 Have you heard that SAS offers a collection of new, high-performance CAS procedures that are compatible with a multi-threaded approach? The free e-book Exploring SAS® Viya®: Data Mining and Machine Learning is a great resource to learn more about these procedures and the features of SAS® Visual Data Mining and Machine Learning. Download it today and keep reading for an excerpt from this free e-book!
Have you heard that SAS offers a collection of new, high-performance CAS procedures that are compatible with a multi-threaded approach? The free e-book Exploring SAS® Viya®: Data Mining and Machine Learning is a great resource to learn more about these procedures and the features of SAS® Visual Data Mining and Machine Learning. Download it today and keep reading for an excerpt from this free e-book!
In SAS Studio, you can access tasks that help automate your programming so that you do not have to manually write your code. However, there are three options for manually writing your programs in SAS® Viya®:
- SAS Studio provides a SAS programming environment for developing and submitting programs to the server.
- Batch submission is also still an option.
- Open-source languages such as Python, Lua, and Java can submit code to the CAS server.
In this blog post, you will learn the syntax for two of the new, advanced data mining and machine learning procedures: PROC TEXTMINE and PROCTMSCORE.
Overview
The TEXTMINE and TMSCORE procedures integrate the functionalities from both natural language processing and statistical analysis to provide essential functionalities for text mining. The procedures support essential natural language processing (NLP) features such as tokenizing, stemming, part-of-speech tagging, entity recognition, customized stop list, and so on. They also support dimensionality reduction and topic discovery through Singular Value Decomposition.
In this example, you will learn about some of the essential functionalities of PROC TEXTMINE and PROC TMSCORE by using a text data set containing 1,830 Amazon reviews of electronic gaming systems. The data set is named Amazon. You can find similar data sets of Amazon reviews at http://jmcauley.ucsd.edu/data/amazon/.
PROC TEXTMINE
The Amazon data set has already been loaded into CAS. The review content is stored in the variable ReviewBody, and we generate a unique review ID for each review. In the proc call shown in Program 1 we ask PROC TEXTMINE to do three tasks:
- parse the documents in table reviews and generate the term by document matrix
- perform dimensionality reduction via Singular Value Decomposition
- perform topic discovery based on Singular Value Decomposition results
Program 1: PROC TEXTMINE
data mycaslib.amazon; set mylib.amazon; run; data mycaslib.engstop; set mylib.engstop; run; proc textmine data=mycaslib.amazon; doc_id id; var reviewbody; /*(1)*/ parse reducef=2 entities=std stoplist=mycaslib.engstop outterms=mycaslib.terms outparent=mycaslib.parent outconfig=mycaslib.config; /*(2)*/ svd k=10 svdu=mycaslib.svdu outdocpro=mycaslib.docpro outtopics=mycaslib.topics; run;
(1) The first task (parsing) is specified in the PARSE statement. Parameter “reducef” specifies the minimum number of times a term needs to appear in the text to be included in the analysis. Parameter “stop” specifies a list of terms to be excluded from the analysis, such as “the”, “this”, and “that”. Outparent is the output table that stores the term by document matrix, and Outterms is the output table that stores the information of terms that are included in the term by document matrix. Outconfig is the output table that stores configuration information for future scoring.
(2) Tasks 2 and 3 (dimensionality reduction and topic discovery) are specified in the SVD statement. Parameter K specifies the desired number of dimensions and number of topics. Parameter SVDU is the output table that stores the U matrix from SVD calculations, which is needed in future scoring. Parameter OutDocPro is the output table that stores the new matrix with reduced dimensions. Parameter OutTopics specifies the output table that stores the topics discovered.
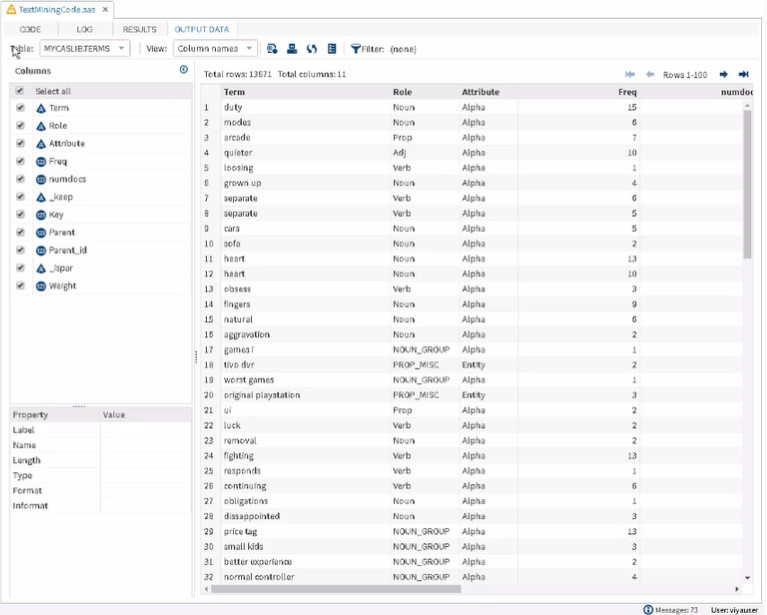
Click the Run shortcut button or press F3 to run Program 1. The terms table shown in Output 1 stores the tagging, stemming, and entity recognition results. It also stores the number of times each term appears in the text data.
Output 1: Results from Program 1
PROC TMSCORE
PROC TEXTMINE is used with large training data sets. When you have new documents coming in, you do not need to re-run all the parsing and SVD computations with PROC TEXTMINE. Instead, you can use PROC TMSCORE to score new text data. The scoring procedure parses the new document(s) and projects the text data into the same dimensions using the SVD weights derived from the original training data.
In order to use PROC TMSCORE to generate results consistent with PROC TEXTMINE, you need to provide the following tables generated by PROC TEXTMINE:
- SVDU table – provides the required information for projection into the same dimensions.
- Config table – provides parameter values for parsing.
- Terms table – provides the terms that should be included in the analysis.
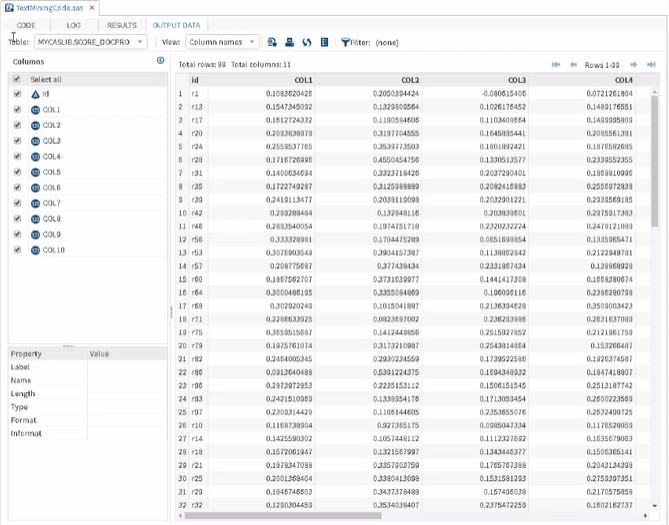
Program 2 shows an example of TMSCORE. It uses the same input data layout used for PROC TEXTMINE code, so it will generate the same docpro and parent output tables, as shown in Output 2.
Program 2: PROC TMSCORE
Proc tmscore data=mycaslib.amazon svdu=mycaslib.svdu config=mycaslib.config terms=mycaslib.terms svddocpro=mycaslib.score_docpro outparent=mycaslib.score_parent; var reviewbody; doc_id id; run;
Output 2: Results from Program 2
To learn more about advanced data mining and machine learning procedures available in SAS Viya, including PROC FACTMAC, PROC TEXTMINE, and PROC NETWORK, you can download the free e-book, Exploring SAS® Viya®: Data Mining and Machine Learning. Exploring SAS® Viya® is a series of e-books that are based on content from SAS® Viya® Enablement, a free course available from SAS Education. You can follow along with examples in real time by watching the videos.
