Latin hypercube sampling in SAS

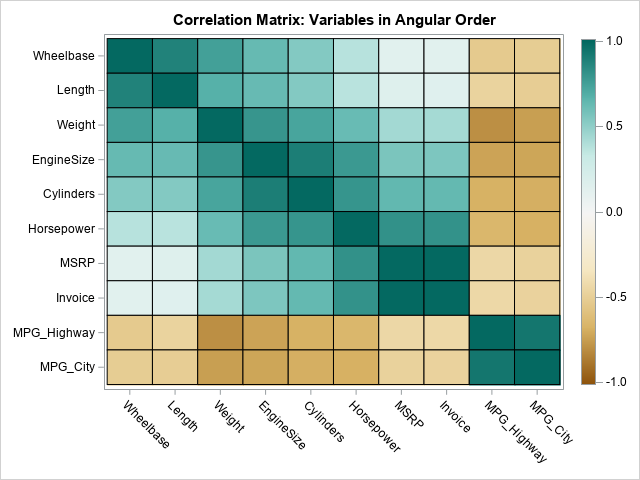
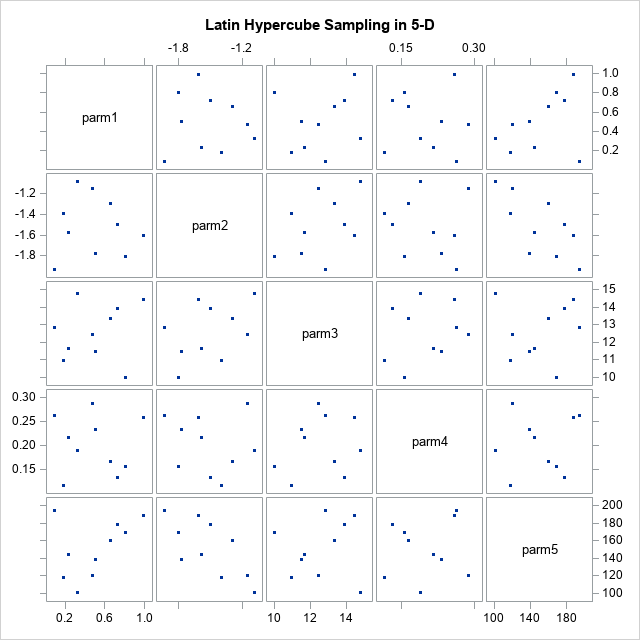
While researching the topic of Latin hypercube sampling (LHS), I read an article by Emily Gao (2019) that shows how to use PROC IML in SAS to perform the algorithm. It is possible to simplify Gao's implementation of Latin hypercube sampling in SAS while also making the computation more efficient.