In part one of this blog series, we introduced the automation of AI (i.e., artificial intelligence) as a multifaceted and evolving topic for marketing and segmentation. After a discussion on maximizing the potential of a brand's first-party data, a machine learning method incorporating natural language explanations was provided in the context of discovering insight.
In part two of this series, we'll continue exploring practitioner-oriented examples that illustrate the value of automated AI in SAS Customer Intelligence 360.
How else can we exploit automated AI in defining actionable segments?
A powerful feature in SAS is the ability to increase analysis sophistication. Two examples I will highlight building from our previous effort will be:
- Switching the underlying algorithm of the analysis.
- Leveraging model auto tuning (or hyperparameters).
To begin, I open a menu to duplicate my automated analysis to any of the listed techniques.
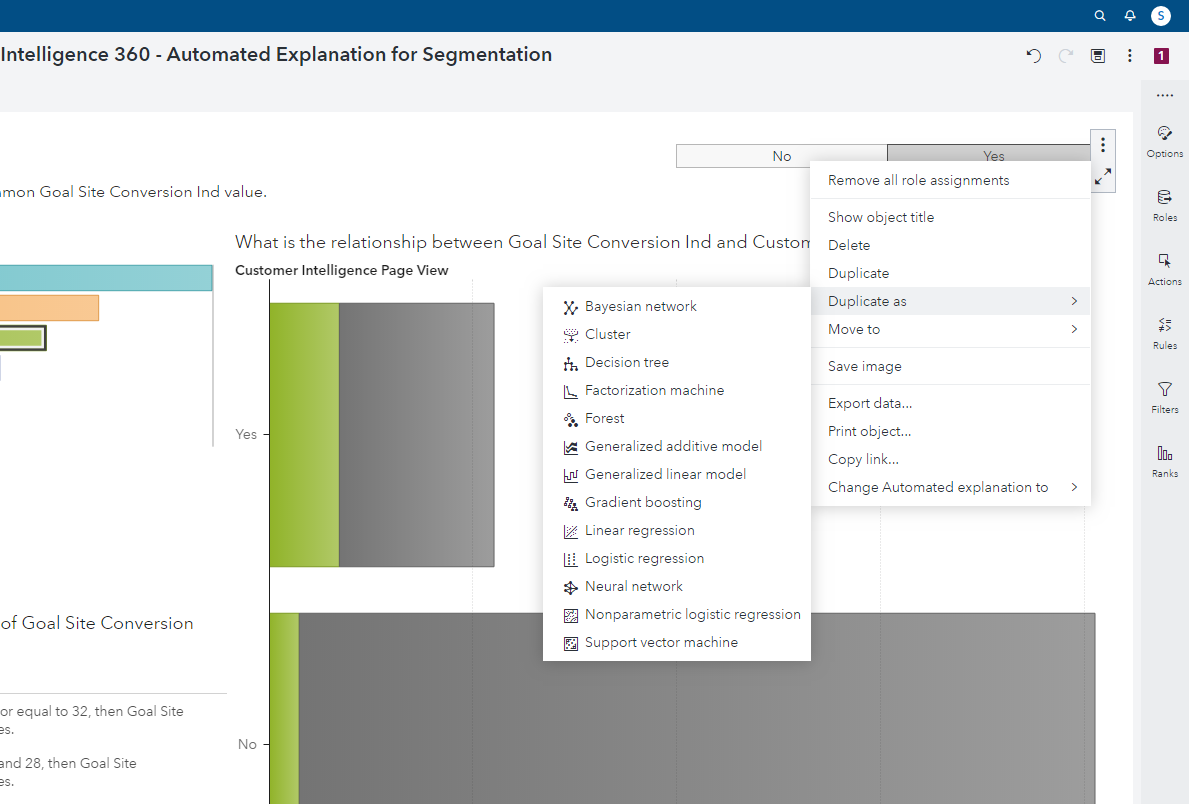
Although I can select any method, I will use a decision tree to show how an analyst can further optimize the effectiveness of their work. For readers interested in other machine learning techniques, like forests, gradient boosting, or neural networks for classification use cases, check this out. If you're curious to learn more about factorization machines for recommendation systems, go here.
After selecting decision tree, the analyst can visually assess the diagnostic metrics, but also has an opportunity to improve the segmentation. I’ll begin by reviewing the initial results.
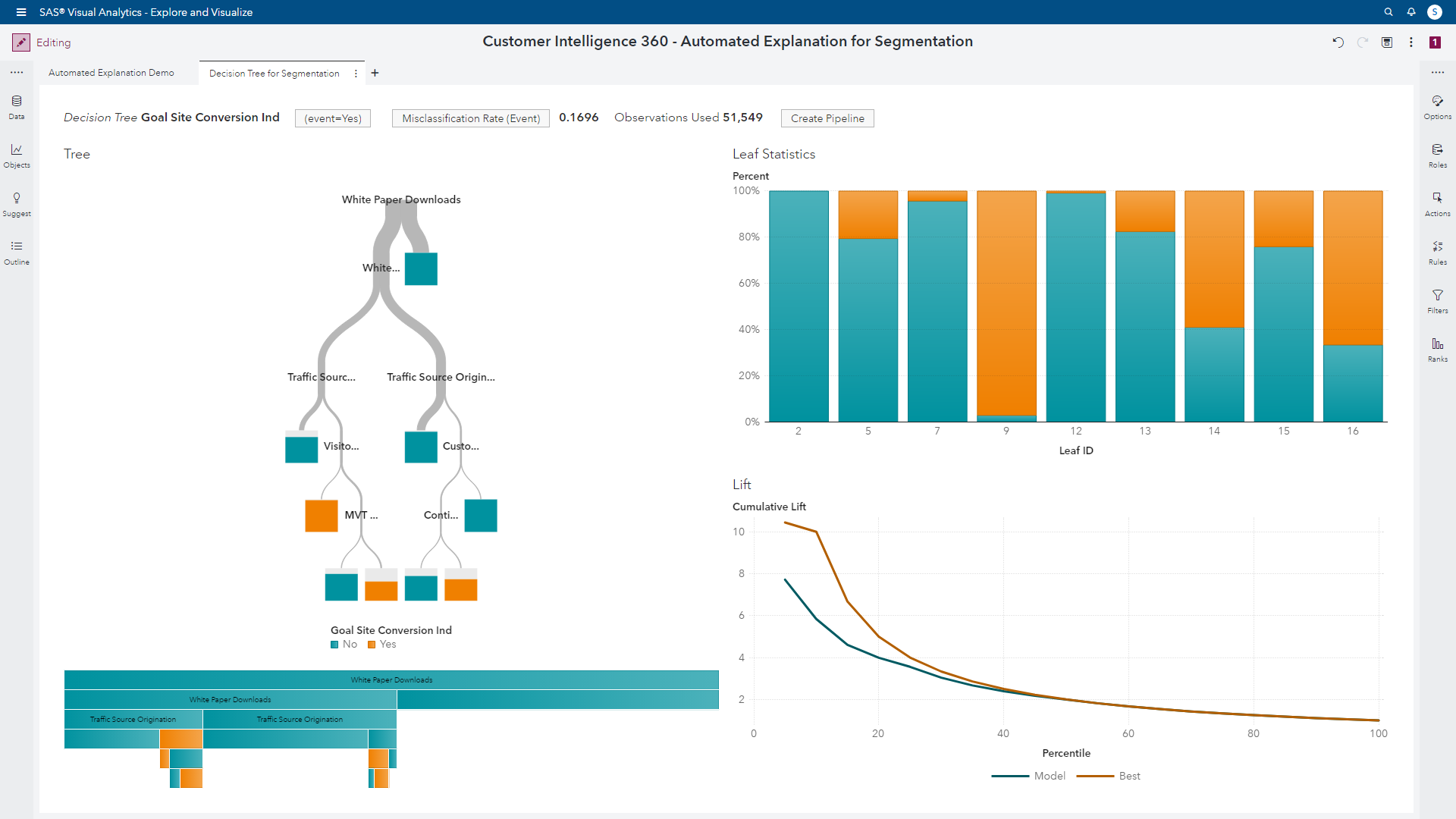
In short, this output highlights nine segments with varying propensities to convert (or not convert) based on our Goal Site Conversion Ind target metric. By enlarging the segment leaf plot, an analyst can view which segments have attractive signals. The bars with larger proportions of orange color represent audiences with higher conversion propensities.
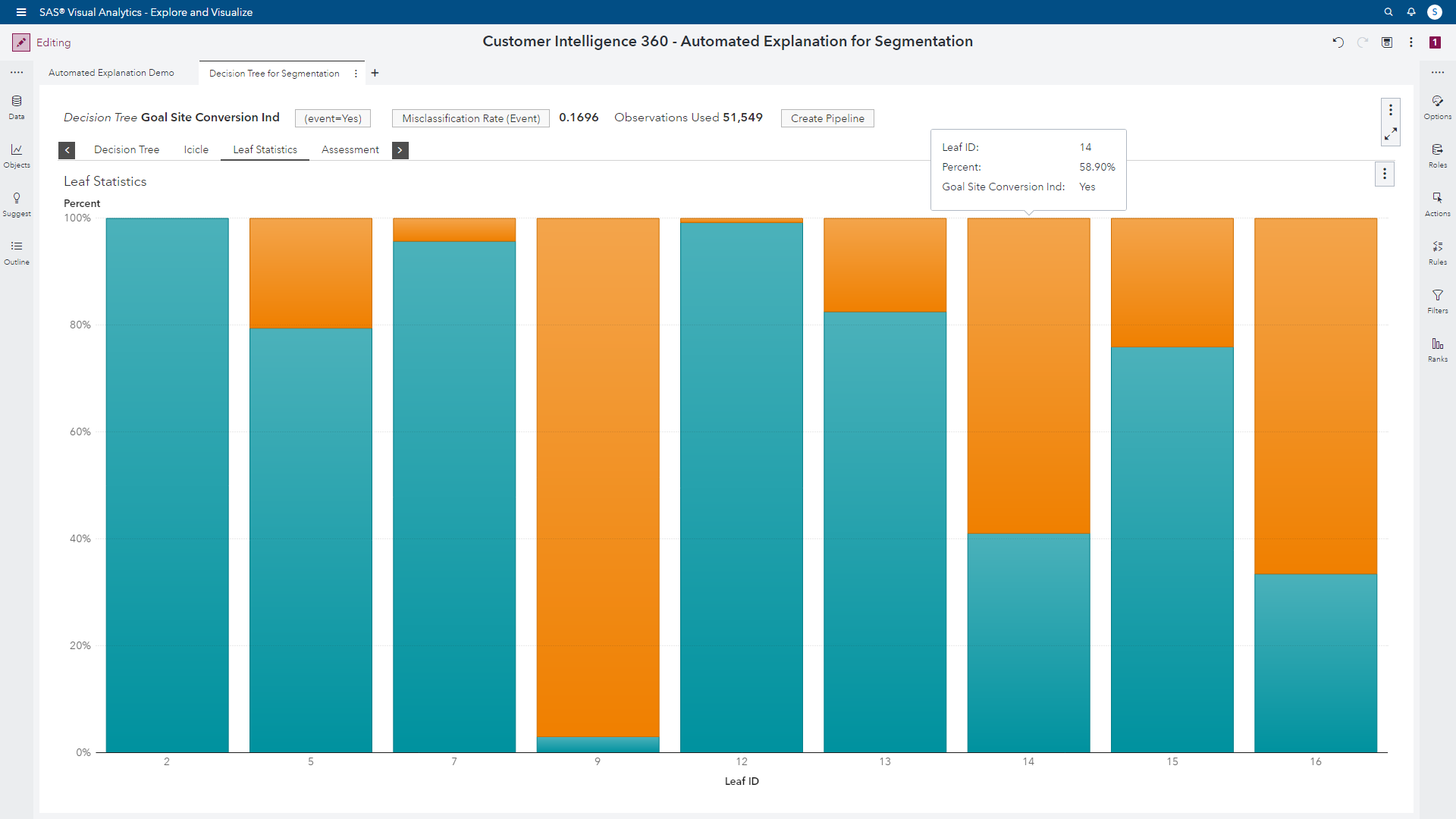
If an analyst selects a specific segment, the tree map interactively provides more context of the audience.
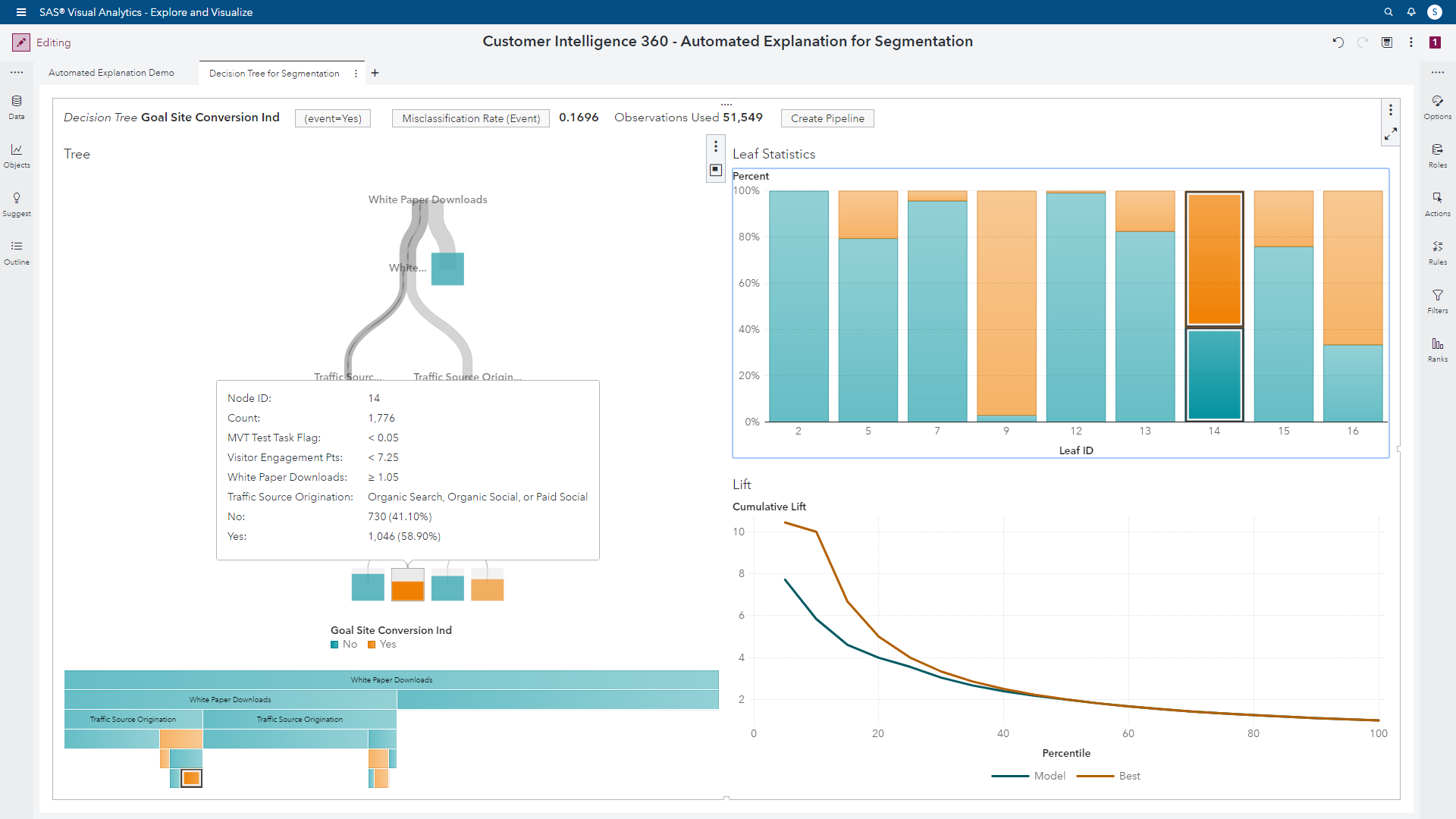
Analysts also desire stability in their work, and analytical model partitioning is turned on in a snap. This helps ensure the segmentation results will perform similarly on scoring new audiences.
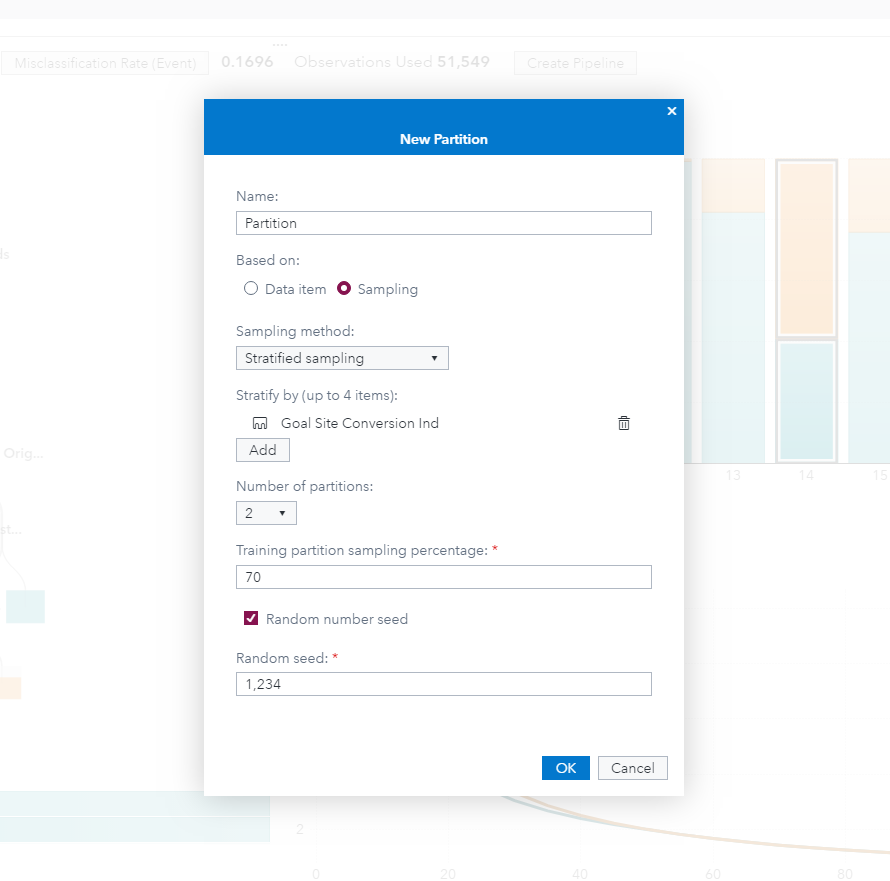
A new challenge will inevitably present itself. The tree’s diagnostic metric of misclassification rate will haunt the analyst, and their efficiency to deliver results. In our current example, we have an error rate of approximately 17%. The analyst delivering this segmentation for use in campaign management processes will naturally want to improve the accuracy of the predictions. However, this can become a time-consuming exercise of manual iterations tinkering with the analysis and delaying the delivery of the results.

Once again, we can do better with automation.
To create a good segmentation model, many choices have to be made when deciding on algorithms and their parameters. The usual approach is to apply trial-and-error methods to find the optimal algorithms for the problem at hand. Often, an analyst will choose algorithms based on practical experience and personal preferences. This is reasonable, because usually there is no unique solution to create a machine learning model. Many algorithms have been developed to automate manual and tedious steps of the analytical process. Still, it requires a lot of time and effort to build a machine learning model with trustworthy results.
A large portion of this manual work relates to finding the optimal set of hyperparameters for a chosen modeling algorithm (in our use case, the decision tree). Hyperparameters are the properties that define the model applied to a data set for automated information extraction.
In our example, an analyst must make many decisions during the training process. A large portion of the segmentation model building process is taken up by experiments to identify the optimal set of parameters for the algorithm. As algorithms get more complex (single-layer to multi-layer neural networks, decision trees to forests and gradient boosting), the amount of time required to identify these parameters grows.
There are several ways to support analysts in the cumbersome work of tuning model parameters. These approaches are called hyperparameter optimization, or auto tuning. Not only do ideal settings for the hyperparameters dictate the performance of the model’s training process, but more importantly they govern the quality of the resulting segmentation model.
Watch this.
In a single click, an analyst can trigger the auto tuning optimization, and automate the removal of countless attempts to improve the segmentation analysis.
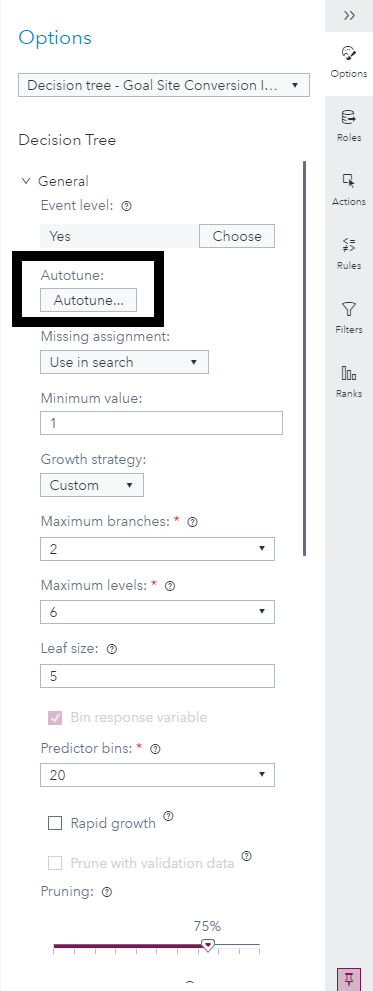
In general, there are three different types of auto tuning methods: parameter sweep, random search, and parameter optimization.
- Parameter sweep: This is an exhaustive search through a predefined set of parameter values. The analyst selects the candidates of values for each parameter to tune; trains a model with each possible combination; and selects the best-performing model. Here, the outcome very much depends on the experience and selection of the analyst.
- Random search: This is a search through a set of randomly selected sets of values for the model parameters. With modern computers, this can provide a less biased approach to finding an optimal set of parameters for the selected model. Since this is a random search, it is possible to miss the optimal set unless a sufficient number of experiments are conducted, which can be computationally expensive.
- Parameter optimization: This is the approach that applies modern optimization techniques to find the optimal solution. It's the best way to find the most appropriate set of parameters for any predictive model, and any business problem, in the least expensive way.
SAS provides analysts a hybrid, derivative-free optimization framework that operates in a parallel and distributed computing environment to overcome the challenges and computational expense of hyperparameter optimization. It consists of an extendable suite of search methods.
The result of clicking the auto tune button has a formidable impact on our segmentation analysis. The misclassification rate decreases from 17% to approximately 9%. That’s an 8% increase in predictive accuracy based on the validation partition of the input data. In other words, more accuracy will translate to improved conversion rates downstream.
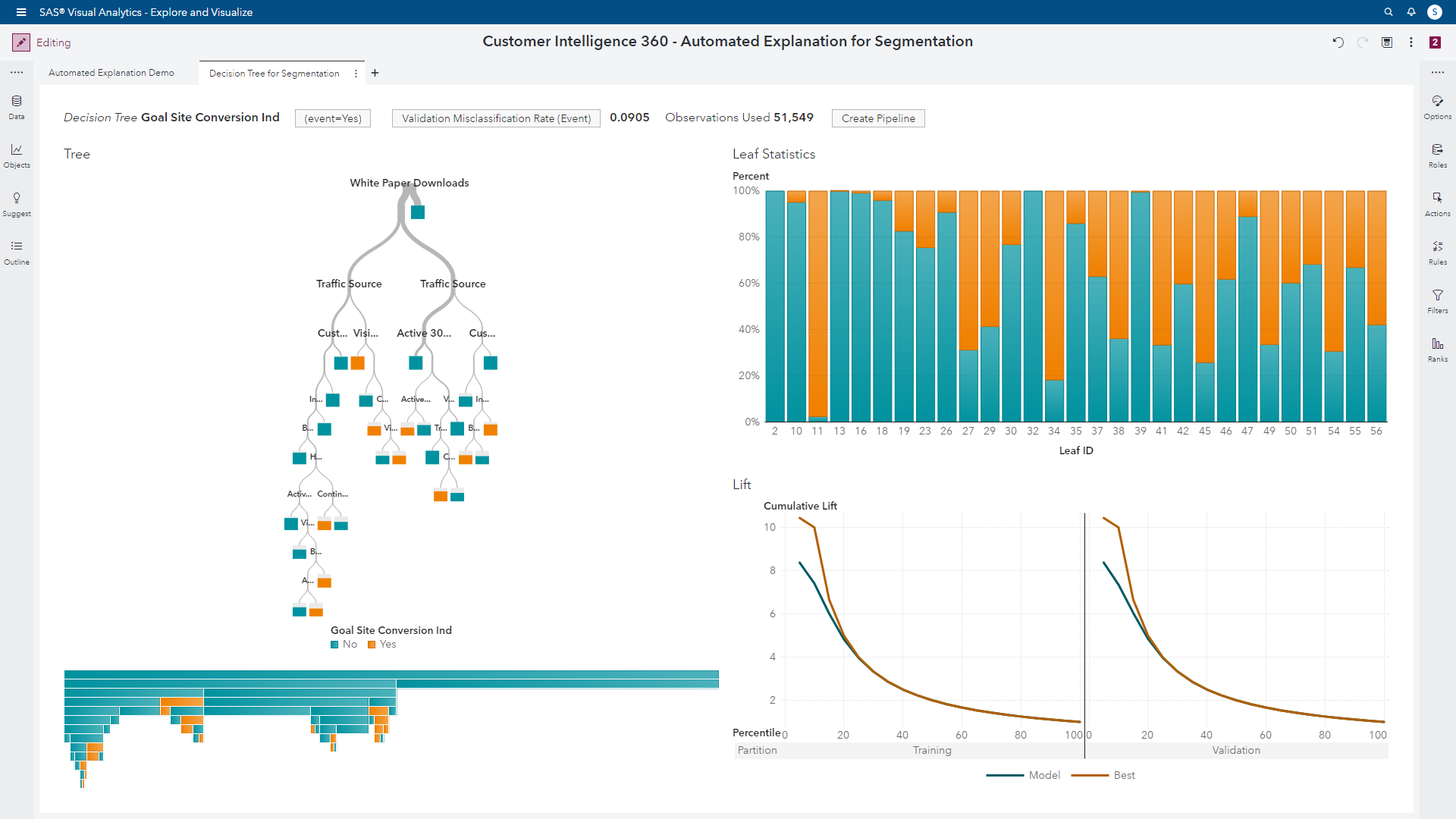
Incremental lift was derived from audience deciles, as well as the identification of more attractive segments. The auto tuning actually helped the tree create thirty segments in total. Before leveraging this feature, our previous iteration of the tree analysis identified three segments with high value propensities to convert. Now we have ten segments with favorable behaviors available for audience targeting.
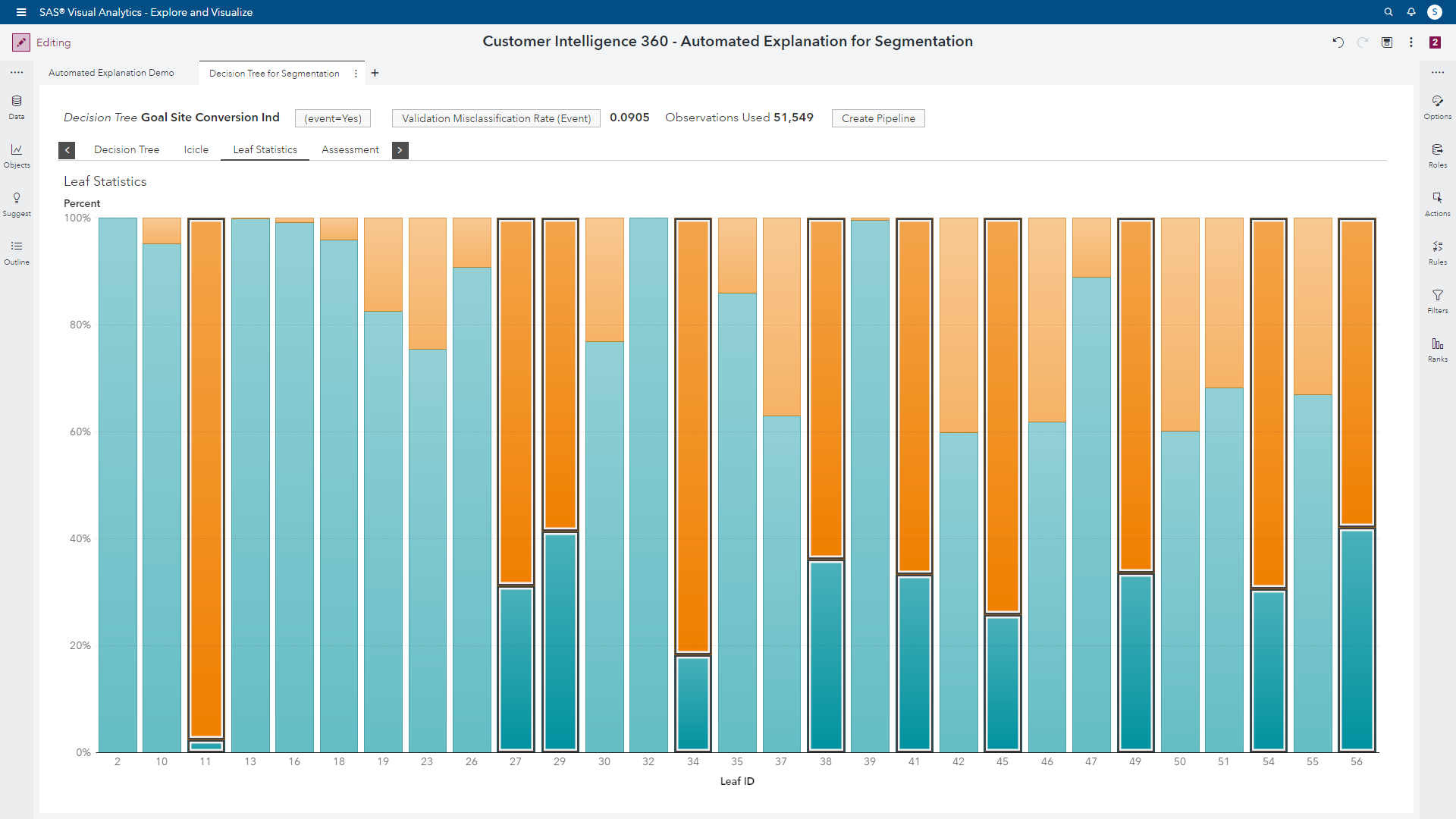
Analysts reading this who do not have access to auto tuning in their current analytical environments will appreciate the hours and days that could be saved to reach this ideal outcome.
Takeaways
In this article, we addressed and made cases for:
- Accelerators for improving segmentation accuracy.
- Automated AI in the context of model auto tuning (or hyperparameters).
In part three of this blog series, we'll conclude by focusing on the deployment (or taking action) on targetable segments within SAS Customer Intelligence 360's multi-channel content delivery mechanisms.

1 Comment
Pingback: SAS Customer Intelligence 360: Automated AI and segmentation [Part 3] - Customer Intelligence Blog