Editor's Note: This article follows Natural Language processing techniques that improve data quality with LLMs and Toxicity, bias, and bad actors: three things to think about when using LLMs.
We often hear about cyberattacks, hackers, ransomware, and other nefarious deeds in the news, but not all data breaches are caused by third parties. In 2023, the Identity Theft Resource Center reported a total of 3,205 breaches with over 350M victims. System and human errors accounted for over 700 of these breaches with nearly 7M victims.
Exploring LLM-related data breaches
Most organizations allocate considerable time, money, and resources to prevent data breaches; from training employees on how to properly store and protect company data to constant network monitoring. Large language models (LLMs) add a new variable to the equation.
In a previous article, I touched on natural language processing (NLP) techniques that can be used to improve data quality in unstructured data. I mentioned that exposing LLMs to domain-related text data isn’t always the most effective option because of possible duplication, ambiguity, and noise. Furthermore, it is important to make sure that data inputted into LLMs doesn’t contain personally identifiable or otherwise sensitive information. If sensitive data makes its way into the model, bad actors could use prompt attacks to influence the model to reveal sensitive data it has seen or has access to. Once LLMs have seen sensitive data, it is difficult to get them to remove or delete it without going back to a baseline and going through the fine-tuning process again. The same modeling techniques used to manage noise can also be used to detect private or sensitive data in training data so it can be redacted or the records containing it excluded from fine-tuning.
Identifying organizational risks
Keeping private and sensitive information out of LLMs when preparing them for domain use in an organization is one piece of the puzzle, but there’s another aspect that many fail to consider—users who make bad decisions and inadvertently put their organizations at risk.
A senior executive at a large organization was telling me about some of the ways his department was experimenting with free versions of publicly available LLMs and the amazing insights they were gleaning. He explained that they were trying to better understand customer satisfaction using their call center customer narratives and were copying and pasting narrative information into their prompts. That raised a red flag for me.
I asked if the narratives contained any personally identifiable information, and he confirmed that some of them contained names, address information, and occasionally account information. I then asked him if he’d read the terms of service for the models they were experimenting with. He asked why, and I mentioned that some models use prompt information for further training. He went silent for a minute, then asked how he could get that information back out of the model if it had been exposed, and I explained that he likely couldn’t. Even if the LLM were hosted internally, copying and pasting information containing potentially sensitive information and using it in prompts would likely still be a violation of security protocols.
Understanding LLM terms of service
There are so many models available, and people introduce data into them all the time—whether it’s a content marketer trying to get help writing marketing copy that has a certain voice, a student copying and pasting reading passages asking for help with a homework assignment, or someone trying to glean insights from customer narratives. I speak to many people about LLMs, both as a product manager and in my teaching role at Duke University, and the lack of understanding that, depending on the model, prompts can be retained and used for further training is pervasive. It’s important to understand how the models you choose use information from your prompts.
Because people may unknowingly violate security protocols when prompting LLMs, it is possible to take the same type of linguistic model that would be used to identify and redact sensitive information before fine-tuning and deploy it between a prompt and an LLM. The linguistic model could then intercept prompts that contain PII or sensitive data and prevent it from being introduced into the LLM. This provides an added layer of security, and because linguistic models run so efficiently, the scanning and intercept can be done without a significant impact on performance.
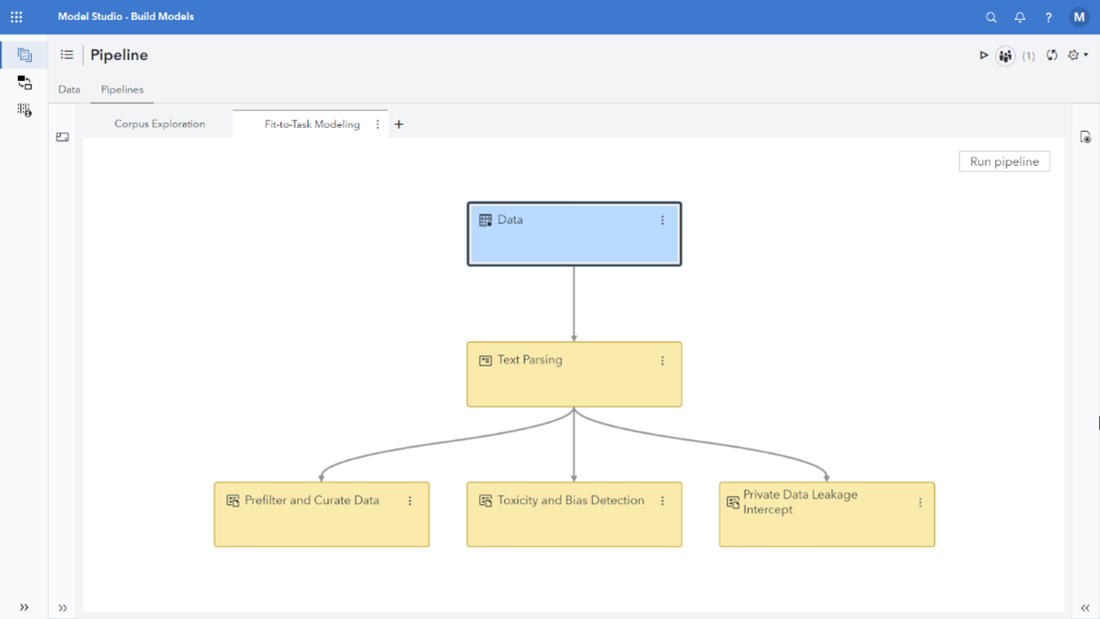
Reducing risk requires accountability
As the adoption of LLMs continues to grow, so does the risk of unintentionally exposing sensitive data through careless prompting. The examples I've shared underscore the need for organizations to be vigilant about how they interact with these powerful tools, but awareness is only the first step.
Preventing private and sensitive data leakage isn’t just the responsibility of the IT department. It’s a shared responsibility across entire organizations. Educating teams on potential risks, rigorously vetting the LLMs you choose, and integrating linguistic models as another layer to intercept or redact sensitive information before it reaches the LLM can help reduce risks. By staying informed and proactive, you can leverage the benefits of LLMs while safeguarding some of your organization's most valuable assets—your data and your reputation.

{kind=link}