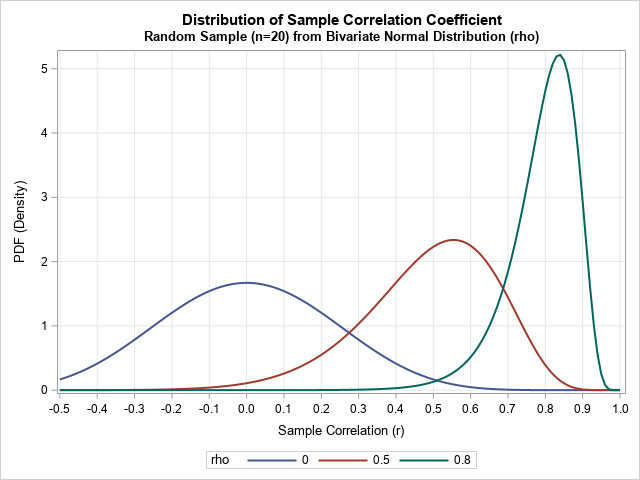
An exact formula for the sampling distribution of the correlation coefficient

I read a journal article in which a researcher used a formula for the probability density function (PDF) of the sample correlation coefficient. The formula was rather complicated, and presented with no citation, so I was curious to learn more. I found the distribution for the correlation coefficient in the