When you go to the grocery store, you see that items of a similar nature are displayed nearby to each other. When you organize the clothes in your closet, you put similar items together (e.g. shirts in one section, pants in another). Every personal organizing tip on the web to save you from your clutter suggests some sort of grouping of similar items together. Even we don't notice it, we are involved in grouping similar objects together in every aspect of our life. This is called clustering in machine learning, so in this post I will provide an overview of data mining clustering methods.
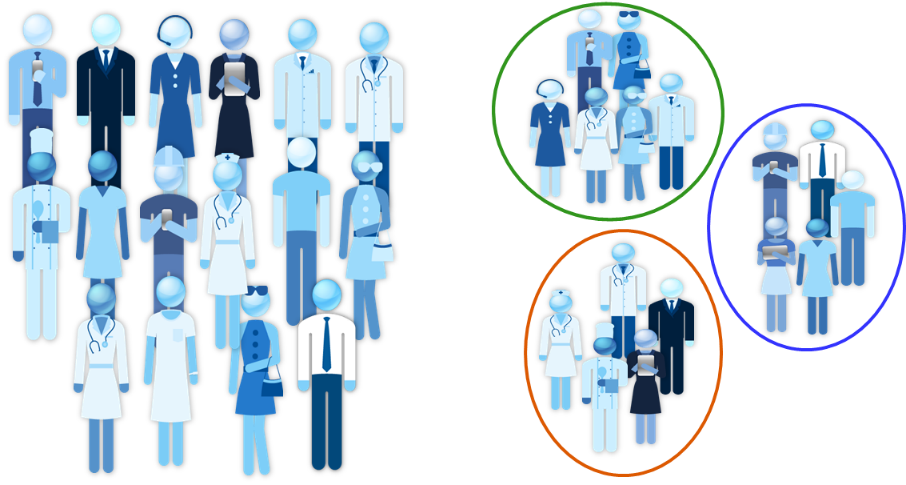
In machine learning or data mining, clustering assigns similar objects together in order to discover structures in data that doesn't have any labels. It is one of the most popular unsupervised machine learning techniques with varied use cases. When you have a huge volume of information and want to turn this information into a manageable stack cluster analysis is a useful approach. It can be used to summarize the data as well as prepare the data for other techniques. For instance, assume you have a large number of images and wish to organize them based on their content. In this case, you first identify the objects in the images and then apply clustering to find meaningful groups. Consider this situation: you have an enormous amount of customer data and want to identify a marketing strategy for your product, as illustrated in figure 1. Again, you could first cluster your customer data into groups that have similar structures and then plan different marketing campaigns for each group.
Defining similarity / dissimilarity is an important part in clustering, because it affects the structure of your groups. You need to change your measure based on the application that you have. One measure may be good for continuous numeric variables but not good for nominal variables. Euclidean distance, the geometric distance in multidimensional space, is one of the most popular distance measures used in distance-based clustering. When the dimension of the data is high, due to the issue called the ‘curse of dimensionality’, the Euclidean distances between any pair of the data loses its validity as a distance metric, because the distances will all be close to each other. In such cases other metrics like the cosine similarity and the Jaccard correlation coefficient are among the most popular alternatives.
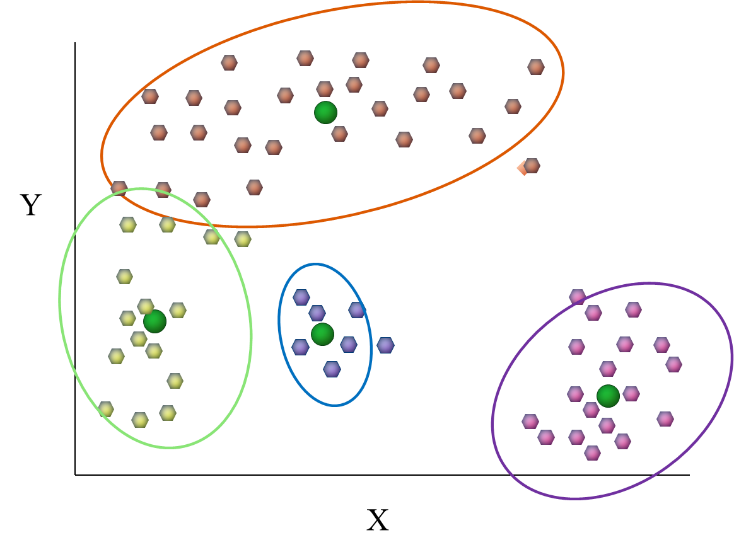
One of the most popular distance-based clustering algorithms is ‘k-means’. K-means is conceptually simpler and computationally relatively faster compared to other clustering algorithms, making k-means one of the most widely used clustering algorithms. While k-means is centroid-based, it is more efficient when the clusters are in globular shapes. Figure 2 shows clustering results yielded by k-means when the clusters in the data are in globular shapes.
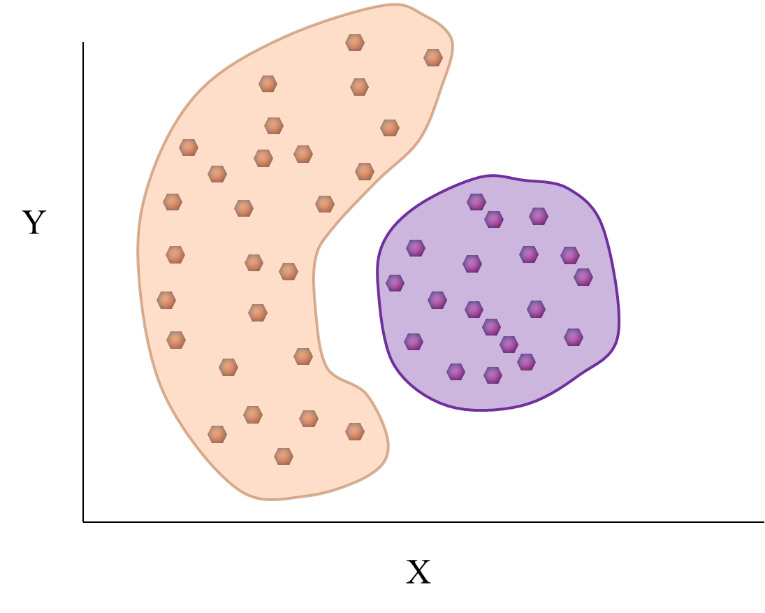
Density-based algorithms can help discover any shaped clusters in the data. In density-based clustering, clusters are areas of higher density than the other parts of the data set. Objects in these sparse areas - which are required to separate clusters - are usually considered to be border points corrupted by noise. The most popular density-based clustering method is DBSCAN. Figure 3 shows the results yielded by DBSCAN on some data with non-globular clusters.
For both the k-means and DBSCAN clustering methods mentioned above, each data point is supposed to be assigned to only one cluster. But consider this kind of situation: when a streaming music vendor tries to categorize its customers into groups for better music recommendations, a customer who likes songs from Reba McEntire may be suitable for the “country music lovers” category. But at the same time, s/he has considerable purchase records for pop music as well, indicating the “pop music lovers” category is also appropriate. Such situations suggest a ‘soft clustering,’ where multiple cluster labels can be associated with a single data point, and each data point is assigned a probability of its association with the various clusters. A Gaussian mixture model with expectation-maximization algorithm (GMM-EM) is a prominent example of probabilistic clusters modeling.
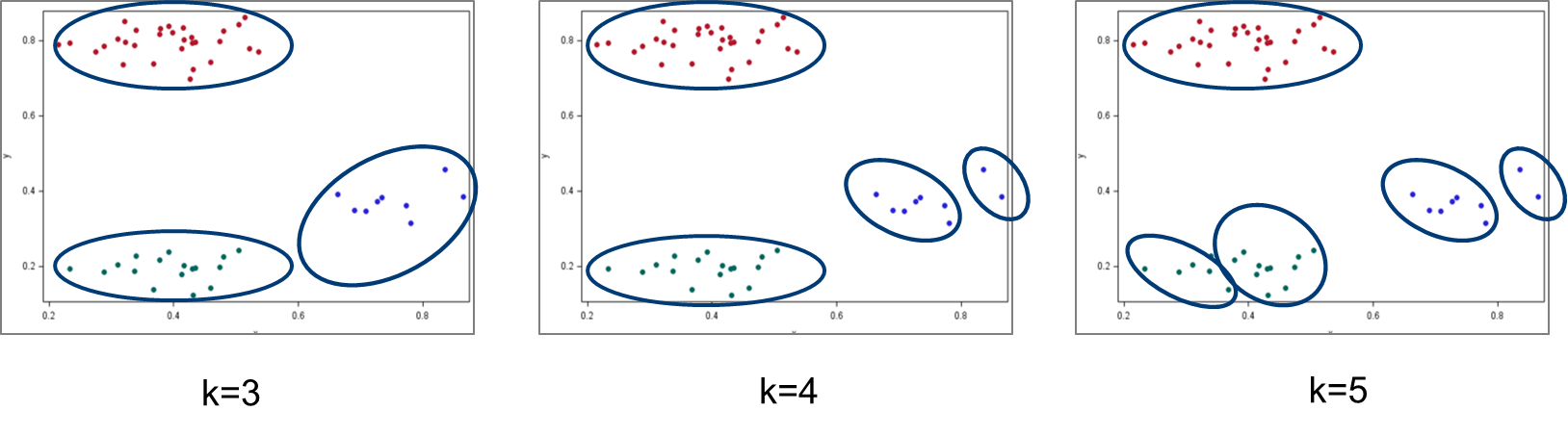
So far, all the clustering methods discussed above involve specifying the number of clusters beforehand, for example, the ‘k’ in the k-means (as shown in figure 4). As a typical unsupervised learning task, the number of clusters is unknown and needs to be learned during the clustering. This is actually why ‘nonparametric methods’ are used in the practice of clustering. A classic application of nonparametric clustering is to replace the probabilistic distribution with some stochastic process in a Gaussian mixture model. The stochastic process can help to discover the number of clusters that yield the highest probability for the data under analysis. In other words, the most suitable number of clusters for the data.
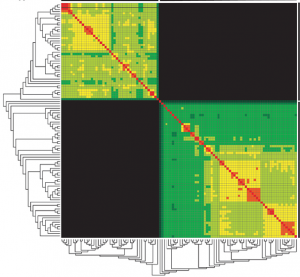
Besides, if you are interested in the internal hierarchy of the clusters in the data, then a hierarchical clustering algorithm can be applied, as shown in figure 5.
There are many different ways to cluster data. Each method tries to cluster the data from the unique perspective of its intended application. As mentioned, clustering discovers patterns in data without explaining why the patterns exist. It is our job to dig into the clusters and interpret them. That is why clusters should be profiled extensively to build their identity, to understand what they represent, and to learn how they are different from each other.
Clustering is a fundamental machine learning practice to explore properties in your data. The overview presented here about data mining clustering methods serves as an introduction, and interested readers may find more information in a webinar I recorded on this topic, Clustering for Machine Learning.
I am grateful to my colleague Yingjian Wang, who provided invaluable assistance to complete this article.
All images courtesy of author but last image, where credit goes to Phylogeny Figures // attribution by creative commons







2 Comments
Understanding data mining clustering methods by Ilknur Kaynar Kabul could be helpful in solving real world problems.
Thank you Ilknur Kaynar Kabul !
Excellent article that provide good technical principles to the business solutions consultants like me.