated validation. Using container technology, we can make sure that we are validating the exact artifact that will then eventually be pushed to a production environment. The benefits include no version glitches, no side effects and easy to keep under version control as a whole for auditing purposes.
Test first
The test-first paradigm tries to pinpoint the best spot in the lifecycle of software development (or model development in this case) when testing should occur. Test-driven development is a standard today in the field of software engineering. Developers are asked to first write their tests (often known as unit tests) before they start writing the actual production code. The idea here is that you have your unit tests as a safety net in your back from the very beginning on.
Testing becomes a background activity that is continuously executed whenever code changes are detected and, as such, it needs to be as non-obstructive as possible: as long as tests do not fail, developers should not even take notice of them at all. It is easy to see how this requirement relates to the previous point we were talking about: test automation.
So how would this test-first concept translate to the analytical space? Quite easily. In fact, but with minor modifications, since model validation adds a quality perspective to testing. Model testing not only covers simple “pass/no pass” checks but also keeps an eye on, “how well did this model pass?” and "how does this model compare to others?" In other words: the prediction quality of the model is probably the most important validation step we should focus on.
API first
Probably being less popular than the previous one, the “API first” pattern rapidly gains in importance for any non-trivial software and especially proves its worth over time – when changes creep in and software needs to adapt to new requirements. “API first” fosters a modular approach to architecture as it asks developers to first design the public interface of a component before moving on to the implementation. This public interface now becomes a stable “contract” on which other components can rely, unaffected of any changes going on the implementation level over time.
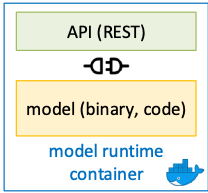
As before, the “API first” paradigm can be found in the area of analytical work as well as the area of DevOps. To give an example: imagine a real-time scoring model that exposes its functionality via a REST-based interface. A web shop system is relying on this service during the checkout stage to make a choice on the payment methods it will allow.
As we know, the prediction quality of analytical models usually degrades over time, so at some point, the scoring model might need to be retrained or even replaced by a different model implementation. In this situation, two requirements become essential: first, the client of the scoring service should not be impacted by the necessary back end changes at the model implementation level (what happens in Vegas, stays in Vegas). Second, the update better not cause any downtime.
Most container orchestration platforms offer a rolling update deployment strategy which will take the latter requirement. When taken seriously, “API First” should ensure that the public interface of the retrained or rewritten model has not changed (so clients can still use it). But there’s more to it when looking ”into” the runtime container. In most cases, the API is actually an “API server” – an active layer in the container acting as the exposed communications endpoint – and it is equally important to check that the updated model still successfully communicates with that API server.
What’s next?
In this blog post, we described how the base characteristics of the DevOps approach – automation, test first and API first – can be adapted to the area of analytical work. In the next post in this blog series, we will take a closer look at the test design topic. Is there a neat way of ordering and separating different categories of tests and how would that look if applied to analytics? Check it out and thanks for reading!
Continue reading post two in this series: Testing in the age of DevOps
Join the virtual SAS Data Science Day to learn more about this method and other advanced data science topics.





