Im Gastbeitrag beschreibt Deloitte, wann, wie und warum Unternehmen Data Science benötigen.
In den letzten Jahren haben sich analytische Modelle zur Echtzeitentscheidung in vielen Branchen etabliert. So bieten Airlines bspw. im Zuge ihrer Customer Journey individualisierte Angebote. Selbiges gilt auch für den Onlinehandel. Da es sich bei Data Science um eine junge Disziplin mit neuen Werkzeugen handelt, haben Unternehmen in jüngerer Vergangenheit erste Erfahrungen mit Methoden, Technologien und Werkzeugen gesammelt. Der Schwerpunkt lag hier auf schnellem Nutzen und produktivem Einsatz. Wartung, Weiterentwicklung und Integration mit anderen Systemen und Schnittstellen standen dabei nicht im Fokus.
In klassischen Data- & Analytics-Architekturen haben sich eine hohe Automatisierung sowie modulare und entkoppelte Programme bereits als Erfolgsfaktor erwiesen. Kern sind hier industrialisierte Infrastrukturen, die eine schnelle, revisionssichere Produktivsetzung und Weiterentwicklung ermöglichen. Im Zuge unserer Beratungsprojekte bei deutschen Unternehmen aus unterschiedlichen Branchen hat sich gezeigt, dass von den Unternehmen zunehmend auch im Bereich der Data Science eine Industrialisierung angestrebt wird. Spätestens, wenn eine Vielzahl an Modellen mit hart codierten Parametern und Look-ups in Produktion ist, wird es Zeit, auf eine industrialisierte Data Science zu wechseln.
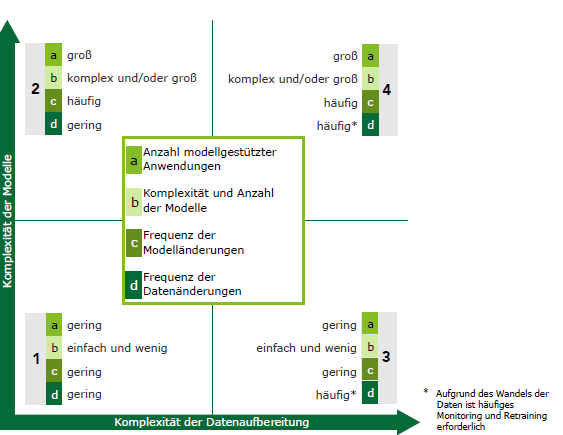
Doch wann ist eine industrialisierte Data Science erforderlich?
Zur Einordnung kann als Dimension die Komplexität der Modelle und deren Änderungshäufigkeit herangezogen werden. Da analytische Modelle aber immer eng mit den zugrunde liegenden Daten verbunden sind, stellt die Komplexität der Datenaufbereitung eine weitere Ebene dar. Dieser Sachverhalt ist in Abbildung 1 dargestellt. Klassischerweise bietet sich eine automatisierte Data Science für Anwendungen mit hoher Komplexität auf Daten- und Modellebene an (Abbildung 1, Nr. 4). Aber auch für Anwendungen, bei denen nur eine Dimension betroffen ist, kann industrialisierte Data Science eine Lösung darstellen (Abbildung 1, Nr. 2 und 3).
Und wie kann die dazugehörige Architektur aussehen?
Essenziell sind in diesem Fall zentrale Repositories zur Ablage von Meta-Informationen über Daten, Regeln und Modelle. Nur durch diese können automatische und revisionssichere Deployments, Roll-back-Mechanismen und letztlich eine agile Arbeitsweise inklusive DevOps ermöglicht werden. Abbildung 2 zeigt ein analytisches Ökosystem mit zentralen Repositories.
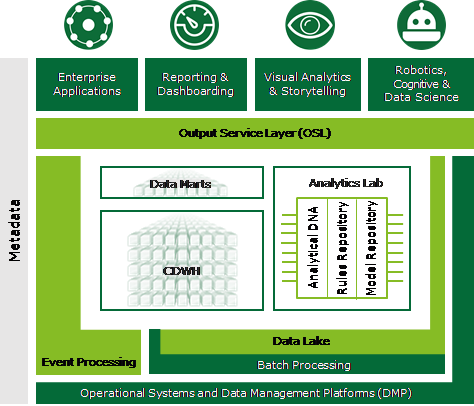
Viele Unternehmen haben bereits im Zuge der klassischen Business Intelligence (BI) Architekturen mit ähnlichen Designgrundsätzen aufgebaut. Z. T. sind hier bereits Aktuare bzw. Data Scientists eingebunden. Die hier angewendeten Methoden, Prinzipien und Designvorlagen können auch für Data Science verwendet werden. Essenziell ist es, die Best Practices der Softwareentwicklung wie Modularisierung oder Entkopplung beim Entwurf der technischen Architektur und der zugehörigen Organisationsstrukturen zu beachten.
Weitere Informationen finden Sie auch im E-Book des TDWI zu Data Science.
Wollen Sie Ihre Data Science technologisch und organisatorisch auf die nächste Ebene bringen? Dann wenden Sie sich an uns.
Sie finden uns auch auf dem SAS Forum Deutschland am 20./21. Juni 2018 in Bonn.
Kontakt:
Dr. Michael Zimmer
mizimmer@deloitte.de
Stefanie Kampmann
stkampmann@deloitte.de
Dr. Andreas Becks
andreas.becks@sas.com